오늘 살펴볼 논문은 “Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection”과 해당 논문의 기반이 되는 “Parallel Context Windows for Large Language Models “이다.
우선 PCW(Parallel Context Window)는 기존의 LLM에서 In-context Learning을 위해 매우 긴 길이의 컨텍스트 데이터를 사용할 때 발생하는 문제들을 해결하기 위한 방법이다.
Transformer 기반의 모델은 Self-Attention 매커니즘을 적용하기 때문에 긴 길이의 컨텍스트를 사용하게 되면 메모리의 사용량이 Quadratic하게 증가하게 된다.
PCW는 아주 간단한 방법으로 이를 해결했다. 전체 입력의 길이가 N이라고 가정하자. 그러면 긴 컨텍스트를 더 작은 Chunk 단위로 쪼개어 K의 길이만 가지도록 한다. 그러면 컨텍스트 데이터는 B개의 Chunk로 쪼개지게 된다.
N = B * K + T로 전체 입력 길이를 나타낼 수 있다. 여기서 T는 태스크와 관련된 토큰(직접적인 프롬프트)의 길이이다.
PCW는 Position 임베딩과 Attention Mask를 수정하는 것 만으로 긴 컨텍스트 데이터를 사용할 때 발생하는 문제를 해결하였다.
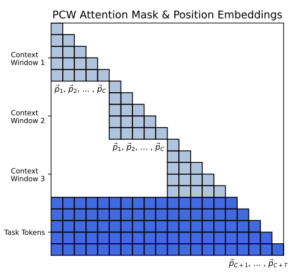
그림 1. PCW 방법의 구조
위의 그림은 PCW에서 적용한 방법을 그림으로 나타낸 것이다. 우선 Position Embedding의 경우, N의 길이의 입력을 사용하게 되면 0~N-1의 Position Embedding이 사용된다. 하지만 PCW 방법에서는 쪼개진 각 Chunk마다 Position Embedding을 초기화하고 재사용한다. 그렇기에 나타나는 Position Embedding의 범위는 0~K+T-1이 된다. 하지만 이렇게 되면 하나의 입력에서 같은 Position의 토큰이 반복해서 나타나게 되고, 이러한 데이터를 접한적 없는 모델은 이러한 입력으로 인해서 성능에 악영향을 받을 수 있다. 이를 위해 PCW에서는 Attention mask 제어를 추가하였다.
위의 그림 1을 살펴보면 다른 컨텍스트 Chunk끼리는 서로 Attention이 attend되지 않도록 attention이 제한되고 있는 것을 살펴볼 수 있다. 이렇게 되면 각 컨텍스트 데이터를 인코딩할 때, 서로 참조가 되지 않으므로 Position Embedding이 겹치는 문제가 해결된다. 또한 Sparse한 어텐션을 사용하게 되면서 컨텍스트의 길이는 늘어나더라도 Chunk의 길이는 고정되기 때문에 구현 단계에서 이러한 부분을 반영하면 메모리가 컨텍스트 길이에 따라서 Quadratic하게 증가하는 것을 막을 수 있다.
최종 답변을 생성할 때는 나눠진 모든 Chunk의 내용을 통합해서 활용해야 하기 때문에 Task와 관련된 토큰에서는 토큰 컨텍스트에 Attention이 할당가능하도록 설정되어 있다.
“Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection”과 해당 논문의 기반이 되는 “Parallel Context Windows for Large Language Models “에서 제안하고 있는 Sparse RAG 방법에서는 이러한 PCW를 활용한 RAG 구현 방법을 제안하고 있다.
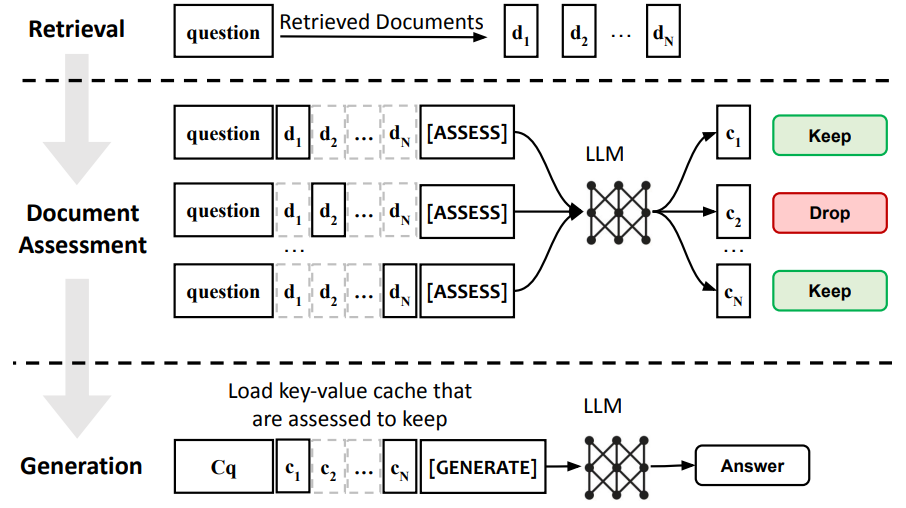
그림 2. Sparse RAG 모델 구조
위의 그림은 Sparse RAG 모델의 전체적인 구조를 나타낸다. RAG 시스템을 구현하다보면 항상 많이 발생하는 문제는 Retrieval 단계에서 검색된 Chunk에 불필요한 내용이 필수적으로 많이 포함이 된다는 것이다. 답변을 하는 디코더 모델이 해당 Chunk를 잘 무시하면 좋겠지만, 그렇지 못하여 불필요한 답변을 추가로 생성하거나 혹은 아예 불필요한 내용만을 참조하는 문제가 생기게 된다. Sparse에서는 Document Assesment 과정을 통해서 답변에 불필요한 Chunk들을 솎아내는 과정을 추가하였다. 이때 특수한 토큰을 생성하도록 해서 해당 토큰의 생성 확률을 통해서 해당 Document를 살릴지 버릴지 결정하게 된다. 이때 좀 전에 소개했던 PCW 방법을 이용한다.
해당 논문에서는 불필요한 컨텍스트를 솎아내는 과정을 PCA(Per Context Assesment)로 정의하였다. PCA를 통해서 컨텍스트를 선별하고 나면, 선별된 컨텍스트의 KV cache만 불러와서 최종 정답 생성에 활용하게 된다.
Assesment 태스크 학습을 위한 Golden Tagging 데이터셋이 따로 공개가 되어 있지 않았기 때문에 PALM과 Gemini의 예측 결과를 Label로 이용하여 PCA 태스크 학습을 진행하였다.
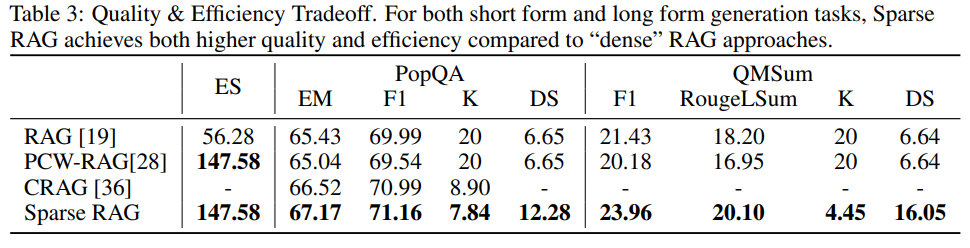
그림 3. Sparse RAG 성능 비교
위의 그림은 Sparse RAG의 성능 비교 결과를 나타낸다. 단순하게 PCW만 RAG에 적용했을 때는 오히려 성능이 소폭 감소하였지만, PCW의 방법을 이용하여 PCA 과정을 추가한 Sparse RAG는 기존 RAG 시스템보다 성능이 소폭 향상된 것을 확인할 수 있다. Sparse RAG에서는 PCA 과정을 통해서 프롬프트 내에 불필요한 컨텍스트가 포함되는 것을 방지할 수 있었다.