이번에 정리해볼 논문은 OTTQA(Open Table Text Question Answering)에 관한 논문이다.
우선 Open Domain QA는 Closed Domain QA와 다르게 질문이 주어지고 질문에 대한 정답과 정답을 찾을 수 있는 단서 등이 제공되지 않고 질문과 정답을 찾기 위한 단서를 탐색하고 탐색된 단서에서 최종적인 정답을 찾아내는 태스크이다. 일반적으로 해당 태스크는 텍스트 문서에 대한 데이터셋들이 많이 만들어져 있으며, 이전 블로그 포스팅에서 정리했던 내용과 같이 테이블 데이터에 대해서도 연구가 진행되어 왔다. 이 논문은 표와 텍스트를 동시에 탐색하여 정답을 출력해야 하는 태스크인 HybridQA(HybridQA: A Dataset of Multi-Hop Question Answering over Tabular and Textual Data) 데이터셋을 변형해서 표와 테이블 데이터를 동시에 활용하는 오픈 도메인 QA 태스크를 제안하였다.

그림 1. OTT-QA 아키텍쳐 – 질문이 입력되었을 때 위키피디아의 표와 텍스트 단락들을 탐색하여 정답 혹은 정답 추론에 필요한 단서들을 탐색하고 탐색된 문서를 기반으로 정답을 출력

그림 2. Hybrid QA 데이터셋 예시
먼저 그림 2의 Hybrid QA를 살펴보면 테이블 내에서 정답을 찾을 때 정답 추론에 필요한 단서들은 텍스트 단락에 포함되어 있는 질문-정답 셋들이 포함되어 있다. 예를 들어 “in which year did the judoka bearer participate in the Olympic opening ceremony?”라는 질문에서 Flag bearer가 Judoka(유도선수)라는 사실을 파악하기 위해서는 위키피디아 링크로 연결되어 있는 Yan Naing Soe 문서의 텍스트 단락을 함께 확인해야 한다. Hybrid QA에서는 질문과 질문에 관한 정답이 주어지면 해당 정답을 찾기 위해 필요한 테이블, 그리고 테이블과 링크로 연결되어 있는 텍스트 문서를 제공한다. 하지만 OTT-QA에서는 정답 단서가 제공되지 않기 때문에 정답 추론에 필요한 테이블과 텍스트를 전체 위키피디아 문서 내에서 탐색하고 탐색된 문서 내에서 최종적인 정답을 찾아야 한다.
OTT-QA를 살펴보면, QA를 위한 모델은 Retriever 모델과 Reader 모델의 2가지 모델이 필요하다. Retrieval 과정에서는 정답이 있을 수 있는 테이블 후보와 텍스트 단락 후보에 대해서 정답이 있을 만한 혹은 정답에 관한 단서를 가지고 있을만한 테이블과 텍스트 단락을 탐색한다. 테이블 후보는 약 40 만개의 데이터를 가지며, 텍스트 단락 후보는 약 5백만 개의 데이터를 가진다.

그림 3. De-contextualization
Hybird-QA 데이터셋을 이용해서 OTT-QA 데이터셋을 구축할 때, 기존의 질문을 그대로 사용하게 되면 많은 후보에서 모호한 의미를 가지기 때문에 질문 내에서 정답 단서와 정답을 포함하는 후보를 잘 찾을 수 있는 정보들을 추가해주는 작업이 필요하다. 위의 그림에서 Insertion 과정은 기존에 태깅되어 있던 테이블이나 텍스트 단락을 찾을 수 있도록 질문에 단서가 되는 단어들을 추가하는 작업이다. 기존 질문인 “Which city does the player winning the silver medal in Men’s Omnium come from”이라는 질문에서 남자 경기에서 메달을 딴 선수를 기록하고 있는 테이블은 여러 개가 있기 때문에 그 중에서 단서 테이블을 명확하게 구분할 수 있는 정보를 추가하는 것이다. 다음으로 Nauturalize 작업은 Insertion에서 끼워넣었던 구문이 문장에 자연스럽게 녹아들 수 있도록 문자의 구조를 수정하는 작업이다. OTT-QA는 위의 2가지 작업을 통해서 질문을 변형하여 구축하였다.
Distant Supervision: 이전 데이터셋인 Hybrid QA에서는 태깅된 테이블과 텍스트 단락에서 어디에 정답이 있는지를 태깅해두지 않았기 때문에 정답 텍스트와 매칭되는 모든 Span을 학습을 위한 정답 Span으로 사용하였다고 하였다. 다만 수 작업을 통해서 매칭되는 모든 Span을 정답 텍스트로 사용하였을 때 약 15%의 Span은 실제 정답이 아니었다고 하였다.
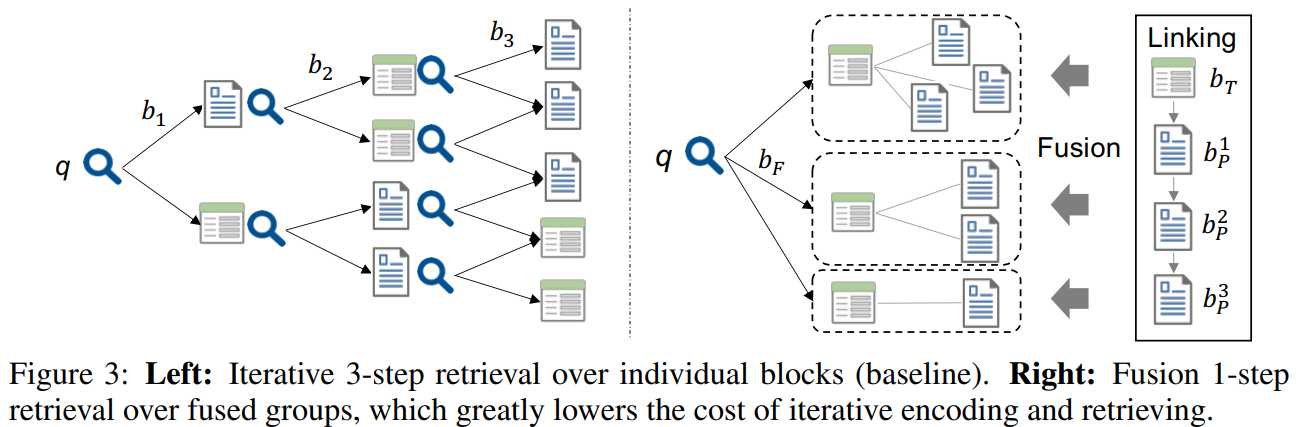
그림 4. Iterative Retrieval와 Fusion Retrieval 비교
Iterative Retrieval은 현재 Stage에서 찾은 정보를 기반으로 다음 Stage에서 찾은 정보를 이용해서 이어서 탐색을 하는 방법이다.(PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text)

그림 5. Iterative Retrieval 알고리즘
그림 5의 Iterative Retrieval 알고리즘을 간단하게 요약하면 처음 가지고 있던 엔티티에서 선택할 노드를 분류하고 임계값보다 높은 선택 확률을 가지는 엔티티 노드들을 선택한다. 선택된 노드의 엔티티의 문서에 연결된 엔티티들을 추출하고 여기서 Head, Tail을 추출한다. Question Graph에 새로운 노드와 엣지를 추가한다. 그리고 다음 Iteration에서 업데이트된 Question Graph를 통해서 이어서 탐색을 계속한다.
Iterative Retreival은 학습을 위해서 종종 Supervision Signal(학습을 위해 명확히 태깅된 정보)를 필요로 한다. 또한 순차적으로 진행되는 특성으로 인해서 Early Stage에서 잘못된 예측을 할 경우, Error Propagation이 발생할 수 있다. 마지막으로 Dual-Encoder를 이용할 때, Query Embedding이 Retrieval History에 따라서 매번 인코딩되어야 하므로, 모든 Stage를 실행하기 위한 Computation Cost가 비교적 높다.
이러한 단점을 극복하기 위한 Retrieval 방법으로 Fusion Retrieval 방법이 적용되었다. 데이터를 Retrieval 하는 과정에 앞서서 Early Fusion이라는 과정이 먼저 진행된다. Early Fusion은 그림 4의 Linking이라고 표시된 박스의 부분을 살펴볼 수 있는데 관련이 있는 Heterogeneous 데이터(텍스트 단락, 표)를 연결시켜서 그룹화시키는 작업이다. Table을 탐색할 때 문제는 테이블에서 데이터는 축약되거나 요약되는 정보들이 많기 때문에 불완전한 문맥(Incomplete Context)을 가지므로 이를 이용해서 어떤 정보를 검색하기는 힘들 수 있다. Early Fusion을 하면 테이블과 관련 있는 텍스트 단락들을 같이 연결해서 그룹화를 하게 된다. 그러면 그룹화된 데이터를 탐색하게 되면 연결된 텍스트 단락의 Context도 이용할 수 있으므로 필요한 정보를 찾는데에 더 유리할 수 있다. 여기서는 표를 기반으로 표에 언급되어 있는 엔티티의 문서의 텍스트 단락들을 함께 연결하는 방법으로 Early Fusion을 하였다. 이 방법은 문서 확장에서 Entity Linking을 이용해서 확장하는 방법을 이용한 것이라고 한다.
다만 여기에는 한가지 Challenging한 문제가 있는데 Cell에 “Penn State”라고 표기가 되어 있는 엔티티가 있을 때 이 텍스트를 기반으로 검색을 하면 Penn State University가 연결이 된다. 하지만 실제로 하이퍼링크로 연결된 문서는 “Penn State Nittany Lions Football”이다. 이러한 문제를 줄이기 위해서 이 논문에서는 GPT-2 모델을 이용해서 Augmented 된 Query를 생성하도록 하는 과정을 추가하였다. Augmented 된 쿼리는 BM-25를 통해서 가장 가까운 Passage 이웃을 찾는데에 사용된다.
Retrieval 모델의 성능을 높이기 위해서, 이전 포스팅에서 소개했던 ICT(Inverse Cloze Task)를 이용해서 사전학습을 하였다.

그림 6. Cross-Block Reader 구조 설명
Fusion Retrieval을 통해서 질문의 답변에 필요한 테이블 및 텍스트 단락들을 찾았다면 마지막 과정으로 찾은 단서 내에서 정답이 존재하는 위치를 정확하게 찾는 것이다. Single-Block Reader는 최대 입력 길이가 512인 인코더에 찾은 Fusion Block을 쪼개서 입력하고 각 입력에서 정답을 찾아서 최종 정답을 선택하는 것인데 이렇게 되면 Fusion Block에 있는 여러 단서들을 종합해서 정답을 찾는 것이 불가능하며, 그림 6에서와 같이 정확한 정답이 있는 입력에서 정답을 잘 찾았더라도 최종 정답을 선택하는 과정에서 잘못된 정답 후보를 선택할 수 있다. 이러한 문제를 해결하기 위해서 여기서는 긴 입력을 넣을 수 있는 BigBird 모델에 찾은 Fusion Block의 입력들을 한 번에 입력하고 정답 Span을 찾는 방법을 선택하였다. 이전 연구들에서는 Single Reader에서 정답을 찾을 때 같이 추론을 해야하는 Multi-Hop QA를 위한 여러가지 아키텍쳐들이 제안되었었는데, 이 논문의 실험 결과에 따르면 BigBird 모델을 이용해서 여러 Block을 한번에 입력했을 때 multi-hop 추론도 잘 동작하였다고 하였다.
요약하자면 본 논문에서는 Hybird QA 데이터셋을 개량해서 질문의 답변에 필요한 Table과 Text를 찾아내고 답변하는 Open Table-Text Question Answering(OTT-QA) 태스크 및 데이터셋을 제안하였다. 또한 Table-Text의 Heterogeneous한 데이터를 탐색할 때 발생할 수 있는 여러 문제를 고려해서 이에 적합한 Fusion Retrieval 방법을 이용하였으며, BigBird 모델을 이용해서 찾은 Fused Block의 세그먼트를 한 번에 입력하여 최종 정답을 찾는 방법을 선택하였다.