오늘 간단하게 살펴볼 논문은 RocketQAv2 논문이다.
2021년에 발표되었던 논문이지만, Retrieval 및 Re-rank 관련 논문들을 조사하면서 다시 살펴보게 되었다.
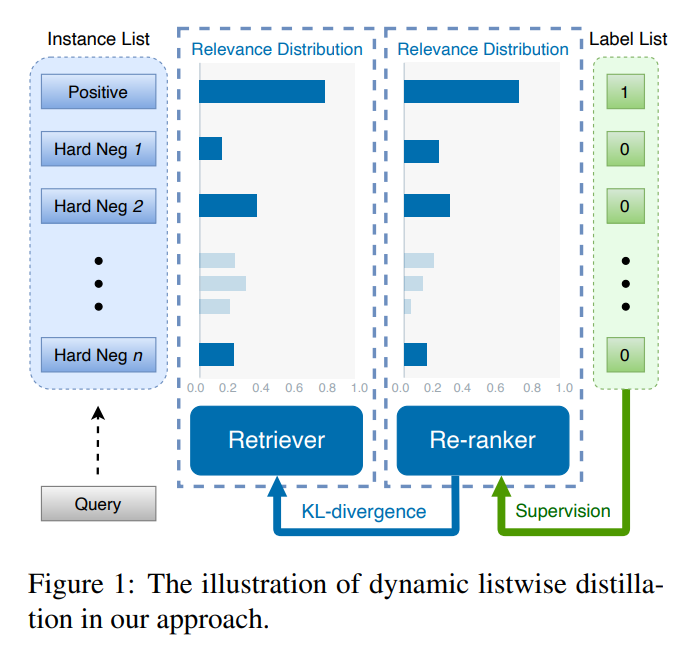
우선 Bi-Encoder 기반의 Retrieval 방식보다 Cross-Encoder 기반의 Retrieval 방식이 당연하게도 더 좋은 성능을 얻을 수 있다. 이에 다른 이전 연구에서는 Cross-Encoder와 Bi-Encoder를 각각 따로 학습을 시키고, Cross-Encoder의 지식을 Distillation 하는 방법을 주로 적용했었다.
하지만 그렇게 학습을 하면 결국 Cross-Encoder의 Weight는 Freeze한채로 학습을 하게 되고, Cross-Encoder와 Bi-Encoder가 긴밀하게 같이 학습이 되지 않는다. 이에 RocketQAv2는 두 가지의 모델을 긴밀하게 같이 학습을 시키면서 Knowledge Distillation을 적용하는 Dynamic Listwise Distillation 방식을 적용하였다.
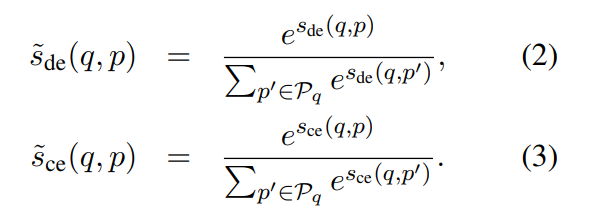
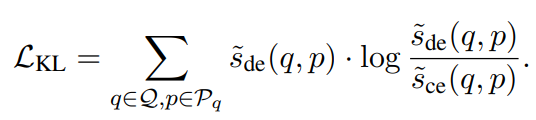
각 Retriever 모델의 예측 확률은 위의 수식과 같이 구할 수 있다. 그러면 기존 방법은 위의 KL Divergence를 통한 Loss를 최적화하도록 학습을 진행하고, 이 과정에서 Cross-Encoder의 Weight는 고정을 한채로 학습을 한다.
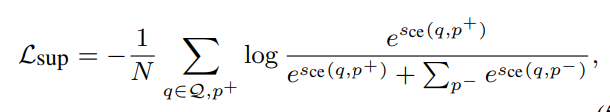
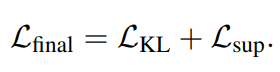
그러나 해당 논문에서는 KL Divergence를 통한 Knowledge Distillation을 학습시키면서 동시에 Cross-Encoder를 학습시키는 태스크에 관한 Loss를 추가해서 Cross-Encoder도 함께 업데이트되도록 하였다.
학습 과정에서 두 모델을 같이 업데이트함으로써 좀 더 동기화가 되고 최적화된 학습을 진행할 수 있다.
Hybrid Data Augmentation
Dynamic Listwise Distillation을 통해서 학습을 진행할 때, 쿼리 q에 관한 후보 passage list를 생성할 필요가 있다. 해당 학습 방법은 Listwise 방식을 이용하기 때문에 다양하고 높은 퀄리티의 후보 passage를 찾아주는 것이 필요하다.
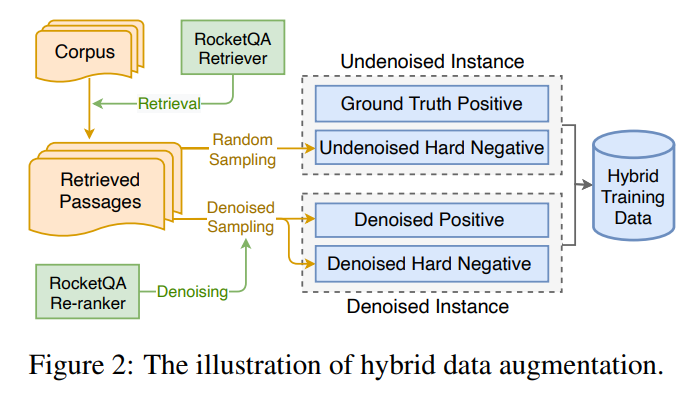
위의 그림은 다양하고 높은 퀄리티의 후보 Passage를 구하기 위한 Hybrid Data Augmentation 방법을 나타낸다. 우선 RocketQA Retriever에서 Top-N의 Passage를 구한다. 구해진 Passage를 Random Sampling해서 Undenoised Hard Negatives를 구한다.
Denoised Hard Negatives는 Re-ranker 모델을 이용하여 Confidence Score가 낮은 데이터들을 필터링하는 방법으로 구한다. Denoised Positive는 Re-ranker 모델에서 Confidence Score가 높은 데이터를 선택한다. Undenoised와 Denoised의 두 가지 데이터를 모두 학습 데이터로 이용하여 학습 데이터의 다양성을 추가할 수 있었다.
Training Procedure
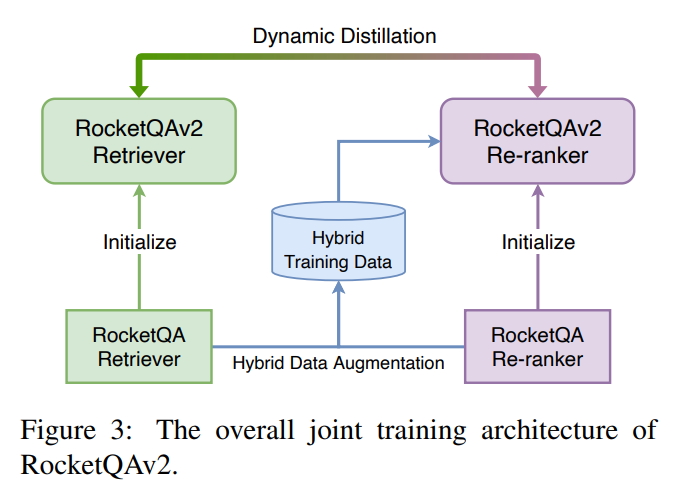
위의 그림은 학습 과정을 나타낸다. 우선 RocketQA 방법을 통해 학습된 Retriever 및 Re-ranker를 초기 모델로 설정한다. 그리고 Hybrid Training Data를 두 모델을 통해서 생성하고, 생성된 데이터셋으로 두 모델을 추가적으로 학습한다.
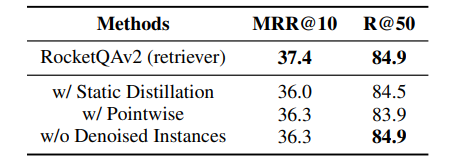
Dynamic or Static?
Static Distillation은 학습 과정 중에 Weight가 고정되기 때문에 Teacher 모델은 성능의 향상을 얻을 수 없다. 위의 표를 살펴보면 Dynamic Distillation을 했을 때, Retriever와 Re-ranker 모두 성능 향상을 얻을 수 있는 것을 확인할 수 있다.
Listwise or Pointwise?
위의 표를 살펴보면 Pointwise로 학습했을 때, Listwise로 학습된 모델보다 성능이 훨씬 떨어지는 것을 확인할 수 있다. 일반적으로 Re-ranker 모델은 Pointwise로 학습되고, Retriever는 Listwise로 학습된다. 하지만, Joint Training에서는 Listwise로 학습하는 것이 훨씬 효과적인 것을 확인할 수 있다.
오늘은 RocketQAv2를 살펴보았다. 해당 학습 방법은 두 가지 Retriever을 먼저 독립적으로 학습시키고, 두 모델을 이용해서 Distillation을 할 때, Joint하게 학습시키는 방법을 제안하였다. 비록 공개된지 꽤 오래된 논문이지만, 최근에 공개된 다양한 모델을 이용해서 추가적인 학습을 적용할 때 유용하게 사용될 수 있을 것 같다.