이번에 살펴볼 논문은 “A Survey on Employing Large Language Models for Text-to-SQL Tasks”으로 LLM을 이용한 Text-to-SQL 태스크를 Survey한 논문을 살펴보려고 한다.
우선 Text-to-SQL 태스크는 자연어 질문이 있으면 해당 질문에 대한 답을 얻기 위한 SQL 쿼리를 생성하는 태스크이다. 자연어 쿼리와 테이블 데이터를 입력받고 정답을 출력하도록 하는 Semantic-Parsing 태스크와 유사하다고 볼 수 있지만, 해당 태스크는 정답을 모델이 직접적으로 바로 생성하고, Text-to-SQL은 SQL을 먼저 생성한 후 SQL Executer에서 최종적인 정답을 생성하는 과정의 차이가 있다. 또한, Text-to-SQL은 정답의 도출 과정에서 매우 복잡하고 큰 수들의 연산이 필요할 때, 그러한 LLM에게는 힘들지만 계산기에게는 간단한 과정을 SQL Executer에게 맡기기 때문에 그런 부분에서도 이점이 존재한다.
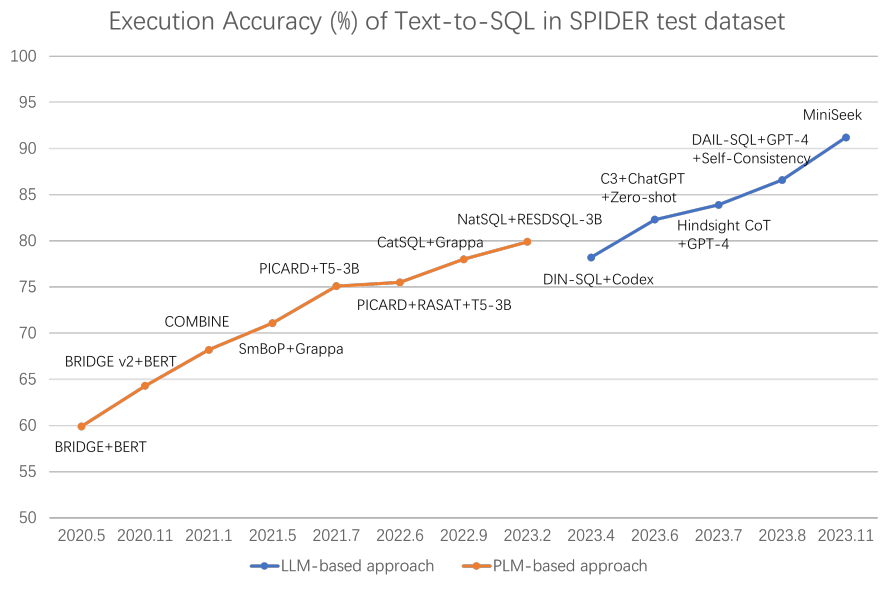
그림 1. Text-to-SQL 성능 변화
위의 그림은 기존의 사전학습 언어모델 기반의 접근 방법의 성능 변화와 LLM을 도입했을 때의 성능 변화를 나타낸다. 확실히 Text-to-SQL 태스크에서는 LLM이 도입되면서 성능이 드라마틱하게 빠르게 증가한 것을 확인할 수 있는데, 이는 LLM이 다양한 논리적인 추론 능력이 향상되었으며, 또한 코드 생성에도 능한 LLM들이 다수 존재하기 때문으로 보인다. (WikiTQ와 같은 Semantic Parsing 태스크에서는 LLM 기반 방법과 PLM 기반 방법의 SOTA 성능 차이가 그렇게 크지 않다)
해당 논문은 벤치마크 소개, Text-to-SQL 태스크 소개, 현재 기법, 미래의 방향으로 섹션을 나누어서 설명을 하고 있다.
우선 Text-to-SQL 태스크를 더 자세히 살펴보면, 해당 태스크는 자연어로 입력된 질문을 SQL Executer에서 실행할 수 있는 SQL 언어 형태로 번역하는 태스크라고 볼 수 있다. 기존의 딥러닝을 이용한 접근 방법들은 스키마 연결, 데이터베이스 스키마와 자연어 질의를 같이 인코딩하고 SQL을 생성하는 방법 등이 적용되었다.
해당 논문은 Text-to-SQL, 벤치마크, LLM 기반 기존 방법, 미래 방향으로 나누어서 진행하고 있다.
우선 Text-to-SQL 태스크를 자세히 살펴보면, 해당 태스크는 자연어로 이루어진 질의를 SQL Executer에서 실행할 수 있는 SQL 언어로 번역하는 태스크라고 볼 수 있다. 기존의 딥러닝 기반 방법론에서는 Schema Linking을 이용하거나 혹은 NLQ(Natural Language Question)과 데이터베이스 Schema를 함께 인코딩하여 SQL 쿼리를 생성하는 방법이 주로 적용되었다.
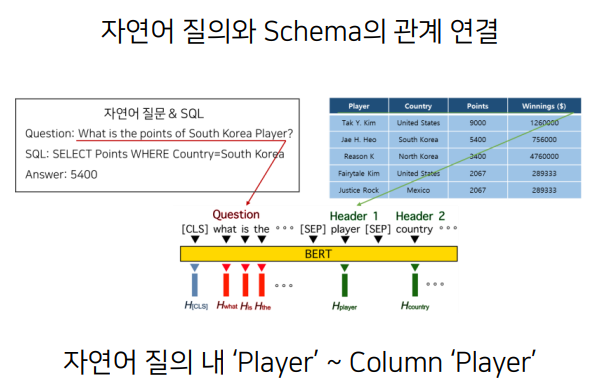
그림 1. Schema Linking 예시(출처: http://dsba.korea.ac.kr/seminar/?mod=document&uid=1482)
여기서 데이터베이스의 스키마란 데이터베이스의 전반적인 구조와 명세를 정의하고 있는 메타데이터의 집합이라고 할 수 있다. SQL 쿼리를 생성할 때 이러한 스키마를 참조하여 적절한 Column 이름이나 원소의 이름을 참조하여 SQL – 쿼리를 디코더를 통해서 생성한다고 볼 수 있다.
Text-to-SQL을 위한 벤치마크 데이터셋으로는 아래와 같은 논문들을 언급하고 있다.
- Structure-grounded pretraining for text-to-sql.
- Measuring and improving compositional generalization in text-to-sql via component alignment
- Towards robustness of text-to-SQL models against synonym substitution
- Exploring underexplored limitations of cross-domain text-to-SQL generalization
- A pilot study for Chinese SQL semantic parsing
- Towards robustness of text-to-SQL models against natural and realistic adversarial table perturbation
- Cosql: A conversational text-to-sql challenge towards cross-domain natural language interfaces to databases
- Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task
- Sparc: Cross-domain semantic parsing in context
- Seq2sql: Generating structured queries from natural language using reinforcement learning
하지만 이러한 벤치마크들은 ChatGPT가 등장하면서 LLM 모델들에게 큰 차이로 SOTA 성능을 내주었다고 한다. 예를 들어, Spider 벤치마크에서는 기존의 73이었던 SOTA 성능이 LLM의 등장으로 91.2까지 높아졌다.
이에 이 논문에서는 LLM을 이용한 방법에서도 다소 도전적일수 있는 벤치마크 몇 가지를 추가로 소개하였다.
추가로 소개된 첫번째 벤치마크는 BIRD인데, 위에서 언급된 기존의 벤치마크들은 대부분 데이터베이스 스키마를 이용해서 몇 개의 열만 참조하여 문제를 해결하도록 설계되어 있다. 그렇기에 해당 벤치마크들은 실제 사용되는 데이터베이스를 이용한 시나리오와는 거리가 좀 있을 수 있다. BIRD에서는 실제 현업에서 사용될만한 매우 큰 사이즈의 데이터베이스를 이용하였는데, 95개의 데이터베이스로 이루어져 있으며 총 33Gb의 크기를 가진다. 해당 벤치마크에서는 GPT-4가 54.89%의 성능을 기록했다.
두번째로 소개한 데이터셋은 Dr.Spider이다. 기존의 Text-to-SQL 모델들은 Task-Specific Perturbation에 취약하다. Dr.Spider 벤치마크는 이러한 갭을 해소하기 위해 만들어졌는데, 17가지 Perturbation을 데이터베이스, 자연어 쿼리, SQL 쿼리에 적용하여 더 Robuste한 평가를 적용하였다.
(두 데이터셋은 추후 따로 자세히 다루도록 하겠다.)
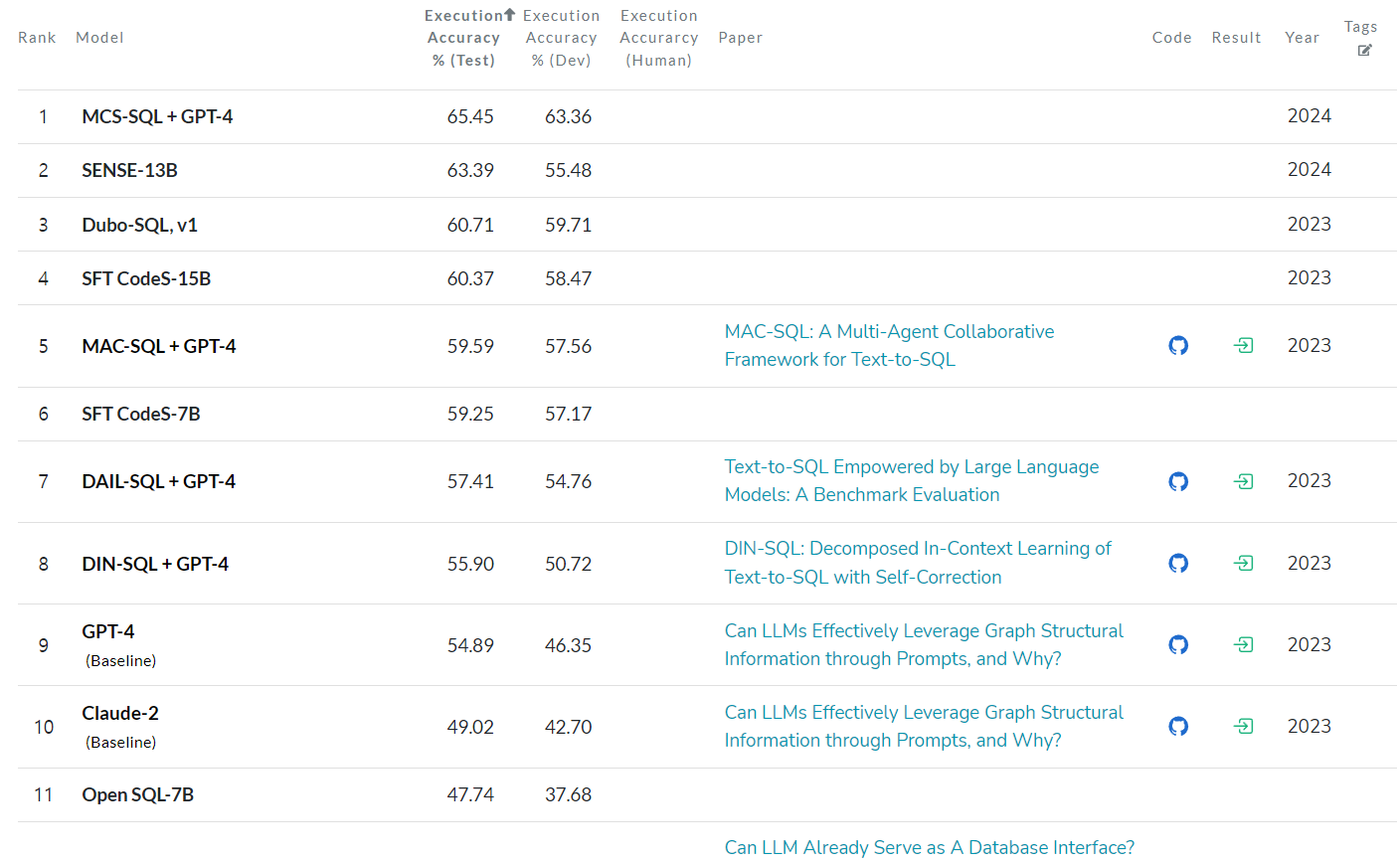
BIRD 벤치마크 모델 성능표(Papers with Code)
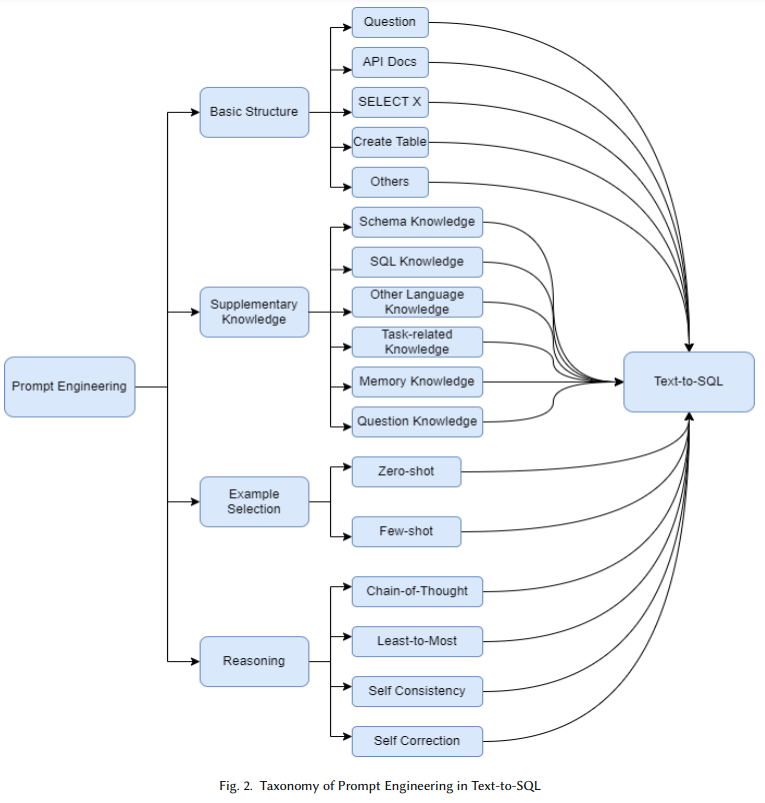
그림. Text-to-SQL 태스크에서의 프롬프트 엔지니어링 기법 분류 계층
(때로는 In-context Learning라고 불리는)Prompt Engineering은 다양한 태스크에서 활용되고 있는데 Text-to-SQL 태스크에서도 다양하게 활용되었다. 이전에 소개했던 LLM기반 Table Parsing 태스크에서도 CoDEX, ChatGPT와 같은 LLM을 이용하되 코드를 생성하거나 실행가능한 계산 식을 생성하도록 하는 방법으로 문제를 해결하였던 논문들이 많이 있었다. Text-to-SQL에서도 마찬가지로 모델을 파인튜닝하는 대신 Prompt-Tuning을 통해서 해결한 연구들이 많이 있었다. BIRD에서도 Prompt Tuning을 이용한 방법이 가장 높은 성능을 보이고 있는 것을 확인할 수 있다.
Prompt Engineering을 위한 입력에는 기존 Deep Learning을 이용한 방법과 마찬가지로 SQL 쿼리 생성에 필요한 정보들을 입력하게 된다. 가장 기본적으로는 당연하게도 변환하려는 자연어 쿼리와 데이터베이스를 참조하기 위한 데이터베이스 스키마가 될 수 있다. 아래에는 이러한 프롬프트에 포함될 수 있는 데이터들을 나타낸다.
Question: 몇몇 연구는 데이터베이스 스키마와 같은 부가적인 정보 입력 없이 자연어 쿼리만을 입력하여 변환하는 방법들을 보였다. 다만, 이러한 경우 실제 사용에서는 성능이 크게 떨어질 수 있는데, 예를 들어 “홍길동이 태어난 나라는 어디인가요?”라는 질문을 변환하고자 할 때, 테이블 스키마를 이용해서 데이터베이스의 헤더를 참고할 수 있다면 “Select 국가”, “Select 나라”와 같이 모호한 부분을 해결할 수 있다.
API Docs: 몇몇 연구들은 API 기술 문서를 추가로 프롬프트에 입력으로 제공하였다. 예를 들어 생성하고자 하는 SQL 언어가 SQLite인 경우, SQLite의 API 기술문서를 추가로 제공하여 해당 API에 맞는 SQL 언어들을 생성하도록 하였다.
Select X: “SELECT * From Table LIMIT X”를 실행하고 나온 결과문을 프롬프트에 추가하는 방법도 적용되었다. 저기서 X은 개수를 의미하는데 일반적으로 3을 적용한다고 한다.
CREATE TABLE: CREATE TABLE 구문을 프롬프트에 포함시키는 방법으로 각 Column의 이름, primary key, foreign key 등의 정보를 접근할 수 있게 되면서, 다중 테이블을 이용해야하는 SQL 구문 생성에서 더 좋은 성능을 보였다.
Others: 그 밖에도 랜덤하게 샘플링된 Column, Numerical Column의 값의 범위 등의 정보를 LLM의 프롬프트에 추가하였다.
이처럼 Text-to-SQL을 실행할 때, LLM이 참고할 수 있는 다양한 정보들을 프롬프트에 포함하여 태스크를 수행하도록 하였다. 하지만, 이후 연구에서는 이러한 정보들 외에도 전문적인 부가 지식들을 추가로 프롬프트에 제공하여 성능을 개선하고자 하였다.
Schema Knowledge: Text-to-SQL 태스크를 수행하려는 데이터 엔지니어나 연구자들은 너무 많은 데이터베이스에 접근해야하는 문제때문에 어려움을 겪게 된다. (너무 긴 스키마 정보, 효과적인 table과 column 정보를 구분하는 것 등에서도) 이에 Schema Linking으로 알려진 방법들을 적용하여 모델의 attention이 필요한 정보에만 집중되게끔 하였다. 예를 들어, 한 연구에서는 다양한 Schema 정보들의 Representation을 구하고, 변환하려는 자연어 질문 정보와 유사도를 비교해서 유사한 정보들을 선택하는 등의 방법을 이용했다.
SQL Knowledge: 다음으로 많이 사용된 전문 지식은 SQL 관련 지식이다. 많은 연구에서 LLM이 SQL과 관련된 Syntax나 규칙들을 이해하도록 하기 위해서 SQL과 관련된 규칙들과 제한사항들을 프롬프트에 추가로 제공하였다. 예를 들어 SQL Set들을 프롬프트에 추가로 제공하거나, SQLite Lattice 등의 정보를 프롬프트에 추가로 제공하였다.
Other Language Knowledge: 데이터베이스나 SQL과 관련된 지식 외에도 다른 접근방법도 있었는데, BINDER-SQL라는 다양한 프로그래밍 언어에서 확장이 가능한 언어를 설계하고 LLM이 BINDER-SQL 언어로 먼저 답변을 생성하도록 하였다. 그리고 생성된 BINDER-SQL 구문에서 Column이나 Value를 API 표현식을 통해 대체하는 방법으로 최종 결과를 생성한다.
Task-related Knowledge: 여기서는 도메인에 특화된 SQL 구문들이 사용되었다. 예를 들어, 고객이 어떤 물건을 구매하고자 할 때 “Price per unit of product”와 같이 특정한 컨셉의 계산 메소드를 프롬프트에 추가하는 방법이 적용되었다.
Memory Knowledge: ChatDB에서는 LLM이 복잡한 multi-step 추론을 하는데에 도움을 주기 위해서 symbolic memory를 적용했다. 복잡한 데이터 베이스를 분해하고, 메모리에 SQL의 실행 결과를 매 스텝마다 저장하도록 하였다.
Question Knowledge: 이 방법은 보통 few-shot 기법에서 사용이 되었는데, 비슷한 유형의 질문들의 실행 결과나 데이터를 프롬프트에 제공한다. 예를 들어 한 연구에서는 질문의 뼈대(skeleton)을 기반으로 유사한 문제를 검색하여 적절한 예시를 찾아서 프롬프트에 제공하는 방법을 적용했다.
이처럼 Text-to-SQL에서는 General Domain에 사전학습된 언어모델을 이용해서 전문적인 지식이나 예제들을 프롬프트에 제공하는 방법을 통해서 문제를 해결하고자 하였다. 그럼에도 예제를 제공하지 않고 zero-shot 방법을 이용한 연구들도 많이 있었는데, 이는 보통 특정한 목적을 가지고 zero-shot으로 구성하기 보다는 모델의 입력으로 들어가는 token의 길이를 줄여서 비용을 낮추고자 한 연구들이 대부분이었다. 프롬프트에 few-shot 예제를 넣을 때는 일반적으로 데이터베이스 스키마, 텍스트 쿼리, SQL 구문을 넣는다. 토큰의 길이를 줄여서 비용을 절감하고자 할 때는, 보통 저기서 데이터베이스 스키마를 제외한다.
추론 방법은 Semantic Parsing 방법과 마찬가지로 CoT(Chain Of Thoughts) 방법이 주로 활용된다. CoT는 LLM에게 한단계씩 차근차근 정답을 생성하도록 하는 방법으로, 최종 정답을 얻기까지 여러번의 생성 및 추론 과정을 거치게 된다.
그 외의 추론 방법으로 Least-to-Most 방법이 있는데, CoT와 유사하게 복잡한 문제를 더 간단한 Sub 문제들로 부수고 쪼개어 해결하는 방법이다. 한 연구에서는 존재하는 예제들을 확장시켜서 Least-to-Most 패턴으로 만들어 문제를 해결하였다. (Adapt and Decompose: Efficient Generalization of Text-to-SQL via Domain)
ㅇ
위의 그림이 Least-to-Most 방법을 적용한 예시를 나타낸다. Decompose 과정을 살펴보면 태스크를 Decompose 하여 더 작은 문제로 분할하고, Intermediate Representation을 생성하도록 해서 중간 결과를 만들고, 최종적으로 정답을 생성하도록 하고 있다.
이외에도 복잡한 추론 문제에 대해서 모델이 다양한 추론 경로를 탐색하고 그 중 가장 일관된 답을 찾도록 하는 Self-Consistency, 모델이 답을 생성하고 난 후 스스로 교정하도록 하는 메소드를 실행시켜서 모델이 정답을 스스로 교정하도록 하는 Self-Correction 등의 추론 분야에서 자주 적용되는 다양한 프롬프트 기법이 적용되었다.
이러한 프롬프팅 기법들은 모델을 학습하는데 드는 자원이 필요없이 때문에 비용이 저렴하다고 볼 수 있다. 하지만, 파인튜닝을 적용한 모델들은(프롬프팅 기법들을 적용한 연구에 비해서 숫자는 적지만) 프롬프팅 기법을 적용한 모델들과는 확실한 성능 차이를 보였다.
한 연구에서는 PaLM-2를 파인튜닝하였고, Spider 데이터셋에서 전례없는 높은 성능을 보였다.
파인튜닝을 위한 데이터셋은 모델의 성능과 효율에 매우 중요한 영향을 미치는데, 일반적으로 파인튜닝 데이셋은 기존에 존재하는 데이터셋들을 통합하는 방식이 주로 적용되었다. 데이터들을 통합할 때느 일반적으로 large-scale, general-purpose의 데이터셋을 구축하는 것이 목표이다. 이를 위해서 공개된 데이터셋들을 단순하게 가져와서 사용할 수도 있지만, 일부 연구에서는 존재하는 데이터셋을 파인튜닝에 최적화하기 위해 개선시켜서 사용하였다. Spider-SYN과 Spider-Realistic은 데이터베이스 스키마가 explicitly하게 질문에서 나타나는 상황들을 제거하였다. Spider-DK와 ADVETA는 추가적인 지식을 요구하거나, 혹은 Adversarial 변형을 거쳐서 데이터베이스의 칼럼 이름들 변형시켰다. Spider-CG는 모델의 종합적인 일반화 능력 향상을 위해서, SParC와 CoSQL 데이터를 포함하는 multi-turn dialogue text2sql 태스크들을 포함시켰다. CSpider와 DuSQL은 모델의 multilingual 능력 향상을 증가시켰고, Dr.Spider는 multi-faceted adversarial 변형을 거쳐서 칼럼 이름들과 SQL을 변형시켰다. Bird는 실제 text2SQL 시나리오를 시뮬레이션한 다중 테이블에 대한 노이즈가 포함된 데이터셋을 공개했다.
여기서 주목해야 할 점은 text2SQL 태스크는 다른 태스크들과는 다르게 다른 태스크를 먼저 학습하고 그 능력이나 지식을 전이하는 task transfer가 잘 안되며, 그렇기 때문에 여러 태스크를 학습시키는 것이 모델의 일반화 능력 향상에 도움이 되지 않았기 때문에, 단일 태스크를 학습시키는 것이 더 좋은 성능을 낼 수 있었다. 또한, CoT를 이용한 추론 방법이 매우 좋은 성능을 내기 때문에 CoT 추론 과정이 포함된 데이터셋을 일부 포함시키는 것이 파인튜닝에서 더 좋은 효과를 낼 수 있었다. (다만 모든 데이터셋을 CoT 추론 과정을 포함하는 데이터셋으로 구성하는 것은 오히려 악효과를 냈었다고 한다)
사전학습 LLM은 매우 많은 모델들이 공개되어 있으며, 이는 파라미터의 크기, 사전학습 말뭉치 그리고 사전학습 과정 등에 따라서 달라진다. Spider 데이터셋에서는 PaLM-2가 가장 좋은 성능을 기록했으며, code-llama 모델도 text2sql 태스크의 파인튜닝에 이용이 되었었다. Text2SQL에서는 당연하게도 코드 데이터가 사전학습 과정에서 많이 포함되었던 모델들이 대체로 파인튜닝을 했을 때 좋은 성능을 보였다.
모델의 학습에는 Fully Fine-tuning, PEFT(LoRA and QLoRA) 등 다양한 방법들이 사용되었는데, PEFT 방법은 사후망각(catastrophic forgetting)을 줄여주는 효과가 있다는 결과가 있었던 것과 같이 명확하게 좋은 방법은 없으며 각 방법들의 장단점이 존재하였다.
이번 글에서는 LLM을 이용한 Text2SQL 태스크 연구들을 Survey한 논문을 살펴보았다. Text2SQL에서는 LLM이 모델을 실행하기 위한 부가적인 정보들을 프롬프트에 제공한 연구들이 많았는데, 테이블스키마부터 시작해서 SQL 언어의 메뉴얼 등 다양한 지식 정보들이 사용되었다. 또한, 추론 과정이 요구되는 태스크의 특성상 CoT, Least-to-Most, Self-Consistency, Self-Correction 등 추론을 위한 다양한 프롬프팅 기법들이 적용되고 있었다.
파인튜닝을 이용하는 것은 프롬프팅만 이용하는 것에 비해서 많은 성능 향상을 불러오지만, 파인튜닝을 위한 데이터의 개선(explicit한 데이터 제거 => 예를 들면, “나는 ‘Country’가 ‘대한민국’인 데이터의 개수를 구하고 싶다”), 코드 데이터에 능숙한 큰 파라미터의 사전학습 언어모델 사용 등 필요한 부분도 존재했다.