오늘 다룰 주제는 내재/외재 지식의 통합에 관한 것이다.
내재 지식은 LLM의 파라미터 내부에 내재하고 있는 지식들을 활용해서 질의응답을 수행하거나 어떠한 태스크를 수행하는 것을 의미한다.
예를 들어, 별도의 지식을 프롬프트로 제공하지 않고 Open-domain QA를 수행하는 것이 이에 해당한다고 볼 수 있다.
외재 지식은 LLM에 내재하는 지식이 아닌 외부 지식을 활용하여 질의응답을 수행하거나 어떠한 태스크를 수행하는 것을 의미한다.
RAG(Retrieval-Augmented Generation)이 이에 해당하는 가장 대표적인 예시라고 볼 수 있다.
하지만 Microsoft에서 나왔던 아래의 논문들과 같이, Finetuning을 통해 지식을 학습시키는 것 보다는 RAG와 같이 외부지식을 제공하는 것이 훨씬 효과적으로 필요한 지식을 LLM에 주입시키는 방법으로 알려져 있다.
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
- RAG VS FINE-TUNING: PIPELINES, TRADEOFFS, AND A CASE STUDY ON AGRICULTURE
그렇다면 왜 내재/외재하는 지식을 통합하는 Knowledge Consolidation이 필요할까?
추후 꾸준히 다루겠지만, RAG와 같이 프롬프트로 필요한 정보를 제공한다고 해서 LLM이 사용자가 원하는 방향으로 제공된 정보를 100% 수용하는 경우는 잘 없다. 불필요하게 Context를 맹신하거나, 혹은 분명히 Context에 필요한 정보를 제공했음에도 내재하는 지식에 매몰되어 부정확한 답변을 하는 경우도 존재한다. Knowledge Consolidation은 이 두가지 지식을 잘 조합해서, 필요한 정보를 잘 선별하여 답변할 수 있도록 하는데에 초점을 두고 있다.
이번 포스팅에서는 본격적인 지식의 결합에 관해서 다루기 전에, 내재하는 정보를 어떻게 이용하는지에 관한 논문들을 다뤄보려고 한다.
- GENERATE RATHER THAN RETRIEVE: LARGE LANGUAGE MODELS ARE STRONG CONTEXT GENERATORS (GenRead)
- Recitation-Augmented Language Models
우선 GenRead 논문을 먼저 살펴보자.
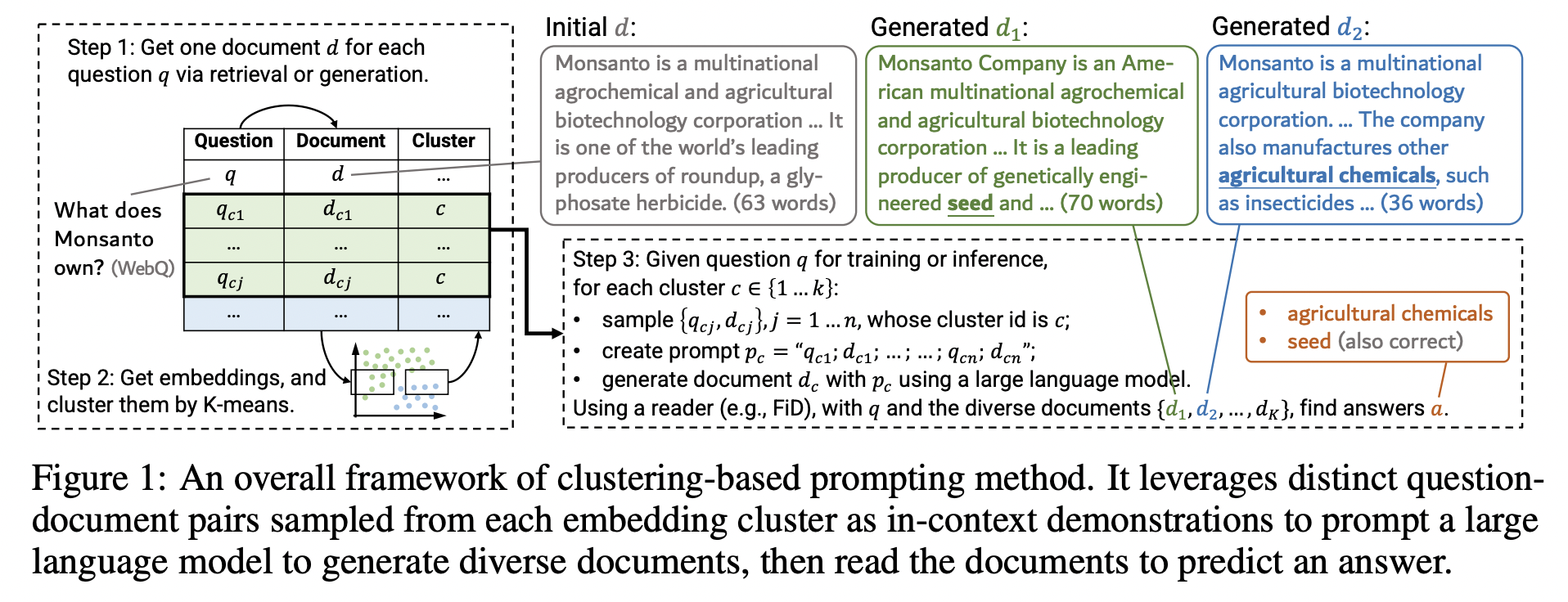
위의 그림은 GenRead의 전체적인 프레임워크를 나타낸다.
이 논문이 공개되었을 당시, 대부분의 시스템에서는 RAG를 채용하고 있었다. 하지만, 다양한 지식들을 제법 잘 담고 있는 파라미터가 제법 큰 모델의 경우에는 DPR(Dense Passage Retrieval)과 같은 방법을 이용해서 필요한 정보를 Retrieve 하는 것 보다 LLM이 필요한 Knowledge를 담고 있는 Context를 직접 생성하도록 하는 것이 오히려 더 좋은 성능을 낼 수 있다는 가정으로 시작된다.
프레임워크는 간단하게 구성되어 있는데, 어떠한 질문이 들어오면 해당 질문에 관한 Context를 생성한다. RAG에서 프롬프트에 검색된 Passage를 포함하는 것 처럼 생성된 Passage를 프롬프트에 포함하여 정답을 생성하도록 한다. 과정을 순차적으로 나타내면 다음과 같다.
- 우선 각 질문마다 1개의 Context 데이터를 생성한다.
- 질문과 생성된 Context를 GPT에 함께 입력하여 각 질문-Context 쌍마다 인코딩을 하여 대표 벡터를 생성한다.
- 만들어진 대표 벡터에 K-Means 클러스터링을 적용하여 군집화를 한다.
- 각 클러스터마다 N개의 데이터를 샘플링한다.
- 샘플링된 데이터를 Example 데이터로 활용하여 In-context Learning의 방법으로 주어진 질문에 관한 Context를 생성하여 정답 생성에 활용한다.
(이후 설명할 Clustering-Based Prompt 방법에 해당)
RAG에서 검색된 데이터를 여러 개를 이용하는 것과 같이, 해당 방법에서도 Context를 샘플링하여 여러 개의 데이터를 생성하여 활용하면 더 좋은 성능을 기대할 수 있다.
하지만 단순하게 여러 개의 데이터를 샘플링하여 더 생성하는 것은 비슷하거나 같은 데이터를 반복하여 생성하고, 다양한 데이터를 생성하는 것에는 도움이 되지 않을 수 있다.
이에 해당 논문에서는 Diverse Human Prompts와 Clutering-Based Prompts의 두 가지 방법을 이용하여 입력되는 프롬프트에 다양성을 주었다.
Diverse Human Prompts는 말 그대로, 사람이 다양한 프롬프트를 만들도록 하여 다양한 프롬프트를 입력으로 주고 Context를 생성하는 것이다.
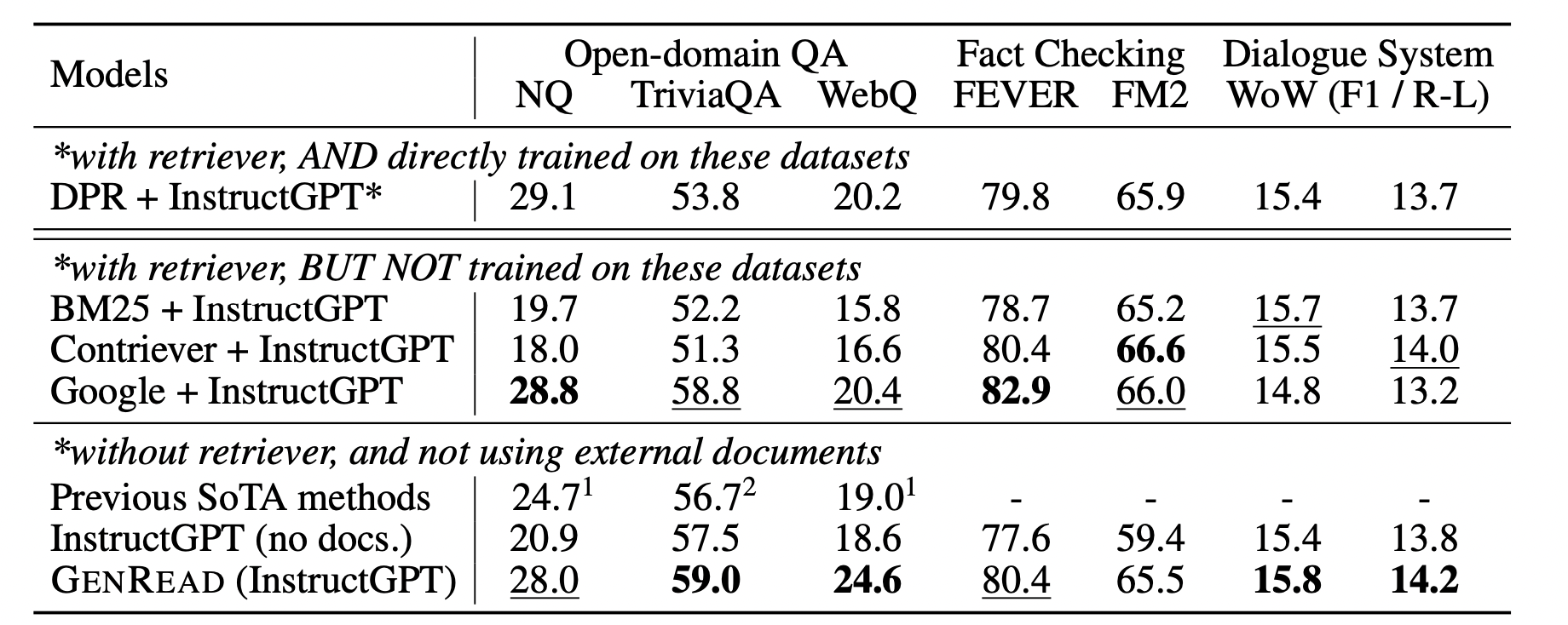
GenRead 방법은 이전 SoTA에 비해서 우수한 성능을 보였다. 하지만 이 논문 이후, DPR보다 우수한 Retrieval 방법이 많이 등장하였기 때문에 RAG 방법의 성능이 이전보다 훨씬 우수해졌을거라는 점, 그리고 해당 논문에서는 매우 큰 LLM을 이용했기 때문에 다양한 내재지식을 LLM에서 추출할 수 있었다는 한계점이 존재한다. 그럼에도 파라미터에 존재하는 지식을 활용하여 OpenQA를 수행한 교과서적인 논문이라고 볼 수 있다.
다음은 Recitation-Augmented Langauge Models 논문을 살펴보겠다.
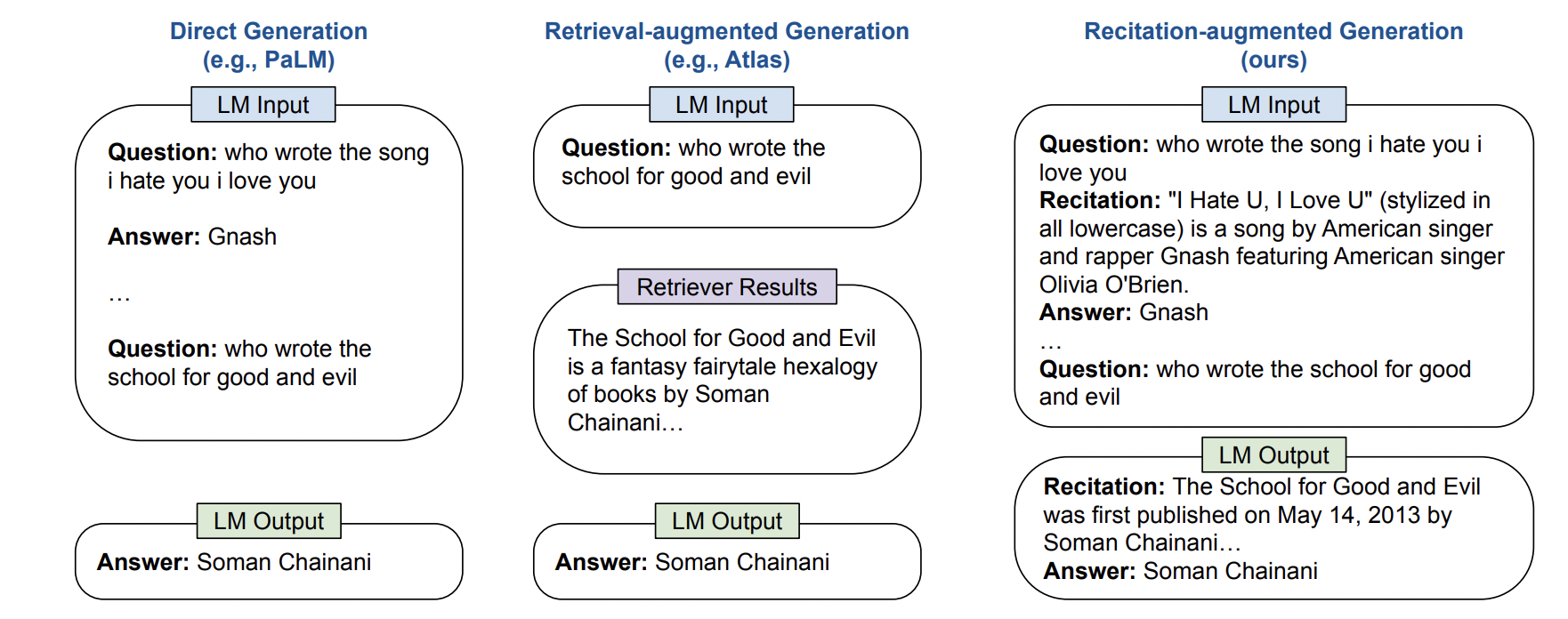
해당 논문은 사람이 무언가를 암기하고 떠올릴려고 할 때 연상을 하면서 떠올리는 것이 훨씬 도움이 되는 것에서 출발하였다.
“미국의 31대 대통령은?”이라는 질문에서 바로 대통령 이름을 떠올리는 것 보다는 31대 대통령에 관련된 정보를 하나씩 생성해나가다가 마지막에 연상된 기억들을 활용하여 최종 정답을 생성하는 것이 훨씬 정답을 잘 생성할 수 있다는 것이다. (Chain-of-Thoughts의 Open-domain QA 버전이 아닐까?)
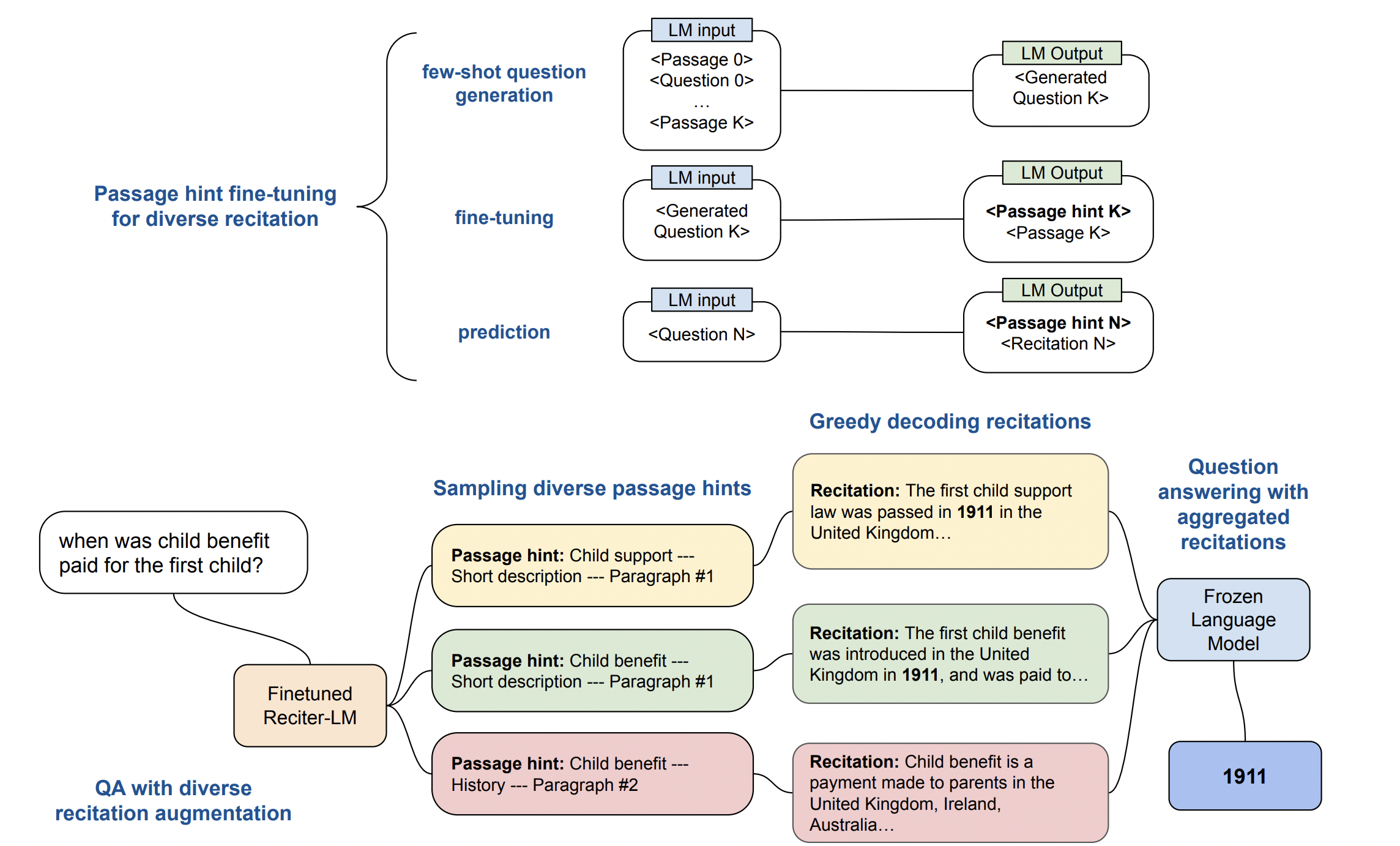
위의 그림은 Recitation-Augmented Langauage Models 방법의 전체적인 프레임워크를 나타낸다.
우선 Finetuned Reciter-LM 모델을 먼저 학습시켜야 하는데, 해당 모델의 역할은 어떠한 질문이 들어왔을 때, 해당 질문에 답을 하기 위한 힌트들을 생성하도록 하는 것이다. 샘플링을 통해서 여러 개의 Passage Hint를 생성하고, 생성된 Passage Hint를 기반으로 Recitation을 수행하여 Passage를 생성한다. 그리고 생성된 Passage들을 참조하여 최종 정답을 생성하도록 한다.
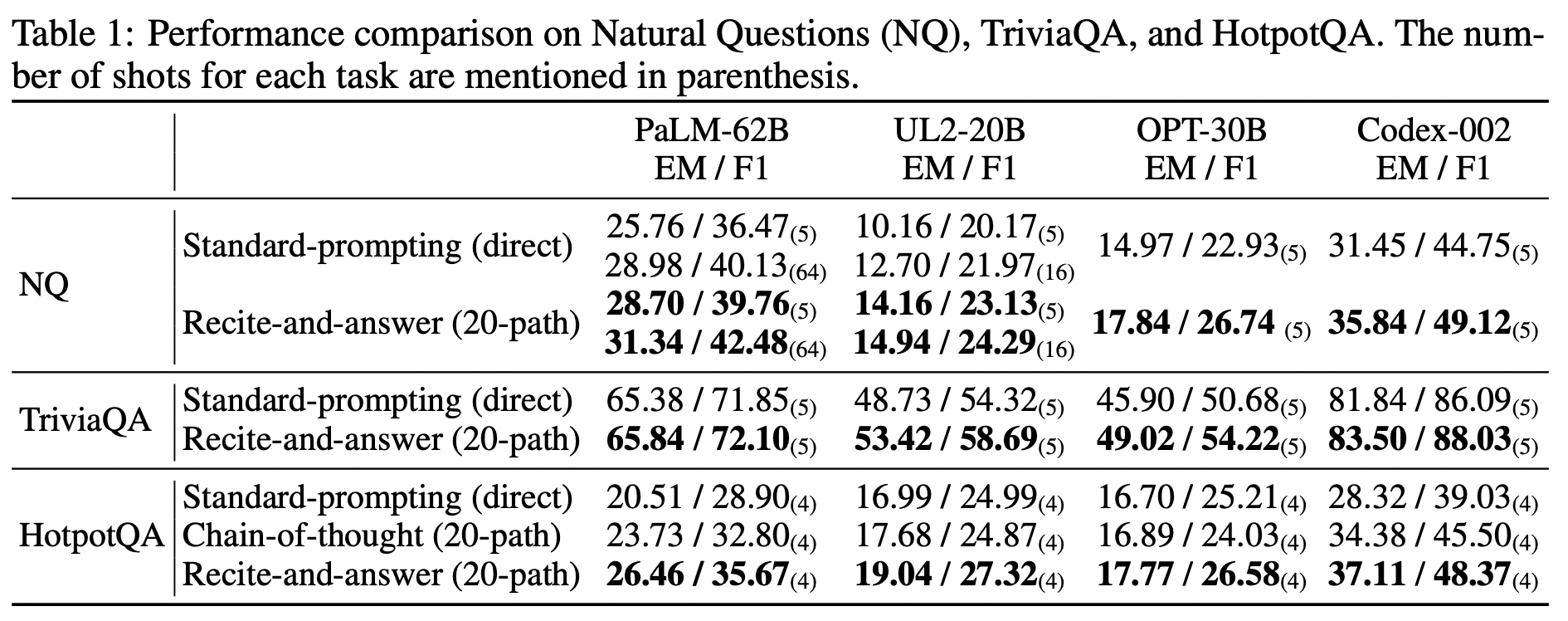
Recitation-Augmented 방법도 마찬가지로 다양한 데이터셋에서 우수한 성능을 보였다.
GenRead 방법은 좀 더 단순하고 직관적으로 Context를 생성하도록 유도했던 반면, Recitation-Augmented LM은 Recite 모델을 통해서 Passage의 Hint를 생성하도록 하고(이 과정이 일종의 Query Decomposition과 유사한 과정일 것 같다), 만들어진 Hint에 기반하여 Passage를 생성하도록 하였다.
두 방법 모두 다양한 Passage가 생성될 수 있도록 GenRead는 Diverse Human Prompt, Clustering-based Prompt를 적용하였고, Recitation-LM은 Recite LM에 샘플링을 적용하여 다양한 Paasage Hint를 생성하도록 하였다.
오늘은 Knowledge Consolidation 관련 논문들을 살펴보기 전에, 어떻게 LLM의 파라미터에 내재하는 지식들을 이용할 수 있는지 관련 논문들을 살펴보았다.
다음 글에서는 본격적으로 내재/외재 지식을 통합하여 처리하는 논문에 관해서 살펴보겠다.