오늘 리뷰해볼 논문은 RAG를 위한 파인튜닝과 관련된 논문들이다.
1.RAFT: Adapting Language Model to Domain Specific RAG
2.DUETRAG: COLLABORATIVE RETRIEVAL-AUGMENTED GENERATION
3.ATM: Adversarial Tuning Multi-agent System Makes a Robust Retrieval-Augmented Generator
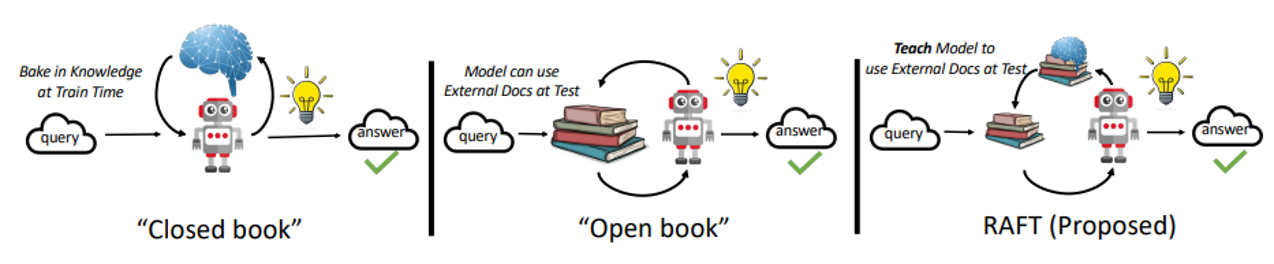
일반적으로 LLM을 활용하는 방법으로는 In-Context Learning을 하는 방법과 Fine-Tuning을 하는 방법이 있다. RAG는 검색된 결과를 컨텍스트에 포함시키고 해당 컨텍스트를 참조하여 답변하도록 하는 일종의 In-Context Learning으로도 볼 수 있다. RAFT의 저자는 RAG를 시험에 나올 자료를 미리 프린트해서 갖고가서 시험을 보는 오픈북 시험, Fine-Tuning을 클로즈드 북 테스트로 비유하고 있다. 그렇다면 RAG를 이용할 때는 Fine-tuning은 전혀 효과가 없는걸까? 그렇지 않다. 실제로 사람이 오픈북 시험을 보더라도 가볍게 관련 자료의 내용을 미리 정리한다던지 전체적인 구조를 공부하고 간다면 더 좋은 시험 결과를 얻을 수도 있을 것이다. RAFT에서는 RAG를 위한 적절한 파인튜닝 레시피를 제안하고 있다.
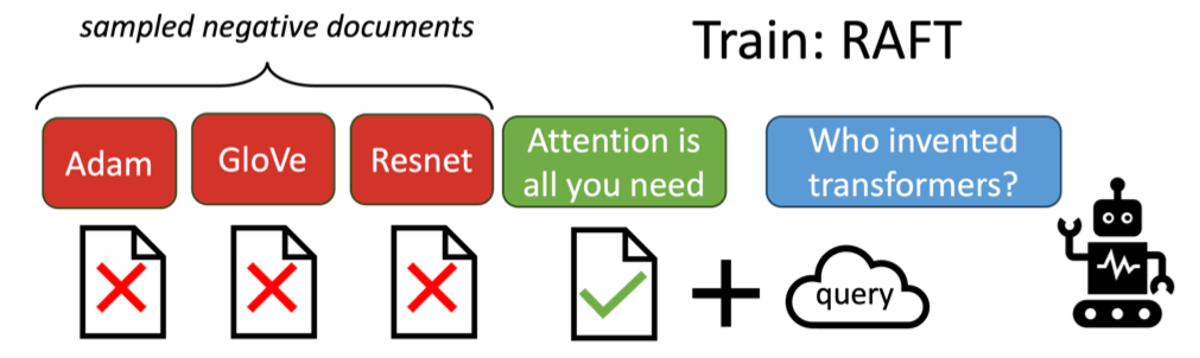
일반적으로 RAG를 파인튜닝 할 때는 정답이 존재하는 문서를 입력으로 주고 정답을 생성하도록 한다. 가끔 정답이 존재하는 문서 외에 정답이 없는 문서를 넣기도 한다. 하지만, 실제 사용에서는 Retrieval 시스템이 항상 정답을 도출할 수 있는 완벽한 컨텍스트를 찾아주는 것은 아니다. 그렇기 때문에 컨텍스트가 제대로 갖추어지지 않았을 때도 강건한 모델을 학습시키기 위해서는 정답이 없는 Negative 샘플들만 입력하여 정답을 도출하도록 학습시키는 과정도 필요하다.
해당 논문에서는 태스크에 따라서 조금씩 다르지만, 학습 데이터의 60%는 정답이 있는 문서와 없는 문서를 같이 조합한 컨텍스트를 이용하고 학습을 시키고, 나머지 40%는 정답이 없는 문서들만으로 컨텍스트를 구성하여 정답을 생성하도록 학습하였을 때 좋은 결과를 얻었다고 하였다.
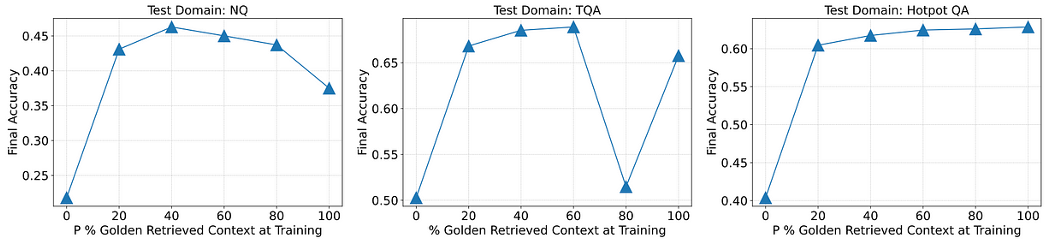
위의 그림에서 P%는 정답이 포함된 컨텍스트 데이터의 비율을 나타낸다.
다음으로 DuetRAG는 RAG의 성능을 개선하기 위한 방법을 제안하고 있는 논문이다. RAFT와 마찬가지로 해당 논문도 Retrieval의 결과가 잘못되었을때도 강건한 모델을 학습하기 위한 방법을 제안하고 있다. 아래의 그림은 제안하고 있는 방법을 전체적으로 나타낸 그림이다.
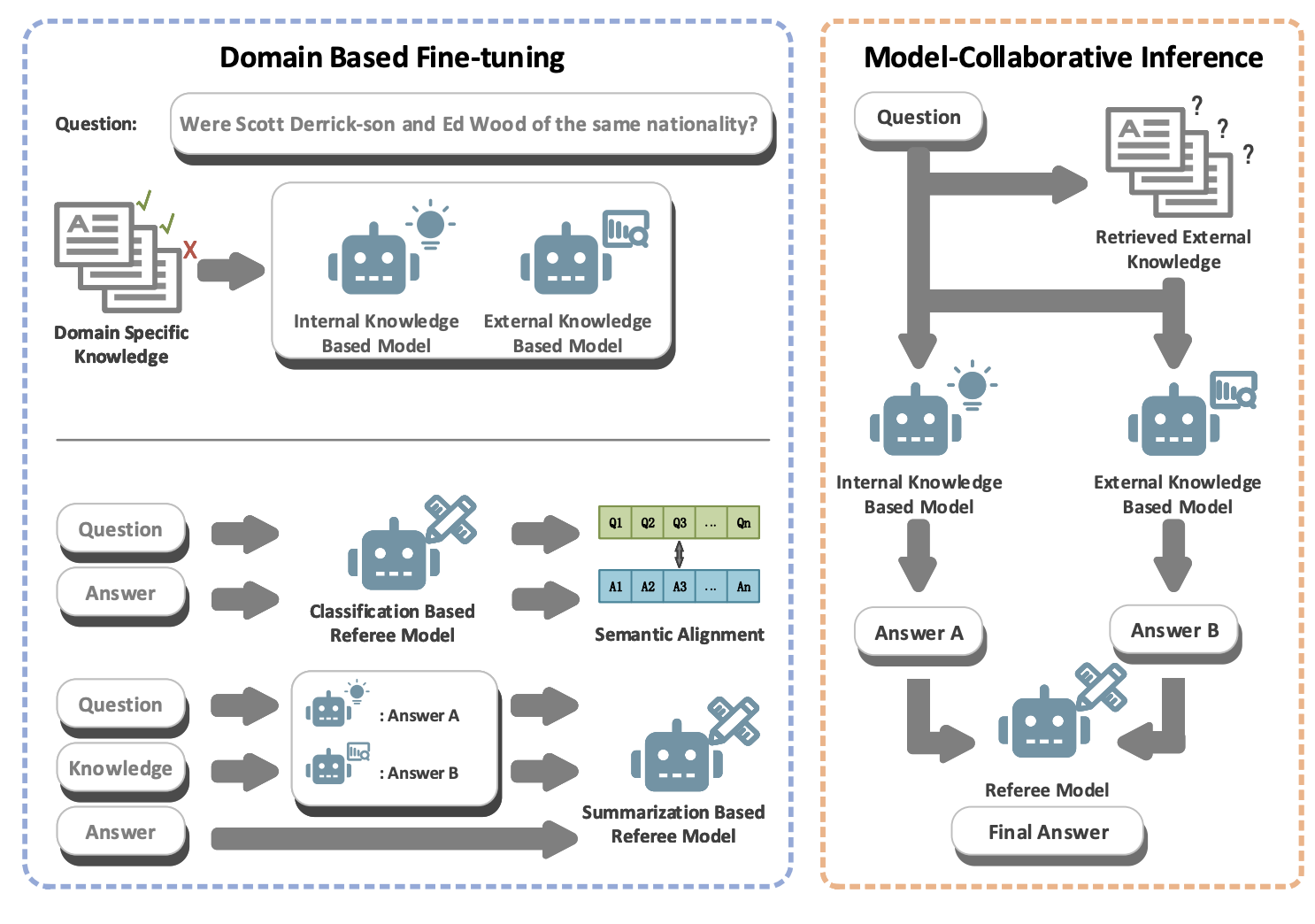
그림 1. DuetRAG의 전체적인 구조
DuetRAG는 이름에서 알 수 있듯이 Internal-Knowledge를 사용하는 모델1(closed-book test), External-Knowledege를 사용하는 모델 2(open-book test)의 두 가지 모델을 조합하여 사용하는 방법이다. 그리고 이 두 모델을 적절하게 이용하기 위해서 Referee 모델이 사용된다. Referee 모델은 Classification 모델과 Summarization의 2가지 종류의 모델이 사용될 수 있는데, Classification은 정답 텍스트와 질문 텍스트 간의 Semantic Alignment를 수행한다. Summarization 모델은 두 가지 모델(Internal, External)의 답변을 입력받고 요약하여 하나의 답변을 선택하도록 파인튜닝된다.
즉, 분류 모델을 이용할 때는 Semantic Alignment를 이용하여 질문과 답변의 연관성을 예측하도록 학습시키고, 실제 Inference에서는 Confidence Score가 더 높은 답변을 최종 답변으로 선택하게 된다. 만약 요약 모델을 이용한다면 두 모델의 답변을 입력하고 요약하도록 하여 최종 답변을 생성하게 된다.
마지막으로 살펴볼 논문은 ATM이다. ATM은 GAN의 컨셉을 이용하여 RAG를 위한 파인튜닝을 한 논문이다. 아래는 ATM 모델의 전체 구조이다.
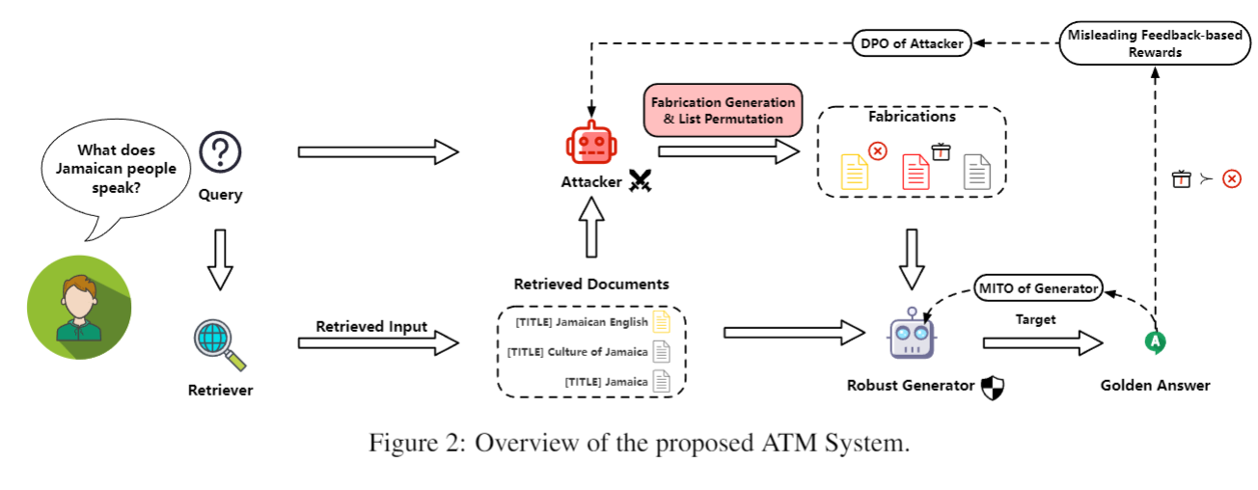
ATM 모델에는 Attacker라는 모델이 있는 것을 살펴볼 수 있는데, 학습 과정에서 Attacker는 정답을 생성하는 LLM이 정답을 생성하기 어렵게 검색된 Documents를 위조하게 된다. 그러면 LLM Generator는 위조된 컨텍스트를 받더라도 정답을 잘 생성하도록 파인튜닝된다.
LLM이 정답을 생성하기 어렵도록 컨텍스트를 위조하는 것 외에 검색된 문서의 입력 순서도 뒤바꾸는 작업을 하는데, 이는 잘 알려졌듯이 컨텍스트에서 입력되는 순서에 따라서 LLM이 참조하는 정도가 달라지는것을 최대한 방지하도록 튜닝하기 위함이다.
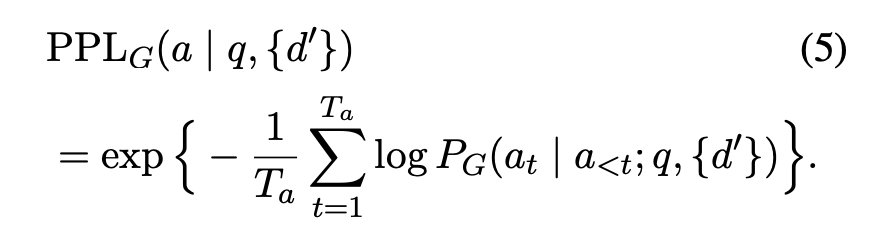
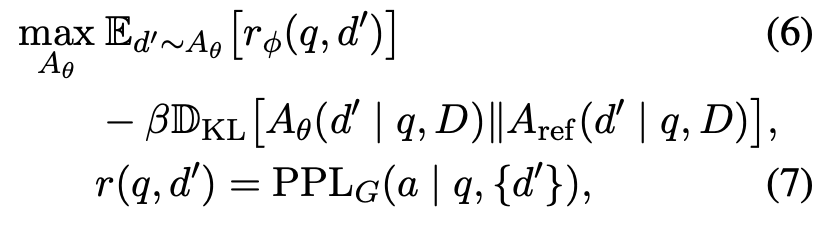
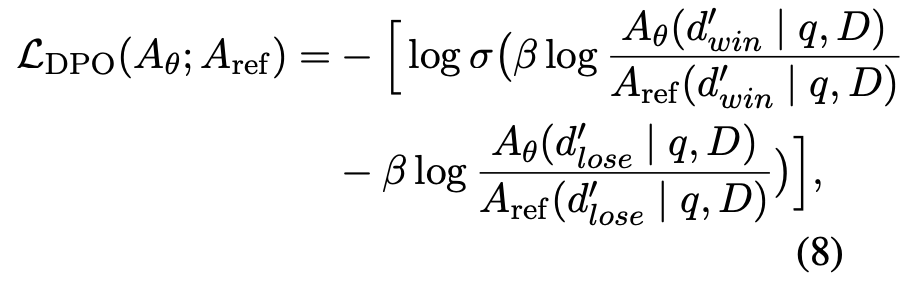
위의 수식은 Generator가 잘 예측하지 못하도록 ‘잘’ 위조 하기 위한 Attacker의 학습 방법을 나타내는 수식이다. 수식 5는 Generator의 정답 텍스트를 생성하기 위한 PPL을 나타내는데, 이 PPL을 낮게 만드는 Context를 만드는 것이 Attacker의 목적이라고 볼 수 있다. Attacker는 Initial Model에서 샘플링한 높은 PPL을 주는 샘플을 만들고, Iterative하게 학습중인 Attacker에서 낮은 PPL을 가지게 하는 데이터를 샘플링하여 각각을 Lose, Win 샘플로 사용하여 DPO 학습을 하게 된다.
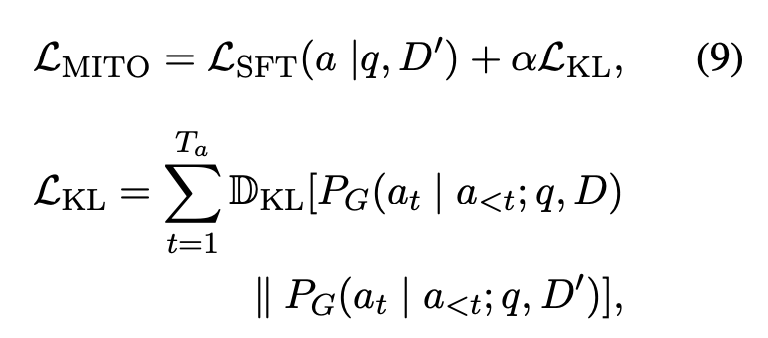
마지막으로 위의 수식은 Generator를 학습시키기 위한 수식이다. Loss SFT는 위조된 컨텍스트를 입력받아 정답을 생성하도록 하는 로스라고 보면 되는데, Loss KL은 위조된 컨텍스트를 입력받아서 정답 토큰을 생성하는 분포와 위조되지 않은 컨텍스트를 입력받아서 정답을 생성하는 분포 간의 차이를 최소화하기 위한 Kullback Divergence를 이용한 손실 함수이다.
ATM은 Attacker와 Generator를 Iterative하게 학습하게 된다.
이번 글에서는 RAG를 위한 파인튜닝 방법을 다루고 있는 다른 컨셉의 3가지 논문을 살펴보았다. RAFT는 컨텍스트에 정답을 포함하고 있는 오라클 문서가 없을 때에도 강건하게 학습하기 위한 방법 레시피를 제안했다. DuetRAG에서는 Referee 모델을 이용해서 파인튜닝 모델과 RAG 모델의 답변을 상황에 맞게 선택하여 사용하도록 하였다. ATM에서는 Attacker 모델을 만들어서 Generator가 위조된 컨텍스트에서도 정답을 생성하도록 학습하여 더욱 강건한 모델을 학습하였다.