오늘 간단하게 소개할 논문은 “PROMPTAGATOR : FEW-SHOT DENSE RETRIEVAL FROM 8 EXAMPLES”이다.
해당 논문은 Supervision 데이터셋이 없는 환경에서 학습을 해야 하는 “Few-shot Dense Retrieval” 태스크를 다루고 있다.
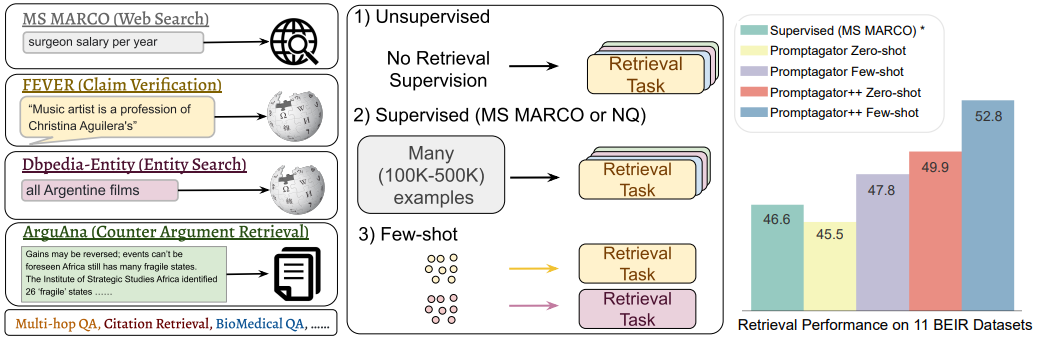
그림 1. 다양한 Retriever 모델 비교 및 Promptgator 모델의 성능 비교
Retrieval 방법으로는 Unsupervised, Supervsied, Few-shot의 3가지 방법이 있다. Unsupervised는 아예 학습 레이블이 부착된 데이터를 사용하지 않는 경우이고, Few-shot은 매우 적은 수의 학습 데이터만을 사용하는 경우이다. 해당 논문에서는 8개의 학습 데이터만을 활용하는 거의 Zero-shot에 가까운 Few-shot Retrieval 방법을 제안하고 있다.
Retrieval을 필요로 하는 태스크들은 위의 그림과 같이 다양한 태스크 및 도메인에서 존재할 수 있다. 만약 어떠한 도메인 및 태스크의 데이터셋에서 레이블이 부착된 학습 데이터셋을 충분히 갖추고 있지만, 새로 적용하려는 도메인이나 태스크에서 학습 데이터셋이 없다면 일반적으로 Domain Adaptation과 같은 전이 학습 방법을 주로 사용해왔다. 하지만 해당 논문에서는 “8개 이하의 소수의 예제 데이터만으로도 Retrieval 태스크를 학습시킬 수 있을까?”라는 질문으로 부터 시작하여 전이학습 대신 매우 적은 수의 예제만을 가지고 해당 태스크나 도메인에서 잘 동작할 수 있는 Retriever 모델을 학습하는 PROMPTGATOR 모델을 제안하였다.
해당 논문의 실험에서는 9개의 도메인의 18개 데이터셋으로 구성된 BEIR 데이터셋을 활용하였다. few-shot 예제 데이터셋은 각 데이터셋의 in-domain 데이터셋의 Query-Document 쌍의 예제를 만들어서 활용하였다.
PROMPTGATOR는 “Prompt-base Query Generation for Retriever”의 약자이다. few-shot 예제를 입력받아서 LLM의 프롬프트를 구축하고, 해당 프롬프트를 입력받은 LLM을 통해서 Retriever를 학습시키기 위한 더 많은 데이터셋을 구축하는 방법이다.
PROMPTGATOR는 다음과 같은 Component들로 이루어져 있다: “prompt-based query generation, consistency filtering, retriever training”
Prompt-based Query Generation
prompt-based query generation 과정에서는 8개 이하의 in-domain 예제로 구성된 프롬프트와 in-domain 데이터셋의 Document를 LLM에 입력하고 입력된 Document에 맞는 Query를 생성하는 단계이다.
Query를 생성하기 위한 LLM으로는 137B 크기의 FLAN 모델을 활용하였다.
Consistency Filtering
Consistency Filtering 과정에서는 합성된 데이터셋의 퀄리티를 높이기 위해서, 이전 Prompt-based query generation 과정에서 생성한 데이터 중 Consistency가 낮은 데이터들을 필터링하는 단계이다.
필터링하는 방법으로는 학습된 Retriever를 이용해서Retrieval 태스크를 수행시켜서, Top-K 안에 합성된 Query에 맞는 Document가 존재하면 해당 데이터를 필터링하지 않고 데이터셋에 포함시키는 방법이다.
그런데 해당 과정에서는 이미 어느정도 Retrieval 태스크를 수행할 수 있는 학습된 모델이 필요한데, 8개 이하의 few-shot 데이터만 활용하는 환경에서 어떻게 해당 모델을 얻을 수 있었을까?
학습된 Retriever가 없는 가장 첫 번째 학습 단계에서는 필터링이 적용되지 않은 합성된 데이터만을 이용해서 Initial Retriever를 학습하고, 다음 Epoch 부터 해당 모델을 활용해서 필터링을 수행하였다고 한다.
해당 논문의 저자들도 노이즈가 많이 포함된 필터링 되지 않은 데이터셋을 Initial Retriever로 사용해도 괜찮을지 반신반의 하였지만, 실제 실험에서는 필터링 되지 않은 합성 데이터로 Initial Retiever 모델을 학습했음에도 다음 Epoch의 필터링 과정에서 효과적으로 적용될 수 있었다고 하였다.
(Consistency Filtering은 Roundtrip Filtering을 제안했던 논문(Synthetic QA Corpora Generation with Roundtrip Consistency)의 방법을 Retriever에 맞게 적용한 방법이다. 아래의 그림은 Roundtrip filtering을 이용한 합성 데이터 생성 방법 예시를 나타낸다.)

그림 2. Roundtrip Consistency를 이용한 합성 데이터 생성 예시
Retriever Training
retriever training에서는 Consistency Filtering 과정을 통과한 합성 데이터셋을 이용해서 Retriever를 학습하게 된다. PROMPTGATOR는 해당 세 가지 단계를 계속 거쳐서 모델의 성능을 향상시킨다.
Bi-Encoder 모델의 경우, T5 모델에서 인코더 부분 만을 사용하였다. 또한 C4 데이터셋에 independent cropping 태스크를 적용하여 Retriever 모델을 사전학습하였다.
해당 논문에서는 Reranker 모델에도 이러한 방법을 적용한 PROMPTGATOR++ 방법도 제안하였다.
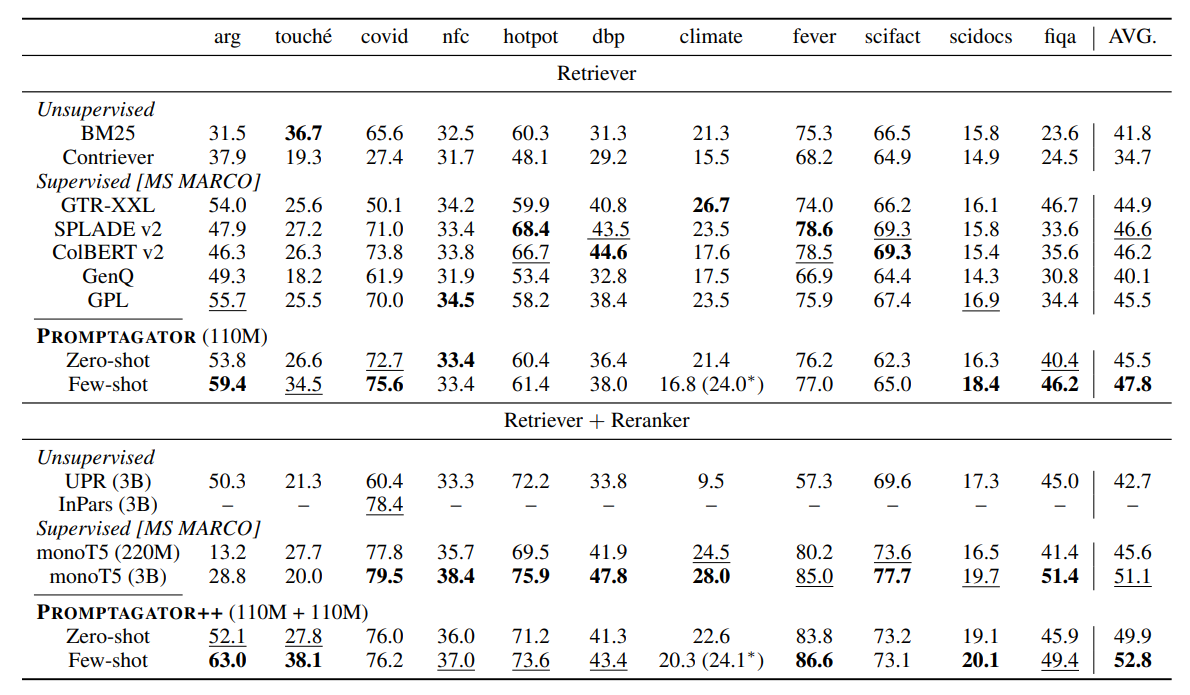
그림 3. PROMPTGATOR 모델의 성능
오늘은 few-shot 학습 데이터셋만을 이용해서 Retriever 모델의 학습에 필요한 데이터셋을 생성하여 새로운 도메인이나 태스크에 최적화된 Retriever를 학습하는 PROMPTGATOR 모델을 살펴보았다.
이러한 태스크의 적용이 가능하게 된 것은 적은 예제만으로도 다양한 태스크를 수행할 수 있는 LLM의 성능 덕분인 것 같다. 해당 방법은 활용도가 높은 좋은 접근 방법이라고 생각한다.