오늘은 “Retrieval-Augmented Generation for Large Language Models: A Survey”의 논문에서 소개되고 있는 다양한 논문들을 살펴볼 예정이다.
해당 논문에서는 RAG의 다양한 방법 및 모델들을 정리한 Survery 논문이다. 이번 글은 해당 논문의 다양한 부분 중 Query Optimization 부분에 소개된 논문들을 살펴볼 예정이다.
살펴볼 논문의 목록은 아래와 같다.
(1) Chain-of-Verification Reduces Hallucination in Large Language Models
(2) Query Rewriting for Retrieval-Augmented Large Language Models
(3) Precise Zero-Shot Dense Retrieval without Relevance Labels
(4) Large Language Model based Long-tail Query Rewriting in Taobao Search
첫 번째로 살펴볼 논문 CoVE(Chain-of-Verification Reduces Hallucination in Large Language Models)는 질문에 어떠한 답변을 했을 때, 해당 답변에 Hallucination이 포함되는 것을 방지하기 위해 Verification 과정을 추가하는 방법을 제안한 논문이다. 해당 논문의 방법은 Retrieval 과정에서 생성된 정보를 답변의 생성에 활용하는 것은 아니기 때문에 RAG와는 비슷하지만 다른 방법이라고 볼 수 있다. CoVE의 전체적인 실행 순서 및 구조는 아래의 그림과 같다.
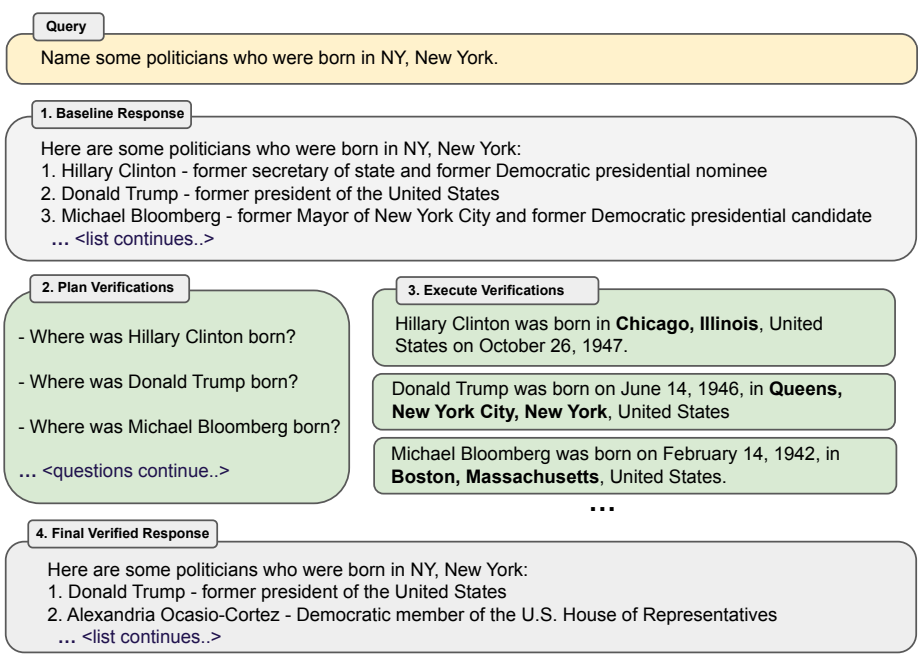
그림 1. CoVE의 실행 순서 및 구조
첫 번째 과정에서는 Baseline Response를 생성한다. 이때, Baseline Response에는 다소 부정확한 정보나 Hallucination 정보들이 포함될 수 있다.
두 번째 과정에서는 Plan Verifications를 생성한다. 이 과정에서 생성되는 정보들은 이전 단계에서 생성된 답변을 검증하는데에 필요한 질문들이다. 예를 들어 “Where was Hillary Clinton born?”이라는 질문이 생성된 것을 확인할 수 있는데, Baseline Response에서 Hillary Clinton의 출생지가 NY, New York으로 언급하고 있기 때문에 이를 검증하기 위한 질문을 생성하는 것이다.
세 번째 단계에서는 생성된 각 Plan Verifications에 대해서 답변을 생성한다. 이때, RAG에서 주로 사용되는 방법과 같이 검색 증강 방법을 통해서 해당 내용을 검증할 수도 있지만, 해당 논문에서는 LLM 자체만을 가지고 Plan Verifications에 답변을 생성하도록 하였다.
마지막 단계에서는 답변이 부착된 Verifications를 통해서 Baseline Response를 수정하는 과정을 거친다. 예를 들어 Plan Verifications의 답변에서 Hillary Clinton의 출생지는 Chicago, Illinois로 출력이 되어 기존 답변과 상충되는 것을 확인할 수 있다. 이에 Final Verified Response에서는 이러한 부분을 반영하여 Hillary Clinton이 답변에서 제외된 것을 확인할 수 있다.
이러한 CoVE를 수행하는 방법에는 “Joint”, “2-Step”, “Factor”, “Factor+Revise”의 방법이 있다.
우선 Joint 방법은 단순하게 Planning과 Execution에 하나의 LLM 프롬프트를 사용하는 방법이다. 하지만 Joint 방법에서는 초기 응답(Baseline Response)에 의존하여 검증 질문과 답변이 생성될 수 있는 문제가 있다. 초기 응답이 이미 부정확하거나 불완전할 경우, 검증 답변도 잘못된 방향으로 유도될 가능성이 높아지는 문제이다.
다음 방법인 2-Step은 Plan과 Execution에 각각 다른 LLM 프롬프트를 적용하는 방법이다. Execution 단계의 프롬프트에는 Plan Question 외에 Baseline Response와 같은 정보가 포함되지 않는다.
다음 방법은 Factored 방법이다. 해당 방법은 생성된 각 Plan Questions를 독립적으로 별개로 실행시켜 정답을 생성하는 방법이다.
마지막으로 Factor + Revise 방법이다. 해당 방법은 Verification 답변을 생성하고, 해당 답변이 Consistency한지 혹은 Inconsistency한지를 점검하는 과정에서도 분리된 LLM 프롬프트를 활용하는 방법이다.
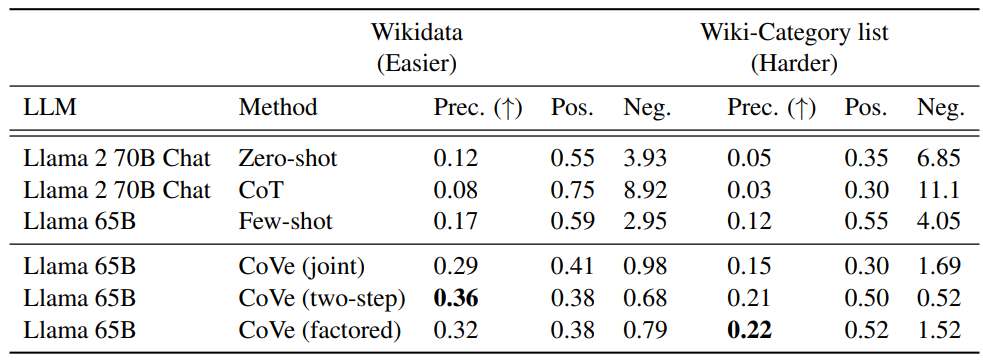
그림 2. CoVE Wiki-Category List 성능 비교
CoVE는 Wiki-Category List에서 Hallucination을 개선하면서 향상된 성능을 보였다.
다음으로 살펴볼 논문은 “Query Rewriting for Retrieval-Augmented Large Language Models”이다. 해당 논문에서는 RRR(Rewrite-Retrieve-Read) 방법을 제안하였다. 아래의 그림은 기존 방법과 RRR 방법의 차이를 나타낸 그림이다.
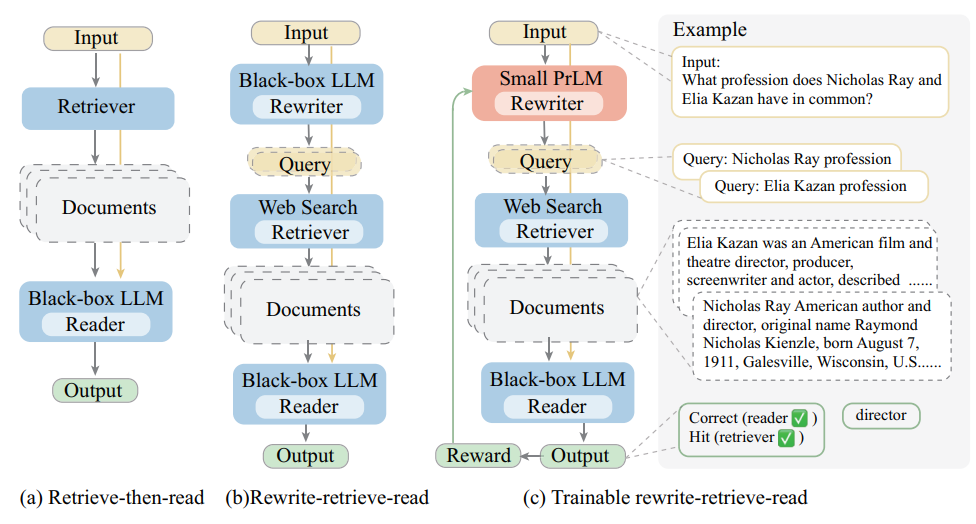
그림 3. RRR 방법과의 차이 비교
위의 그림에서 (a)는 Retrieve-then-read 방법으로 가장 일반적인 RAG 방법의 구조라고 볼 수 있다. Retriever의 과정에서는 Web Search API와 같은 방법도 사용될 수는 있지만, 일반적으로 벡터 검색과 같은 방법이 사용된다.
(b), (c)는 해당 논문에서 제안하는 RRR 방법을 나타낸다. 해당 방법에서는 Retriever로 Web Search API를 사용한다. Web Search는 좋은 결과를 얻기 위해 검색 쿼리를 구성할 때, 벡터 기반 검색과는 조금 다른 방법이 필요하다. 예를 들어 “대한민국에서 겨울에 올림픽을 개최했던 도시랑 연도는 무엇인가요?”와 같은 질문을 할 때, 네이버나 구글에 검색할 때는 “대한민국 겨울 올림픽 도시 연도”와 같은 쿼리를 입력할 수 있다. RRR에서는 검색 결과를 최대한 개선할 수 있도록 쿼리를 수정해주는 Rewriter를 도입하고, Rewrite된 쿼리를 검색엔진에 입력하여 답변에 필요한 문서를 얻는 방법이다.
여기서 (b)와 (c)의 차이는 Rewriter에 어떤 모델을 사용하는지의 차이라고 볼 수 있다. 예를 들어 답변 생성을 위한 LLM에 gpt-4o를 사용한다고 가정하자. 그러면 (b)의 방법에서는 gpt-4o에 적절한 프롬프트를 추가해서 Rewriter를 구현하게 된다. 해당 방법에는 추가적인 모델의 학습이 이루어지지 않는다.
(c)의 방법에서는 Rewriter 모델로 학습이 가능한 크기의 Samll-PrLM을 도입하고 Reward 기반의 강화학습을 통해서 해당 Rewriter 모델을 학습한다.
Rewriter 모델의 Small-PrLM으로는 T5 모델이 선택되었다. 해당 T5 모델을 바로 강화학습에 적용하는 경우 T5 모델이 Rewrite Task에 전혀 학습이 되지 않은 상태이므로 학습이 잘 되지 않을 가능성이 매우 높다. 이에 pseudo dataset을 구축하고, 이를 통해 먼저 학습을 시켜서 query rewrite 태스크에 적응되도록 하였다. pseudo dataset는 LLM에 원본 질문을 입력하고 pseudo label을 생성하도록 하는 방법으로 구축되었다.
Rewriter의 강화학습에는 PPO가 적용되었다. Reward는 최종 Output을 평가하여 적용하는데, 예를 들어 LLM reader의 예측에 관한 평가 점수 등이 될 수 있다.
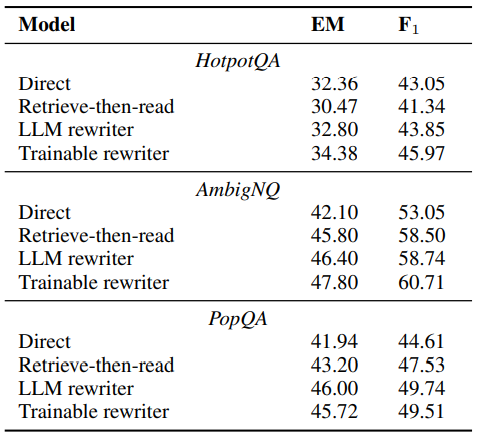
그림 4. RRR 모델 성능 비교
RRR의 성능을 살펴보면, Task에 따라서 LLM을 Rewriter로 사용하는 방식이 가장 높은 성능을 보이거나, 학습 가능한 Small-PrLM을 Rewriter로 사용한 모델이 가장 좋은 성능을 보이는 것이 달라지는 것을 확인할 수 있다.
다음으로 살펴볼 논문은 “Precise Zero-Shot Dense Retrieval without Relevance Labels”이다. 해당 논문에서 소개하는 HyDE는 Relevance Supervision 없이도 효과적으로 정보 검색을 수행할 수 있는 Zero-shot Dense Retrieval 방법을 제안했다. 해당 논문에서는 Supervision 데이터나 정보를 이용하지 않기 때문에, Self-Supervsied Representation Learning 방법을 이용한다.
아래의 그림은 HyDE 모델의 구조를 나타낸다.
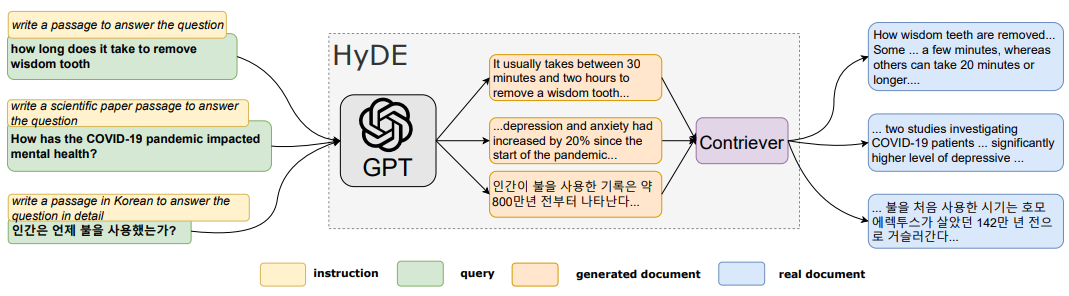
그림 5. HyDE 모델의 구조
위의 그림을 살펴보면, Query를 먼저 GPT에 입력하여 질문에 대한 답을 생성한다. 그리고 생성된 Document를 contreiver에 입력하고 질문의 답변에 필요한 진짜 Document를 얻게 된다. LLM을 통해서 RAG를 실행하지 않고 질문에 대한 답을 생성하게 되면 GPT는 부정확하거나 Hallucination을 다소 포함할 수 있더라도 어떻게든 답변을 생성하게 된다. 논문에서는 이러한 문서들을 Hypothetical Document로 부르고 있다. 기존 방법에서는 Query를 Retriever에 입력하여 답변에 필요한 Document를 탐색하는 것과 다르게, Hypothetical Document를 Contriever에 입력하여 답변에 필요한 Document를 찾게 된다.
그렇다면 HyDE는 왜 Zero-shot Dense Retrieval에 활용되는 것일까?
Supervision 데이터가 없는 학습 환경에서는 Query를 입력하여 얻은 벡터를 통해서 적절한 Document를 검색하는 것이 매우 힘들다. 두 데이터의 형태나 구조는 엄연히 다르고, Supervision 데이터를 통해 충분히 학습을 하여 해당 두 데이터가 높은 Similarity를 가질 수 있도록 해야하기 때문이다. 하지만, HyDE와 같이 Query를 Hypothetical Document로 변환하여 검색을 진행하게 되면 그래도 Hypothetical Document와 Real Document는 비교적 비슷한 구조의 데이터이므로 Hallucination이 포함될 수 있는 세부적인 내용이 조금 다르더라도 원하는 데이터가 더 잘 검색될 확률이 높아지게 된다. 예를 들어 “서울에서 언제 올림픽이 개최되었나요?”라는 질문을 Hypothetical Document로 변환하는 경우, “서울에서 2020년 올림픽이 성공적으로 개최되었습니다.”라는 문장이 생성될 수 있다. 실제 데이터에서 “서울 올림픽은 1988년 9월 17일 개최되었습니다.”라는 문장이 있을 때, 정확한 시기는 Hallucination으로 인해서 다를 수 있지만 전체적인 형태나 구조는 비슷하기 때문에 해당 문장을 Supervision 데이터를 이용한 학습 없이도 더 잘 찾을 가능성이 높아지게 된다.
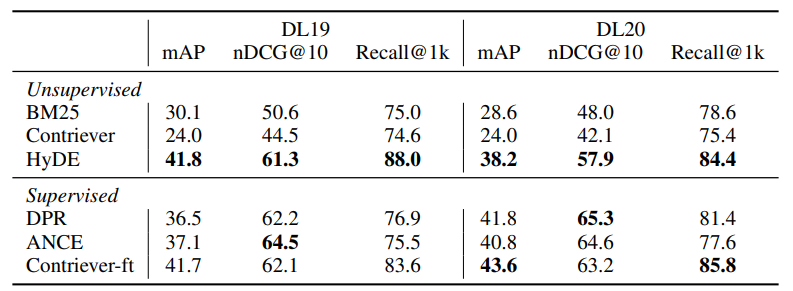
그림 6. HyDE 모델 성능
마지막으로 살펴볼 논문은 “Large Language Model based Long-tail Query Rewriting in Taobao Search”이다. 해당 논문은 Taobao 검색 엔진에서의 Long-tail Query 성능 개선을 위한 Query Rewrite 방법인 BEQUE 모델을 소개한 논문이다.
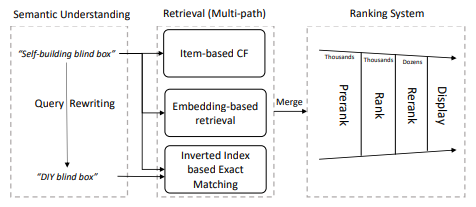
그림 7. 타오바오 검색엔진의 구조
해당 논문에서는 위의 그림에서 나타내고 있는 타오바오 검색엔진을 이용한 방법을 제안하고 있다. 아래의 그림은 BEQUE 모델의 전체적인 구조를 나타낸다.
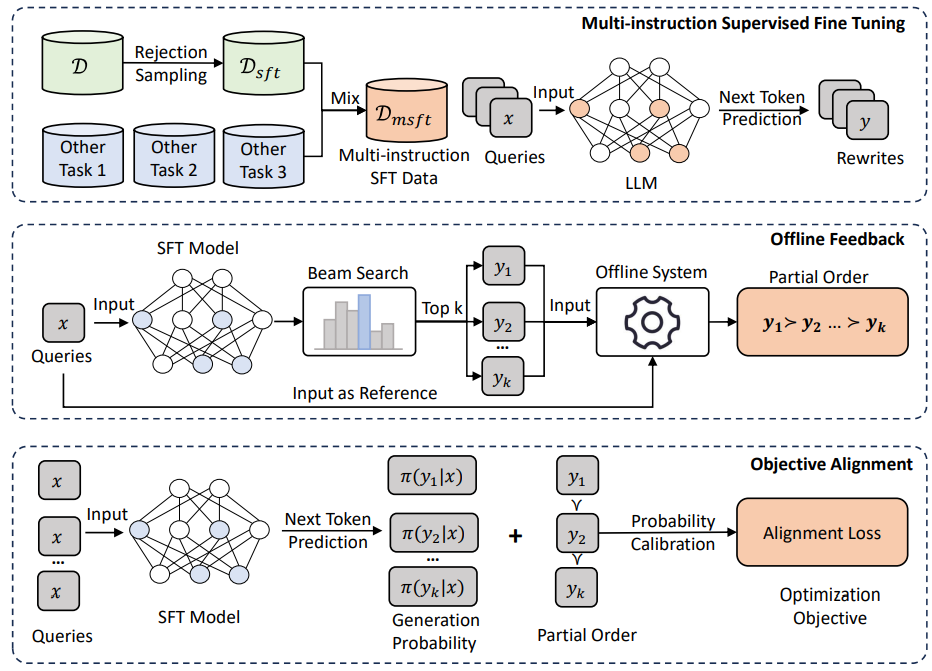
그림 8. BEQUE 모델의 전체적인 구조
BEQUE 모델에서는 우선 Query Rewrite 모델 학습을 위한 데이터셋을 구축한다. 이때, 데이터셋을 구축하기 위해 Rejection Sampling 방법이 활용된다.
이전 단계에서 만들어진 데이터셋을 이용해서 LLM을 학습시켜서, Rewrite 태스크를 수행할 수 있도록 한다.
이전 단계에서 학습된 LLM을 통해서 Beam Search를 통해서 Rewrite된 Query들의 후보 데이터를 생성한다.
생성된 후보들은 타오바오 검색 시스템을 통해서 순위를 매긴다.
매겨딘 순위는 Objective Alignment의 PRO(Preference Rank Optimization)를 통해서 학습을 하여 모델을 업데이트 한다.
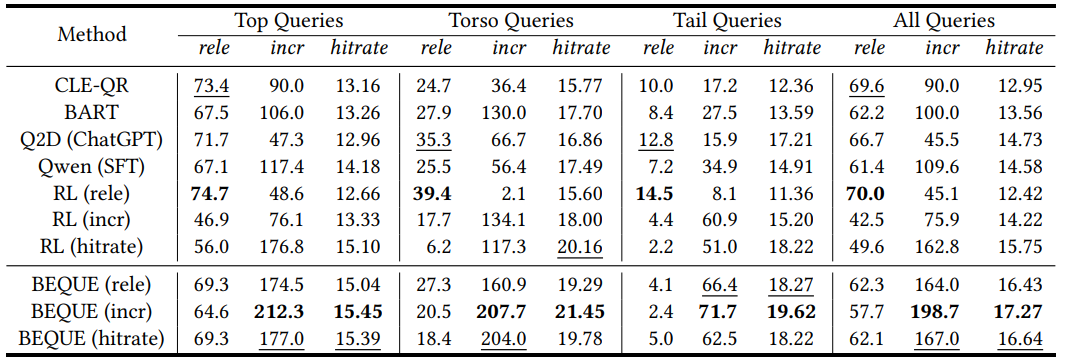
그림 9. BEQUE 모델의 성능
오늘은 “Retrieval-Augmented Generation for Large Language Models: A Survey”에서 소개된 논문들 중 Query Optimization에 관한 논문들을 살펴보았다. RAG 혹은 RAG와 유사한 시스템에서 Query Optimization은 주로 Retriever 단계에서의 성능을 개선하기 위해 Query를 변형하는 형태로 많이 적용된 것을 확인할 수 있었다.