오늘 정리해볼 논문은 “Table Retrieval May Not Necessitate Table-specific Model Design”이다.
여러 논문에서 Table Retrieval에는 테이블에 특화된 모델 구조(Table Specific Model Archirecture)이 적용되었고 특화된 모델 구조가 효과적이라고 주장을 해왔다. 이 논문에서는 이러한 주장과 반대로 Table Retrieval에서 표에 특화된 모델 구조가 꼭 필요하지 않을 수 있다고 주장을 한다.
NQ(Natural Questions) 데이터셋에서 약 74.4%는 위키피디아의 텍스트 단락에서 답을 찾을 수 있는 질문이며, 13.2%는 표에서 정답을 찾을 수 있는 질문이다. NQ-Tables 데이터셋은 이러한 표에서 답변이 가능한 질문들을 선별하여 만든 Table Retrieval 데이터셋이다. 본 논문에서는 앞서 말했던 주장의 근거를 위해서 NQ-Tables 데이터셋을 이용해서 다양한 시나리오에서 테스트를 진행하였다.
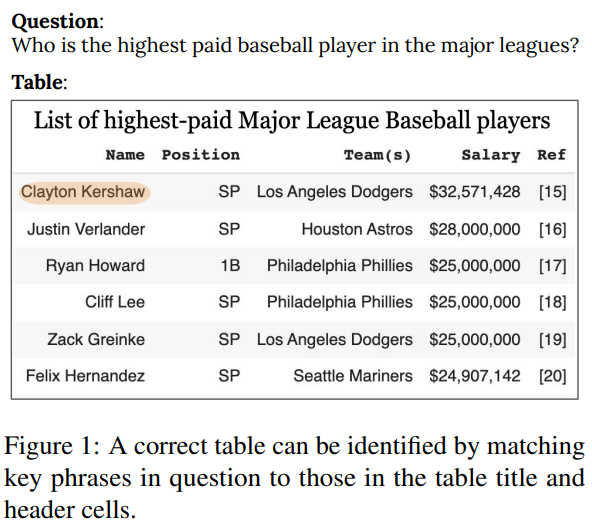
그림 1. Table Retrieval이 Key Phrase 매칭을 통해서 이루어짐을 보여주는 예시
우선 가장 첫번째로 주장한 내용은 Dense Retrieval 태스크는 핵심이 되는 부분(Key Phrase)을 매칭하는 태스크라고 볼 수 있는데 표 데이터에 적용하더라도 이는 마찬가지이며, 이러한 이유로 표에 대한 특별한 모델 구조가 큰 의미를 가지지 않을 수있다는 것이다. 본 논문의 저자들이 NQ-Tables 데이터셋의 질문 100개를 랜덤하게 뽑아서 직접 분석을 해보았을 때 약 70%는 구조적인 분석이 아예 필요없는 경우였고, 30%는 아주 간단한 구조적인 분석(Row 및 Column 단위의 비교)이 필요한 경우였다고 한다. 아주 간단한 구조적인 분석이 필요하다고 하더라도 표에 특화된 모델의 구조없이 표를 평면화해서 입력하고 각 행과 열 그리고 셀을 구분할 수 있는 구분자 토큰을 삽입해주면 일반적인 BERT 모델을 사용하더라도 간단한 구조 분석이 가능했다고 하였다.
비교 분석 실험을 위해서 일반적인 Dense Retrieval 모델과 Table 데이터에 특화된 Dense Retrieval 모델을 이용해서 NQ-Tables 데이터 테스트셋에서 성능을 비교하는 실험을 진행했다. 일반적인 모델은 DPR(Dense Passage Retrieval), 테이블을 위한 모델은 DTR(Dense Table Retrieval)로 표기하였다.
DPR은 Facebook의 논문(Dense Passage Retrieval for Open-Domain Question Answering)의 모델 구조, 데이터 및 세팅을 그대로 이용하였다. DTR은 TAPAS의 저자들이 진행했던 이전 연구(Open Domain Question Answering over Tables via Dense Retrieval)의 모델 구조와 학습 방법 및 세팅을 그대로 이용하였다.
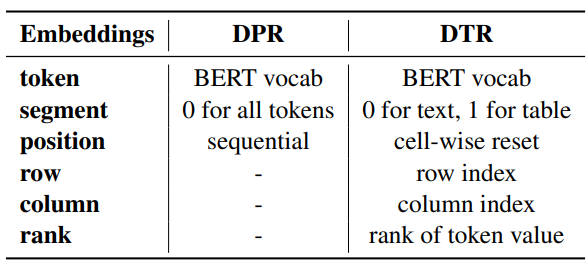
그림 2. DPR 모델과 DTR 모델 비교
DTR에서 가장 큰 차이를 보이는 부분은 Embedding Layer 부분이다. TAPAS 모델에서는 표의 구조를 인코딩하기 위한 특수한 임베딩들을 도입했는데 Prev Labels은 SQA 태스크에서만 필요한 특수한 임베딩이며, Numeric Relation은 질문과 표가 동시에 입력되어야만 사용할 수 있는 임베딩이기 때문에 Col, Row, Rank의 특수 임베딩이 적용되었다.
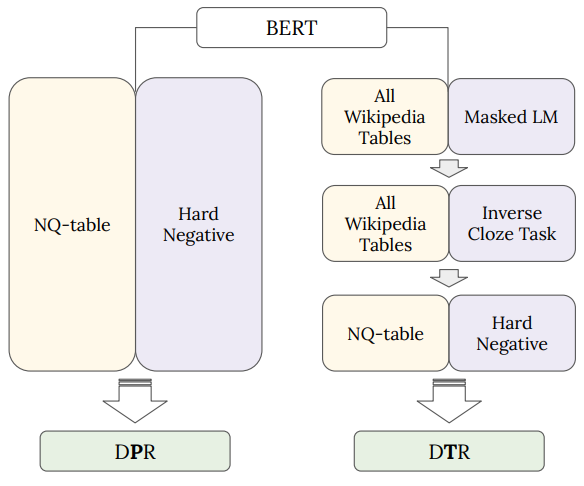
그림 3. DPR과 DTR 학습 과정 비교: DPR은 NQ-Table 데이터셋에 바로 fine-tuning을 하며, DTR은 Wiki Table에 MaskLM(TAPAS), ICT를 이용한 추가 사전학습을 거친 후 fine-tuning을 함
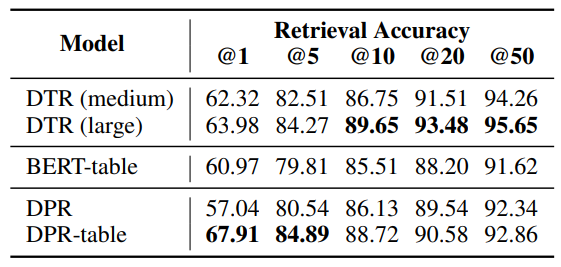
그림 4. Top-K Table Retrieval 성능 비교
성능 결과표에서 BERT-Table은 BERT 모델을 NQ-Tables 데이터셋에 바로 파인튜닝한 모델이다. DRP은 텍스트 데이터에 학습된 모델인데 NQ-Tables 데이터셋에는 Zero-shot으로 적용되었다고 볼 수 있으며, DPR-Table은 DPR 모델을 NQ-Tables 데이터에 추가로 fine-tuning 한 모델이다. 결과를 비교해보면 DTR 모델이 DPR-table 모델과 비교하여 더 높은 성능을 보여주고 있는데, 논문의 저자는 Table-Specific한 모델이 큰 성능 차이를 보이지 않는다고 했지만 그래도 표기된 성능을 보면 유의미한 성능 차이를 보여주고 있다고 생각한다. 다만 DTR 모델은 위키피디아 테이블 데이터를 이용해서 ICT 태스크에 추가로 사전학습을 하였는데 NQ-Tables 데이터 역시 위키피디아 테이블 데이터을 태깅해서 만든 데이터셋이기 때문에 다른 도메인의 테이블을 사용하는 데이터셋에 비교하였다면 논문의 저자의 주장에 훨씬 더 맞는 결과가 나올 수도 있었을 것 같다. 다만 흥미로운 점은 DPR 모델을 이용해서 테이블 데이터에는 학습되지 않은 Zero-shot으로 NQ-Tables 데이터셋에 평가를 했을 때 BERT 모델을 NQ-Tables 데이터셋에 fine-tuning한 BERT-table 모델보다 더 좋은 성능이 나왔는데 이 결과는 대부분의 질문이 Dense Retrieval 모델에서 사용되는 Key Phrase 매칭만으로 이루어진다는 주장에 힘을 실어준 것 같다.
정리하자면 이 논문에서는 Table Retrieval 과정에서 꼭 테이블을 위한 Table-Specific한 모델이 필요한지에 관한 의문을 제기하고 이를 증명하기 위한 DTR, DPR 모델의 성능 비교를 하는 실험을 진행하였다. DTR과 DPR의 유의미한 성능 차이가 났지만 그럼에도 저자의 주장에 어느정도 부합하는 결과도 다수 보여주었다.