오늘은 이전에 포스팅했었던 “INSTRUCTION PRE-TRAINING: LANGUAGE MODELS ARE SUPERVISED MULTITASK LEARNERS“의 이전 연구인 “ADAPTING LARGE LANGUAGE MODELS TO DOMAINS VIA READING COMPREHENSION”를 살펴보겠다.
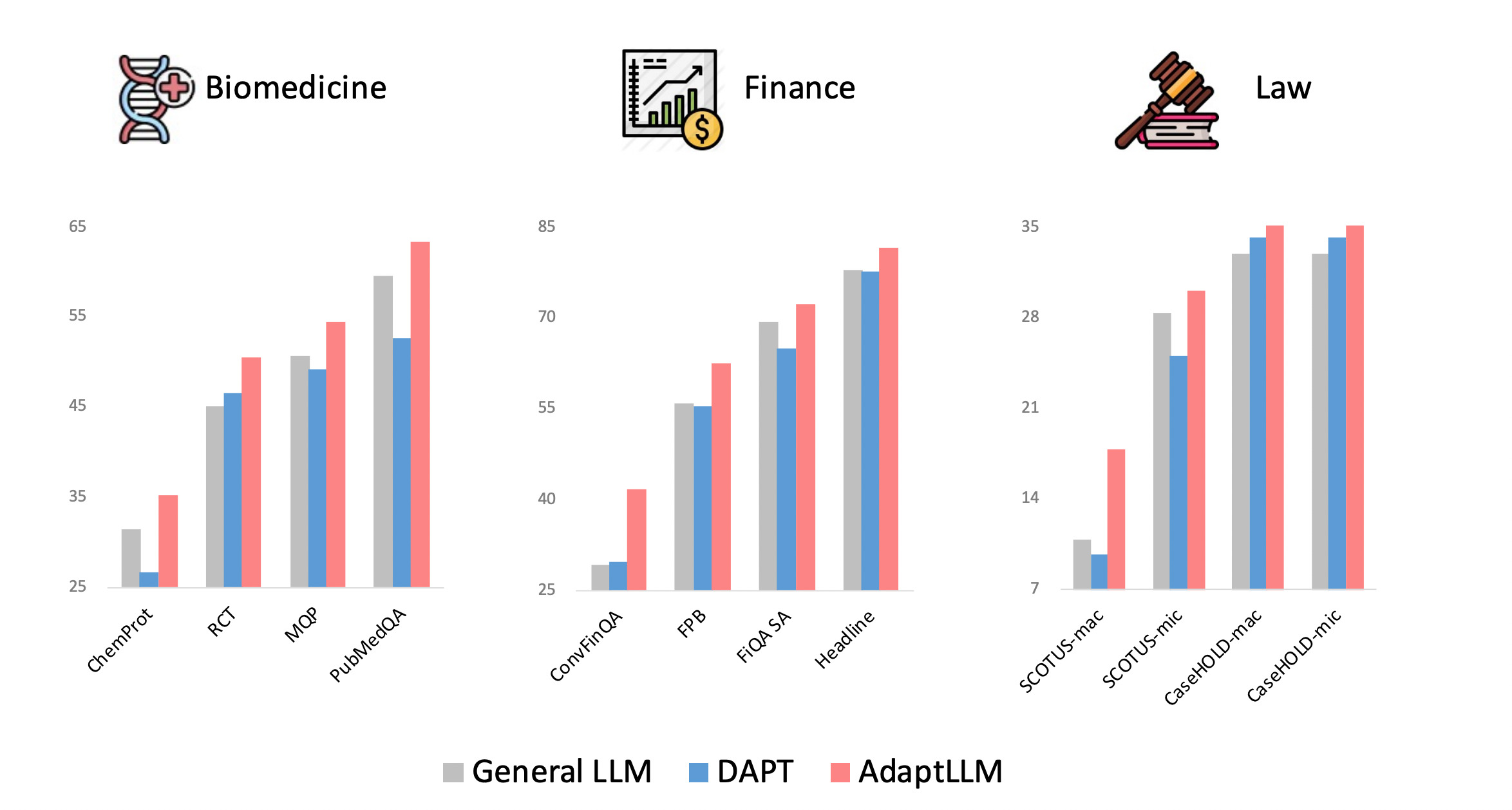
그림 1. Domain-Specific 태스크 성능
그림 1은 각 사전학습 방법별 특정 도메인에 특화된 태스크에서의 성능을 나타낸다. DAPT는 도메인에 특화된 원시 말뭉치에 Continued Pretraining을 적용한 모델이며, AdaptLLM은 해당 논문에서 제안하는 방법을 통해 사전학습된 모델의 성능을 나타낸다.
우선, DAPT의 성능을 살펴보면, General LLM보다 오히려 성능이 떨어지는 태스크들이 다수 존재한다. 논문에서는 해당 원인을 분석했는데, DAPT를 적용하면서 도메인에 특화된 지식들을 학습하면서 도메인에 특화된 태스크를 더 잘 수행할 수 있다. 하지만 동시에 DAPT가 학습된 LLM의 Prompt Ability를 헤치게 되면서 오히려 성능이 더 떨어지는 태스크들이 발생하게 되는 것이다.
이에, 제안된 AdaptLLM은 도메인에 특화된 원시 말뭉치를 가지고 추가적인 사전학습을 진행하되, General LLM이 기존에 가지고 있던 Prompt Ability를 최대한 보존하는 형태의 사전학습 방법이다.
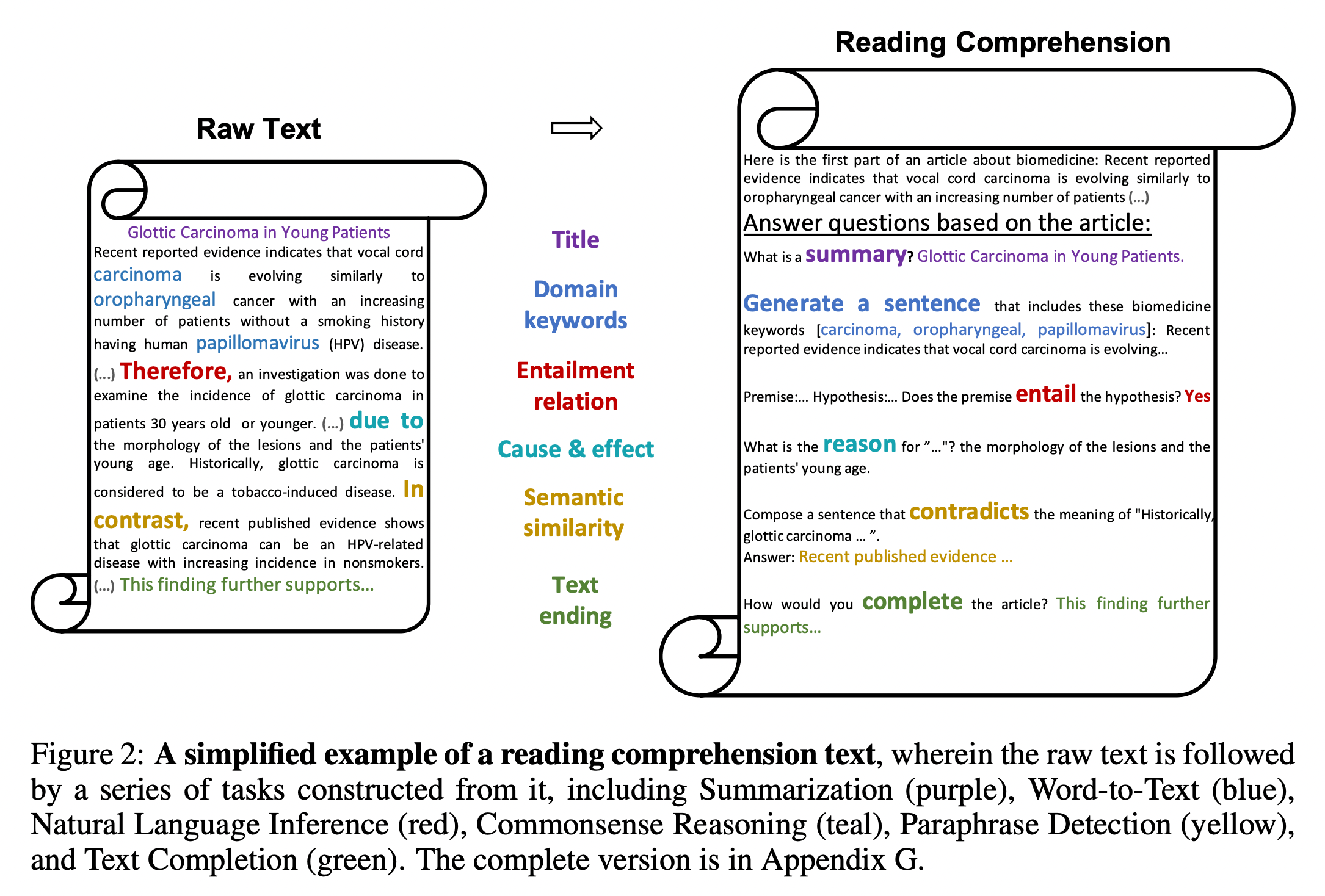
그림 2. Reading Comprehension Text 예시
앞서 언급했던 문제를 최소화하기 위해서, 해당 논문에서는 도메인에 특화된 원시 말뭉치를 바로 Continued Pretraining에 적용하는 대신, 해당 원시 말뭉치들을 Reading Comprehension 데이터의 형태로 바꾸어 학습에 적용하였다. 여기서 말하는 Reading Comprehension은 어떠한 Context가 입력되면 해당 데이터에서 질문에 대한 답을 찾는 SQuAD와 같은 기계독해 태스크와는 조금 다르게 볼 수 있다. 모델이 학습할 때, 원시 말뭉치가 입력되어 학습되는 부분을 “Reading”, 그리고 뒤따라오는 태스크를 “Comprehension” 과정으로 보았다. 위의 그림 2는 이에 관한 예시를 나타낸다. 원시 말뭉치에서 포착할 수 있는 다양한 형태의 키워드나 규칙에 따라서 해당 구문을 “Entailment Relation, Semantic Similarity, Text Ending” 등의 다양한 태스크를 수행하는 형태의 말뭉치로 변환하게 된다.
해당 방법은 “Don’t prompt, search! miningbased zero-shot learning with language models“에서 처음 제안되었던 방법을 개량하여 적용한 것인데, 처음 제안되었던 방법의 구조는 아래의 그림과 같다.
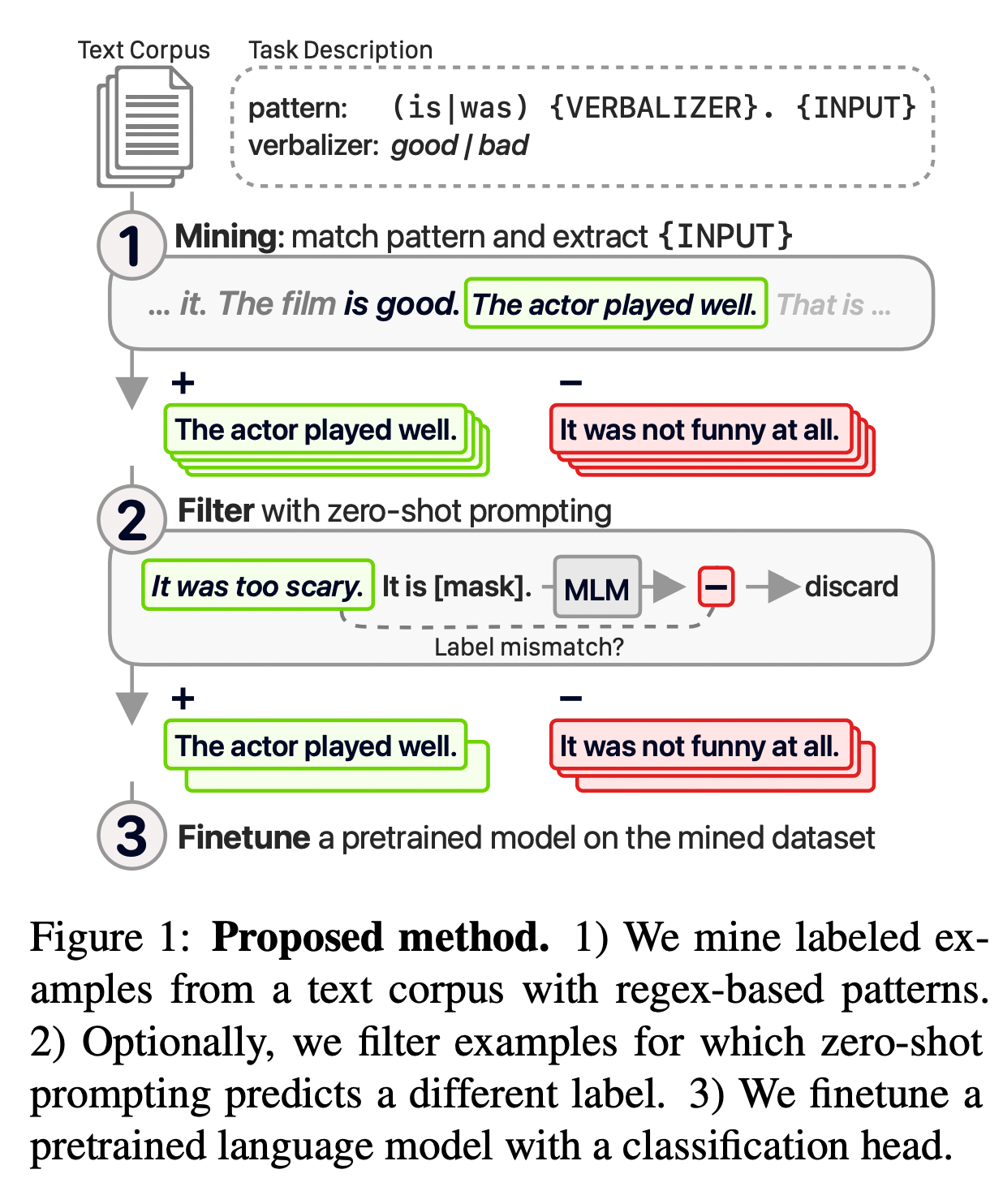
그림 3. 이전 연구의 사전학습 데이터셋 생성 방법
위의 그림을 살펴보면 Mining, Filter, Finetune의 3가지 과정으로 이루어져 있고, Mining 과정에서 특정 패턴에 일치하는 텍스트들을 말뭉치에서 추출하여 특정한 태스크의 데이터로 변환하여 학습에 적용한다.
해당 논문에서도 이전 연구의 이러한 Mining 과정을 이용해서, 도메인에 특화된 원시 말뭉치에서 특정 태스크로 변환할 수 있는 패턴을 가지는 텍스트들을 추출하고, 추출된 텍스트들을 특정 태스크를 수행하는 말뭉치로 변환하여 Continued Pretraining을 수행한다.
이렇게 학습을 하면, 기존 원시 말뭉치가 입력되고 학습되는 Reading 부분에서는 DAPT와 같이 원시 말뭉치에 학습하면서 도메인에 특화된 지식을 습득할 수 있을 것이고, 특정 태스크를 수행하는 Comprehension 부분에서는 도메인에 특화된 말뭉치를 더 깊게 학습하고 또한 기존 Genral LLM의 Prompt Ability를 헤치는 것을 최소화할 수 있을 것이다.
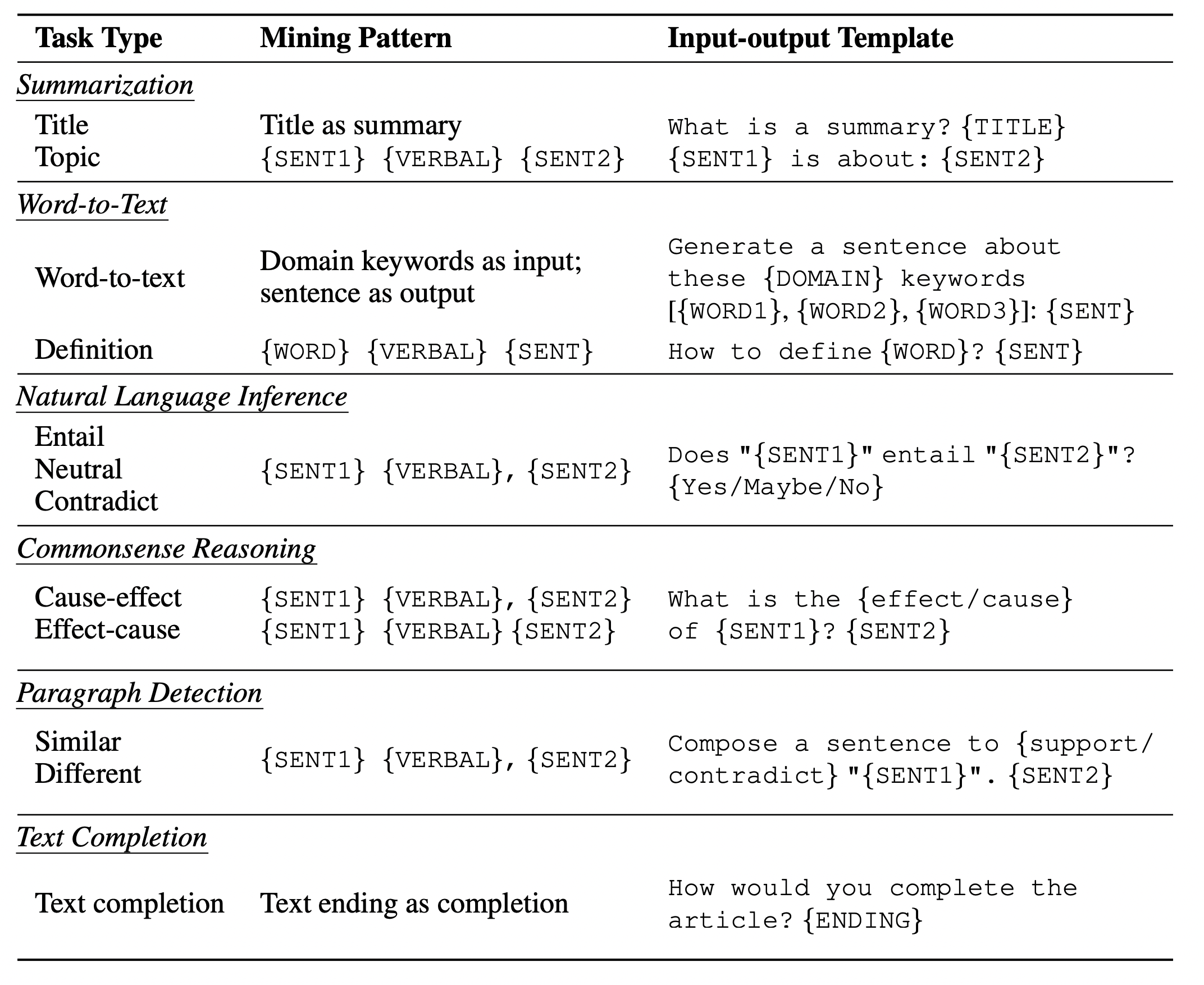
그림 4. 각 태스크별 Mining을 위한 패턴 및 프롬프트 형식
해당 논문에서 Continued Pretraining에 적용하는 태스크들은 다음과 같다.
Summarization
말 그대로 텍스트를 요약하는 작업이다. 문서의 제목이나 토픽 등이 있을 때 적용하는데, 반대로 요약된 텍스트를 넣고 원본 텍스트를 생성하는 태스크도 추가로 적용하였다.
Word-to-Text
특정 키워드들을 가지고 문단을 생성하는 태스크이다. 도메인 특화 말뭉치에서 SentencePiece를 이용해서 Vocab을 생성하고, 범용 도메인의 말뭉치에서 생성된 Vocab과 비교하여 도메인 특화 말뭉치의 Vocab에만 있는 토큰들을 도메인에 특화된 토큰으로 설정한다. 그리고 사전학습 원시 말뭉치에서 해당 도메인에 해당하는 토큰들이 나오면 해당 토큰들을 도메인에 특화된 키워드들로 설정하여 학습에 적용한다.
Summarization 태스크와 마찬가지로 단락-to-키워드, 키워드-to-단락의 양방향으로 생성하도록 태스크를 설정한다.
Natural Langauge Inference
해당 태스크는 정규표현식을 이용해서 Premise-hypothesis-relation을 판별할 수 있는 접속사들을 찾아낸다. 예를 들어 “However”로 연결된 문장들은 Contradiction 관계일 수 있고, “Therefore”과 같은 접속사로 연결된 문장들은 Entailment 관계의 문장일 수 있다.
Commonsense Reasoning
정규 표현식을 이용해서 cause-and-effect 관계가 되는 문장들을 찾아낸다.
Paraphrase Detection
두 문장이 의미적으로 일치하는지를 모델에게 물어보는 태스크이다. 하지만 Mining 과정에서 정규표현식을 이용했을 때, 의미적으로 일치하는 단어를 확실하게 찾아내는 것이 까다로웠다. 예를 들어 “Similarly”라는 표현으로 시작하는 문장이 있더라도 뒷 문장과 의미가 무조건 같다고 볼 수는 없었기 때문이다. 이에, 두 문장이 의미적으로 완전히 일치하는지를 물어보는 대신, 두 문장이 “Supports”한지 혹은 “Contradiction”한지를 물어보도록 프롬프트를 설계하였다.
Text Completion
Casual Language Model과 같이 이후에 나올 텍스트를 생성하는 태스크이다.
Mixing with General Instructions
더 다양한 패턴의 프롬프트를 적용하기 위해서, 일반적인 Instruction Tuning 데이터셋을 섞어서 모델을 학습하였다.
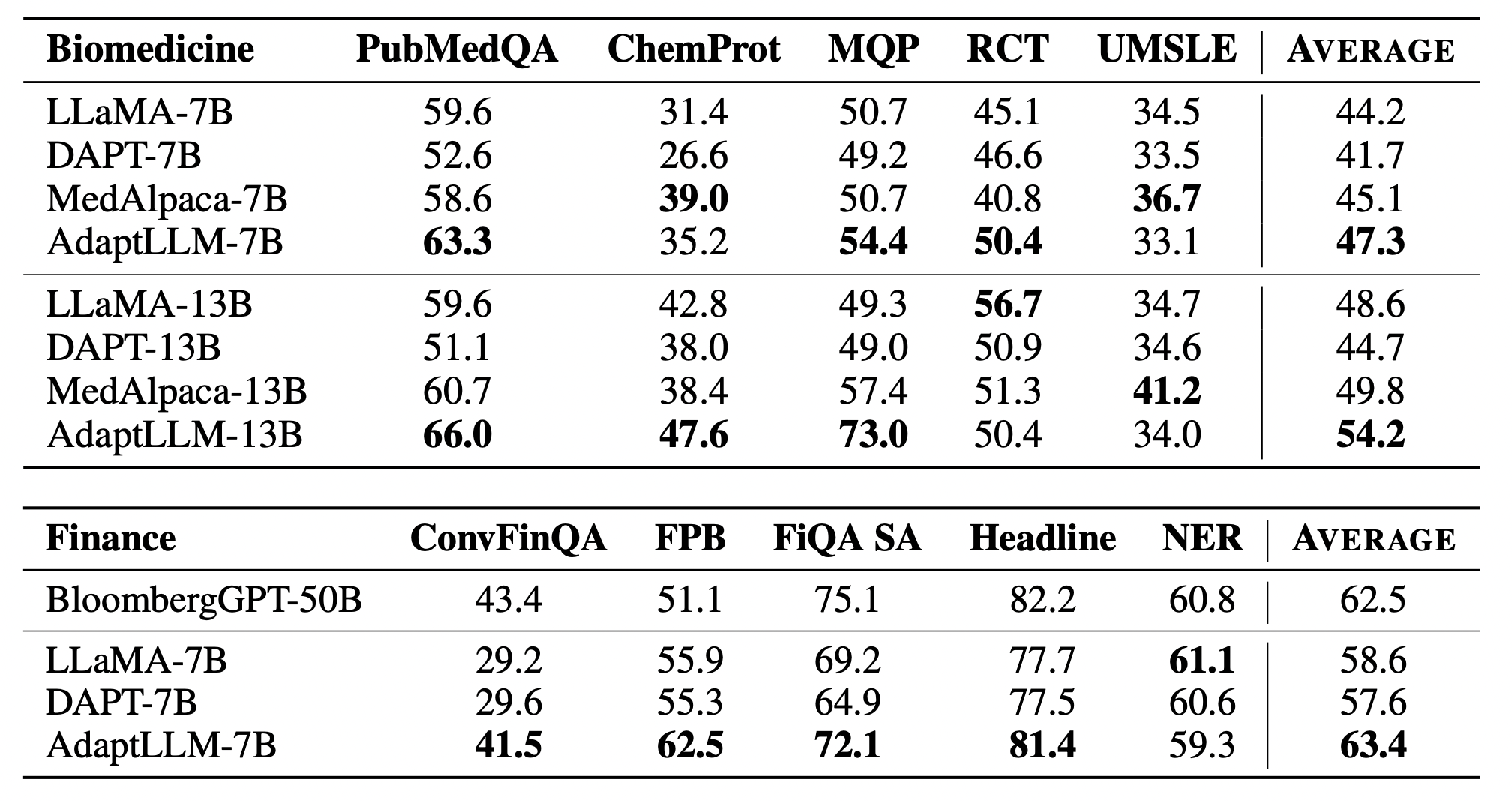
그림 5. Adapt LLM 실험 결과
다음은 AdaptLLM의 실험 결과이다. 이전 그림 1의 결과에서 DAPT가 도메인에 특화된 학습을 했을 때, 일부 성능에서 오히려 성능이 감소한 것과 다르게 AdaptLLM은 UMSLE와 NER을 제외하고 모든 태스크에서 성능이 향상된 것을 확인할 수 있다.
이번 글에서는 도메인에 특화된 사전학습을 할 때, 기존 모델의 Prompt Ability를 헤치지 않고 도메인에 특화된 지식을 학습할 수 있는 AdaptLLM 방법을 살펴보았다. Mining 과정을 통해서 다양한 태스크로 변환할 수 있는 텍스트들을 도메인에 특화된 원시 말뭉치에서 추출하고 해당 데이터셋들을 추가 사전학습에 적용하여 도메인에 특화된 지식을 잘 학습하면서도 기존 모델의 성능을 크게 헤치지 않을 수 있었다.