오늘 다룰 논문은 “Towards Complex Document Understanding By Discrete Reasoning”으로 TAT-QA 데이터셋의 후속 연구인 TAT-DQA 데이터셋을 소개하는 논문이다.

그림 1. TAT-DQA 예시
TAT-DQA는 표와 텍스트 데이터에 대한 추론을 하여 질문에 대한 답을 해야하는 테스크인 TAT-QA를 확장한 버전인데, PDF 문서를 가져와서 바로 QA에 적용했다는 특징을 가지고 있다. 처음에 이 논문을 보았을 때는 Visual Question Answering 데이터셋이란 부분을 강조하고 있어서 문서에 포함되어 있는 다른 이미지들도 함께 처리해야하는 멀티모달과 관련된 데이터셋이라고 생각했다. 하지만 이 논문의 데이터셋은 텍스트를 다루는 언어모델만으로 처리가 가능하다. 그렇다면 어떤 부분에서 이 논문은 VQA 데이터셋이라고 볼 수 있는걸까?
이 논문에서 비교하고 있는 다른 데이터셋들을 먼저 살펴보자.

그림 2. DocVQA 데이터셋 예시
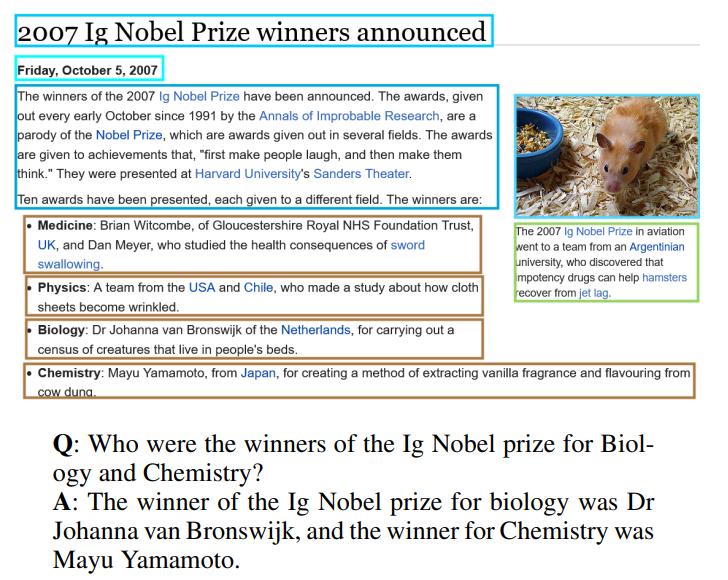
그림 3. VisualMRC 데이터셋 예시
위의 그림 2개는 논문에서 같이 소개된 DocVQA 데이터셋과 VisualMRC 데이터셋의 예시를 나타낸다. 소개된 두 데이터셋 모두 문서에 존재하는 그림과 텍스트 단락을 같이 조합하여 추론하고 정답을 도출하도록 데이터셋이 설계되어 있는 것을 볼 수 있다. 하지만 TAT-DQA의 그림에서는 이미지 데이터는 찾아볼 수 없으며, TAT-DQA의 데이터셋을 다운받아보면 모두 텍스트로 이루어진 Json 파일만 배포하고 있는 것을 확인할 수 있다. 그렇다면 어떤 부분에서 VQA라고 할 수 있는걸까?
우선, 해당 데이터셋의 이전 연구인 TAT-QA의 데이터셋을 설펴보면
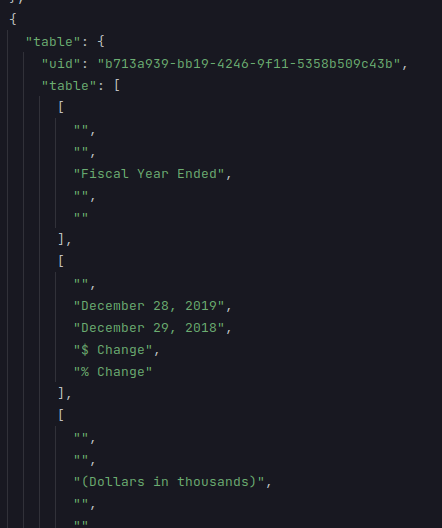
그림 4. TAT-QA 데이터셋 파일 예시
다음과 같이 리스트 형태로 잘 정제되어 있는 테이블 데이터를 제공하는 것을 확인할 수 있다.

그림 5. TAT-DQA 데이터셋 파일 예시
위의 그림은 TAT-DQA의 파일의 예시인데 잘 정제된 테이블이나 텍스트 단락이 포함되어 있는 대신 bbox_list, word_list, text로 구성되어 있는 것을 확인할 수 있다. 해당 데이터셋이 저런 형태를 띄는 이유는 PDF 파일에 PDF 텍스트 변환기나 OCR을 적용해서 자동으로 텍스트를 추출한 후 별다른 후처리를 전혀 하지 않는 상태이기 때문이다. 일반적으로, TAT-QA와 같은 데이터셋을 구축할 때는 사람이 직접 데이터에 사용된 문서를 분석하고 적절히 필요한 표를 형태에 맞춰서 정렬한 후 데이터에 포함시켰다. 하지만 해당 데이터에서는 그러한 과정을 모두 생략하고 텍스트로 변환된 문서 데이터를 바로 제공하고 있다. 그렇기 때문에 해당 데이터를 VQA로 분류한 것이다.
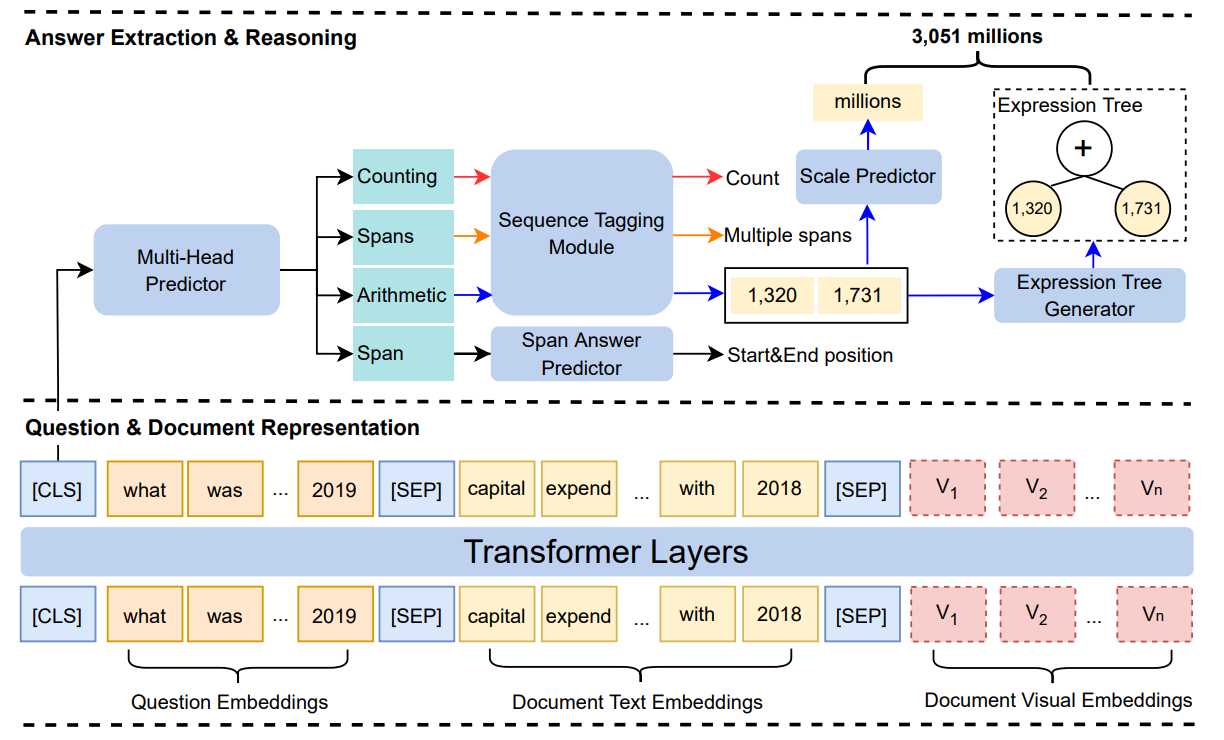
그림 6. Baseline 모델로 제안된 MHST(Multi-Head Seq2Tree)
위의 그림은 해당 데이터셋을 소개하는 논문에서 Baseline 모델로 제안한 MHST 모델이다. 해당 모델은 이미지와 텍스트를 모두 처리할 수 있는 멀티모달 트랜스포머 모델을 인코더 모델로 사용하였다. 여기서 Visual Embeddings는 문서의 PDF를 이미지(224X224)로 만들고 해당 이미지를 입력으로 함께 사용하였다. (PDF 변환이나 OCR 과정에서 구조화된 데이터의 정보가 손실되기 떄문에 이를 보완하기 위함인것 같다)
Multi-Head Predictor는 정답 타입을 “Span, Spans, Counting, Arithmetic” 중 하나로 예측한다. Span 타입에서는 SQuAD와 같이 입력된 토큰 안에서 정답의 시작과 끝을 예측하도록 하였고, 나머지 타입의 정답은 BIO를 예측하는 Sequence Tagging Module을 통해서 관련된 정답을 예측하도록 하였다.
그 외에 text block과 table block을 별개로 처리한다거나 등의 내용이 적혀있었으며, 실제로 table block을 heuristic하게 찾아내어 따로 처리를 하였을 때 성능이 향상되었다고 하였지만 구체적으로 어떻게 다르게 처리하였는지는 자세히 나와있지 않았다. “. Finally, the embeddings of the question, table blocks, non-table blocks and the image are input sequentially to the LayoutLMv2LARGE model to obtain question token representations 𝑄 and document token representations ” 논문의 다음과 같은 내용이 있는걸로 봐서는 Segment를 다르게 준다던지 등의 임베딩에서 차이를 뒀을 수도 있을 것 같다. (MHST 모델의 공개된 소스코드가 없어 어떻게 적용되었는지는 정확하게 확인할 수 없었다)
글을 마무리하자면 TAT-DQA는 PDF-Converter와 OCR을 통해서 PDF 문서에서 텍스트를 추출하고 추출된 텍스트에 별다른 후처리를 하지 않고 바로 QA에 적용하는 태스크를 제안했다. 최근에는 PDF를 이용한 RAG가 활발하게 개발되면서 이전에 비해서 Text를 추출하는 기능이나 Table도 어느정도 잘 추출하는 것을 보여주고 있다. 하지만 그러한 기능이 완벽하지는 않기 때문에 이러한 데이터셋은 텍스트 추출이 불가능한 PDF 파일에 대해서 QA를 진행할 때 유용할 수 있을 것 같다.
추후 LLM을 이러한 TAT 데이터셋에 적용한 TAT-LLM에 대하여 다뤄보겠다.