오늘 살펴볼 논문은 ” Instruction Pre-Training: Language Models are Supervised Multitask Learners “이다.
저번에 살펴본 논문에서 데이터를 합성하는 MEGPIE를 살펴보았는데, 오늘도 이어서 LLM을 이용한 데이터 합성과 관련된 논문을 살펴보았다.
아래의 그림은 논문에서 제안된 Instruction Pre-Training의 방법을 나타낸다.
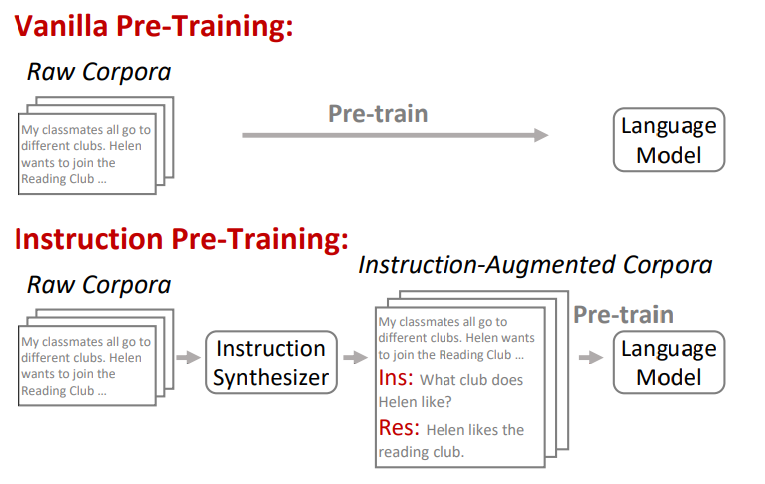 그림 1. 기존의 사전학습 방법과 제안된 Instruction Pre-training 방법의 비교
그림 1. 기존의 사전학습 방법과 제안된 Instruction Pre-training 방법의 비교
대규모의 원시 말뭉치를 이용하여 사전학습하고, 비감독학습 기반의 멀티태스크 학습은 언어모델을 사전학습하는 방법의 매우 보편적인 방법이 되었다. (해당 논문에서 Vanilla 방법으로 정의)
하지만 그럼에도 불구하고, 감독학습 기반의 멀티태스크 학습 방법이 좋은 성능을 보여주고 있다.
Instruction 튜닝은 다양한 태스크의 데이터를 잘 맞춰진 frame에 자연어 Instruction을 추가하여 구축한 태스크의 데이터셋으로 모델을 파인튜닝 하는 방법이다. 이러한 방법은 태스크의 일반화 성능을 높이는데 크게 기여를 하였다.
해당 논문에서는 원시 말뭉치를 이용해서 모델을 바로 사전학습 시키는 대신, 원시 말뭉치에 Instruction Synthesizer를 적용해서 해당 원시 말뭉치와 관련된 Instruction 데이터를 생성하고, 이를 통해서 모델을 사전학습하는 방법을 제안한다.
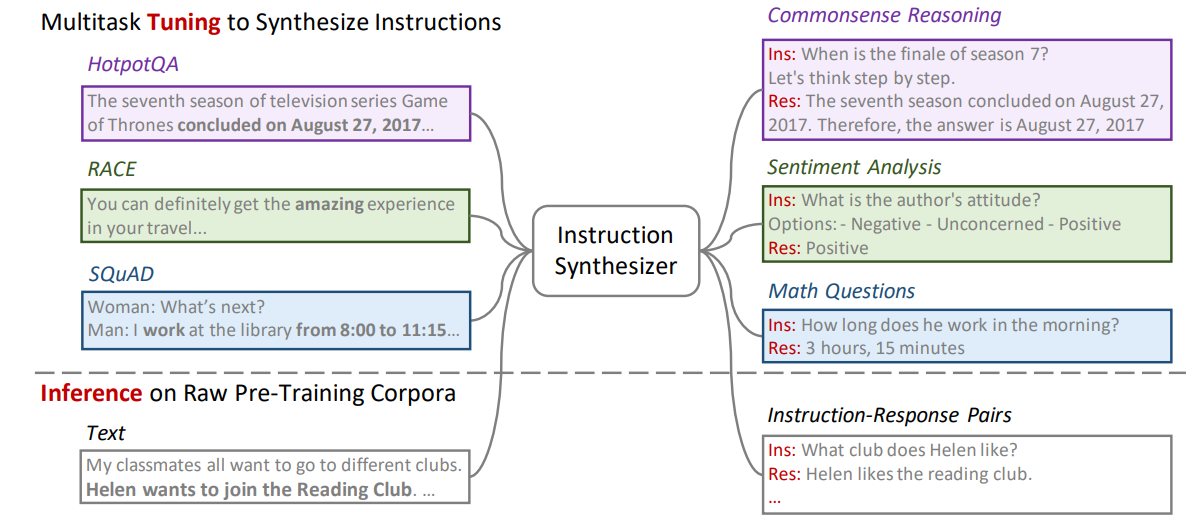
그림 2. Instruction Synthesizer 학습 방법
Instruction Synthesizer를 구축하기 위해서, 다양한 범위의 이미 공개된 데이터셋들을 활용하였다. 그림 2를 보면 HotpotQA, RACE, SQuAD, 등의 공개된 데이터셋들이 활용된 것을 볼 수 있다. 이러한 데이터셋들은 어떠한 질문과 답변셋이 있을 때, 질문에 대한 답변을 위한 컨텍스트 데이터가 함께 제공되는 데이터들이다.

그림 3. Instruction Synthesizer 학습 방법
Training Synthesizer
위의 그림에서 볼 수 있듯이 모델의 튜닝은 few-shot examples 방식으로 진행된다. 각 입력 시퀀스는 데이터셋에서 샘플링된 여러 개의 예제를 결합하여 입력되는데, 이렇게 함으로써 여러 예제를 연결한 것이 few-shot examples로 구성이 되어 서로 다른 질문-답변쌍의 데이터 집합 간의 일관성을 유지할 수 있게 한다.
Inference
Inference 과정에서도 이러한 학습 데이터의 형식과 같이 생성된다. 첫 번째 Round에서는 컨텍스트 데이터를 받고 질문-답변 쌍의 데이터를 생성한다. 생성된 질문-답변 쌍 데이터를 뒤에 결합하고, 새롭게 데이터를 생성하고자 하는 컨텍스트를 추가로 결합한다. 그리고 해당 컨텍스트 데이터에 대한 질문-답변쌍을 생성한다. 이 과정을 정해진 Round의 수 만큼 반복하면서 데이터를 생성한다.
LM Pretraining
언어모델의 사전학습에서는 “ADAPTING LARGE LANGUAGE MODELS TO DOMAINS VIA READING COMPREHENSION”와 “The Flan Collection: Designing Data and Methods for Effective Instruction Tuning”에서 사용된 템플릿을 이용한다. 학습에 사용되는 방식은 학습 데이터가 원시 말뭉치에서 Instruction 형식의 데이터셋으로 바뀐 것 외에는 Next Token Prediction Objectives로 학습되는 것은 동일하다.
General Pre-Training From Scrach
모델을 완전히 처음부터 학습할 때도 해당 방법이 적용될 수 있는데, 원시 말뭉치의 일부만 Instruction 형식으로 변형하여 두 가지 형식의 데이터를 함께 학습한다.
Domain-Adaptive Continual Pretraining
해당 방법은 모델을 완전히 처음부터 사전학습하는 것 보다는 이미 사전학습된 모델에 도메인과 관련된 원시 말뭉치에 추가로 사전학습을 할 때 더 효과적일 수 있다. 도메인에 특화된 원시 말뭉치를 Instruction Synthesizer를 이용해서 Instruction 형식의 데이터로 변환하여 학습에 적용한다. 이때, 변형된 Instruction Turning 데이터만 사용하는 것 보다는 General한 데이터를 섞어서 함께 학습시켜주는 것이 모델의 학습 결과가 더욱 좋았다고 한다.
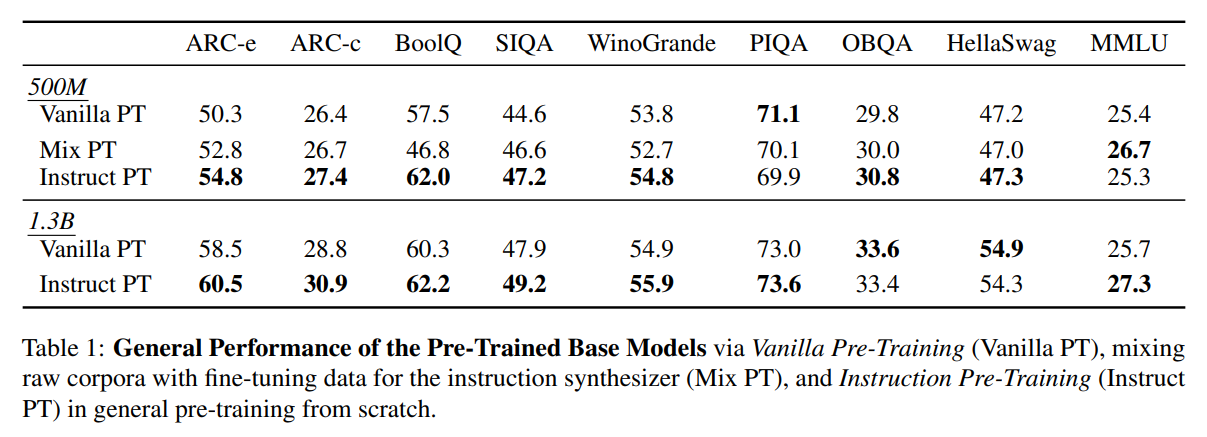
위의 그림은 General한 데이터를 이용하여 사전학습한 모델의 실험 결과이다. 각 사전학습된 모델에는 “ADAPTING LARGE LANGUAGE MODELS TO DOMAINS VIA READING COMPREHENSION”에서 제안된 방법으로 생성한 Instruction Tuning 데이터셋이 적용되었다.
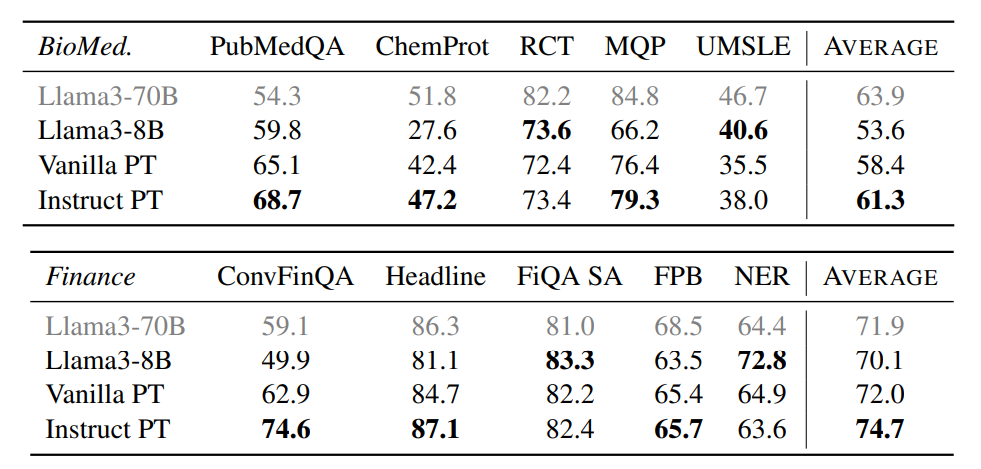
위의 그림은 Domain-Adaptive Continual Pretraining에 해당 방법을 적용한 것이다. 합성한 데이터셋 외에도 General한 Instruction Tuning 데이터셋이 함께 학습되었다.
오늘은 원시 말뭉치를 Instruction Tuning 데이터셋 형식으로 변환하여 모델을 사전학습하는 방법을 살펴보았다. 아무래도 Domain에 특화된 원시 말뭉치로 추가 사전학습을 했을때, 태스크에 대한 일반화 성능이 하락하면서 전체적인 성능이 떨어지는 경우도 많이 이 발생하는데 그러한 부분에 대한 어느정도의 해결법이 될 수 있을 것 같다.
논문에 상세히 설명된 부분이 부족하기도 하고, 이전 연구들에 대한 Follow-Up이 부족해서 글의 내용이 조금 부실하게 작성되었는데 다음 포스팅에서는 이 논문의 이전 연구인 “ADAPTING LARGE LANGUAGE MODELS TO DOMAINS VIA READING COMPREHENSION”의 내용도 살펴볼 예정이다.