오늘 살펴볼 논문은 “REPLUG: Retrieval-Augmented Black-Box Language Models”이다.
REPLUG는 RAG 시스템에서 Black Box LLM을 활용할 때, 이를 이용해서 Retriever를 학습하는 방법에 관한 논문이다.
아래의 그림은 기존 RAG 시스템과 REPLUG 방법의 차이점을 보여준다.
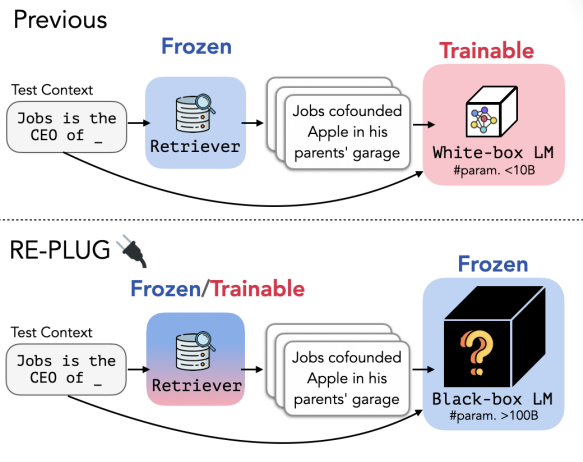
그림 1. 기존 RAG에서의 모델 튜닝 방식과 REPLUG 방법과의 비교
일반적으로 RAG 시스템의 구현에서 학습을 통해서 더 향상된 시스템을 구축하고자 할 때, Retriever 모델은 이미 해당 태스크에서 충분히 학습된 모델을 적용하고 답변을 생성하기 위한 LM을 추가로 튜닝하는 경우가 많다. 모델의 학습에는 매우 많은 자원을 필요로 하기 때문에, 보통 10B 내외의 모델이 사용되는 경우가 많다.
REPLUG에서는 이와 다르게, 답변을 생성하는 LM 모델을 그대로 두고, Retriever를 더 학습시켜서 사용한다. 이 때, LM은 학습이 매우 큰 파리미터의 문제나 혹은 접근성으로 인해서 학습이 불가능한 Black-box LM을 사용한다.
REPLUG 모델에서는 다른 RAG 모델과 같이 Bi-Encoder 기반의 모델을 Retriever 모델로 활용한다. 아래와 같이 Query와 Document의 표현 벡터를 구하고, 해당 벡터 간의 유사도를 통해서 두 데이터가 얼마나 Relevant한지를 판단한다.
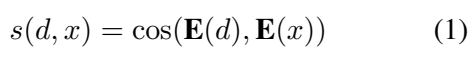
Retriever는 수 많은 문서 중에서 가장 연관성이 높은 Top-K 문서를 선별하고, 이를 LM 모델에 전달하여 최종 답변을 생성한다. 이 때, 수 많은 문서의 벡터 검색을 위해서 FAISS index가 활용되었다.
검색된 Top-K 문서는 비교적 정답을 얻기 위한 정보가 더 풍부하고, 이로 인해서 LM 모델이 해당 문서를 참조했을 때 정답을 찾기 더 용이해질 수 있다.
아래의 그림은 REPLUG 모델의 추론 과정을 나타낸다.
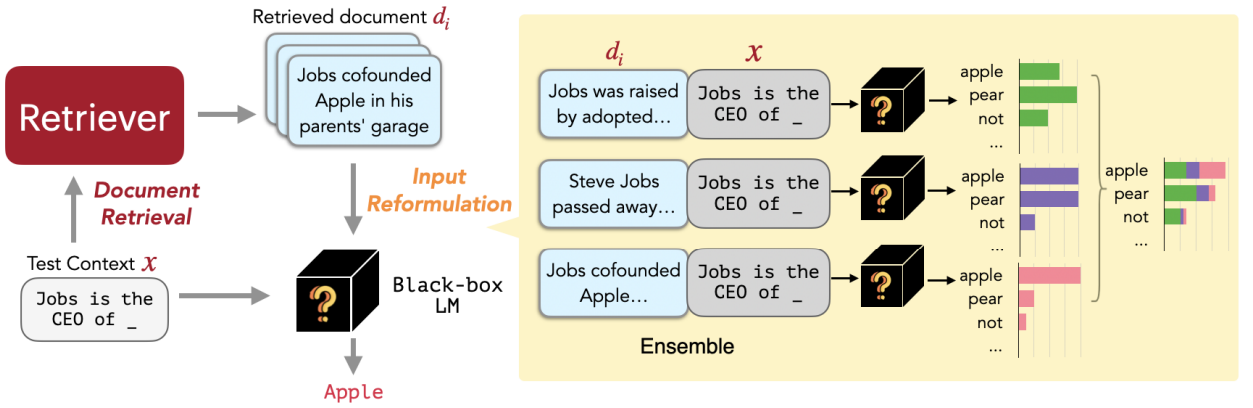
그림 2. REPLUG 모델의 추론 과정
위의 그림을 살펴보면 다음과 같은 과정으로 진행된다.
- Retriever에서 Text Context x와 연관있는 문서들을 탐색한다.
- 탐색된 문서와 d와 x를 결합하여 Black-box LM에 입력한다.
- 입력된 정보를 기반으로 정답을 생성한다.
- 이 때, 각 문서에서 나온 확률을 Ensemble하여 최종 예측 정답을 생성한다.
이 과정을 실행할 때, 만약 검색된 문서에 질문에 관한 정답과 관련된 정보가 풍부하게 포함되어 있다면 정답을 훨씬 잘 찾을 수 있을 것이다. REPLUG에서는 이 점을 이용하여 Retriever를 학습한다.
예를 들어, 위의 그림에서 “Jobs is the CEO of _”의 정답은 “Apple”이다. Retriever에서 탐색된 Top-K 문서들을 각각 LM에 입력하고 실제 정답인 Apple이 출력될 확률을 살펴보면 어떤 문서가 실질적으로 정답 생성에 유용한 정보들을 많이 포함하고 있는지를 간접적으로 알 수 있다. REPLUG에서는 바로 이 부분을 활용하여 Retriever 모델을 추가로 튜닝하게 된다.
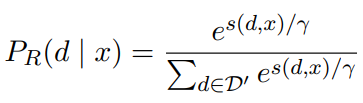
위의 수식은 유사도 점수에 Softmax를 적용한 Retriever 모델의 예측 확률을 나타낸다.
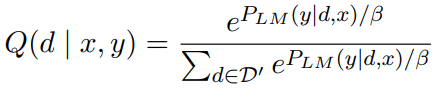
위의 수식에서 P_LM(y|d,x)는 d와 x를 LM에 입력했을 때 정답 y를 출력할 확률을 나타낸다. Q(d | x,y)는 Document d를 입력했을 때 정답이 출력될 확률을, 다른 문서를 입력했을 경우와 비교하여 나타낸 확률 값이다.
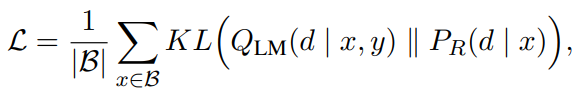
Retriver 모델을 학습하기 위한 Loss는 위의 수식과 같다. Retriever 모델의 예측 확률과 각 Document를 입력했을 때 정답이 출력될 확률을 KL-Divergence를 통해 학습하여 두 분포가 가까워지도록 학습한다. 그러면 Retriver는 LM에서 정답을 더 잘 찾을 수 있는 문서들을 더 높은 확률로 예측하도록 하는 방향으로 파라미터를 업데이트하게 된다.
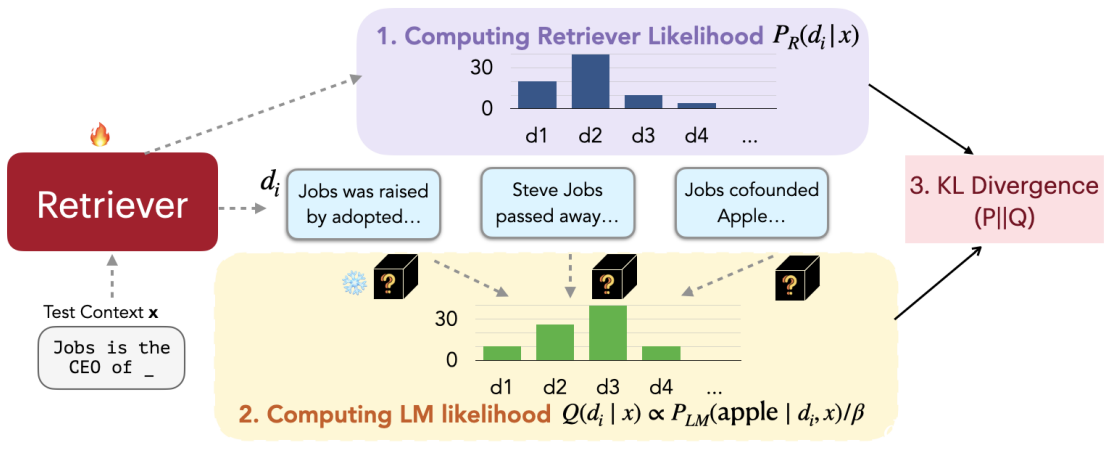
그림 3. REPLUG 모델의 학습 과정
Retriever 모델을 학습하는 동안에는 FAISS Index를 계속 갱신할 수는 없다. 하지만 FAISS를 계속 갱신하지 않게 되면, Retriever는 계속 업데이트되지만 업데이트 되기 이전 모델의 Top-K Documents를 입력받을 수 밖에 없다. 이에, 해당 논문에서는 매 T만큼의 Training Step이 돌아가면 FAISS index를 학습된 모델의 벡터로 갱신하도록 하고 있다.
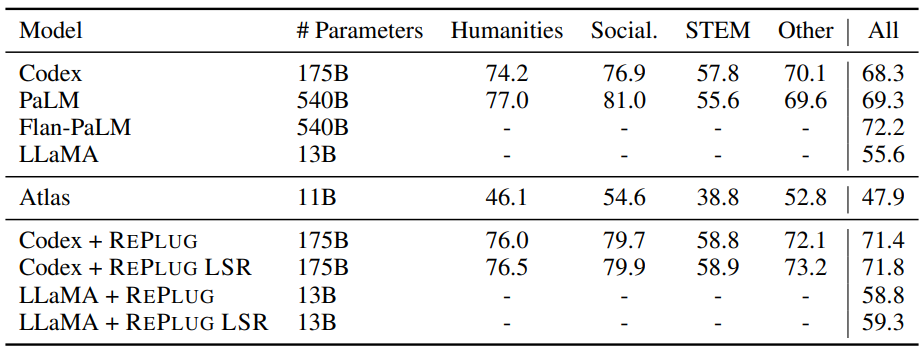
그림 4. REPLUG 모델의 성능 비교
위의 결과를 살펴보면, 다양한 모델에서 REPLUG를 적용함으로써 성능이 크게 향상되는 것을 확인할 수 있다. 또한, Retriever의 학습을 적용하지 않고 각 문서에서 예측된 확률을 Ensemble하는 REPLUG 방법만으로도 성능이 큰 폭으로 향상되는 것을 확인할 수 있다.
오늘은 RAG 방식에서 LM 자체를 파인튜닝하기 힘든 Black-Box LM을 사용할 때 유용하게 활용될 수 있는 REPLUG 방법을 살펴보았다. 아이디어가 간결하지만 매우 강력하고 실용적인 부분이 많았던 논문인 것 같다.