최근에는 LLM을 이용하여 합성된 데이터를 이용하여 모델을 학습하려는 다양한 연구들이 더더욱 많아지고 있다. MEGPIE는 LLM을 이용하여 사람의 개입없이 Alignment 데이터를 합성하는 방법을 소개하고 있다.
MEGPIE부터 살펴보면, Llama-3와 같은 모델은 현재도 3.2 버전이 발표될 정도로 다양한 크기의 다양한 모델들이 공개되어 많은 연구자들이 활용하고 있는 모델이다. 해당 모델은 AI의 Democratization을 지향하면서 공개된 모델인데 정작 사전학습이나 Alignment를 위한 데이터셋은 공개되지 않았기 때문에 새롭게 자신들의 모델을 구축하려는 연구자들은 Llama와 같은 모델을 재현하는 것이 불가능하다는 부분을 지적하면서 논문을 시작하고 있다.
해당 논문에서는 이러한 Alignment 데이터가 부족한 부분을 극복하기 위해서 공개된 LLM 데이터를 이용해서 Alignment 데이터를 생성하는 방법을 제안한다.
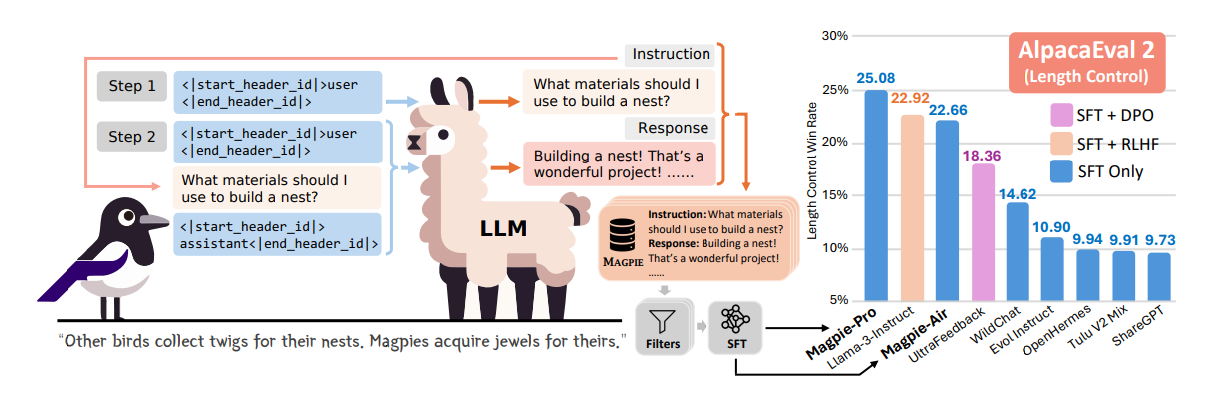
그림 1. MEGPIE의 데이터 생성 방식 및 AlpacaEval2에서의 학습된 모델의 성능 비교
위의 그림은 MEGPIE에서 데이터셋을 만드는 방법을 나타낸다. 우선 MEGPIE는 Pro 버전과 Air 버전을 각각 생성한 것을 확인할 수 있는데 Pro는 LLama-3-70B-Instruct를 통해서 데이터를 합성한 것이고, Air는 Llama-3-8B를 통해서 데이터를 합성한 것을 의미한다. MAGPIE Air와 Pro는 각각 206, 614의 GPU hour이 소요되었다. 그림 1의 오른쪽 부분은 각각 다른 Alignment 데이터셋을 이용하여 LLama-3-8B-base 모델을 학습했을 때의 성능을 나타낸다.
LLM을 이용해서 Instruction 데이터를 생성할 때, 가장 문제가 될 수 있는 부분은 모델이 생성하는 Instruction의 개수가 늘어날 수록 다양성이 떨어지고 반복되는 데이터를 생성할 확률이 커진다는 것이다. 해당 논문에서는 Instruction 튜닝이 된 LLama 모델에 Pre Query Template을 입력하고 Instruction 데이터를 생성하도록 하였다. Llama 모델은 왼쪽에서 오른쪽 방향으로 학습하는 Auto-regressive로 학습되었기 때문에 Pre Template을 입력했을 때, 다양한 Instruction을 생성할 수 있었다고 한다. (아마 LLama가 Instruction Tuning 될 때, Instruction 부분에도 Ignore하지 않고 Loss 학습이 적용된 듯 하다)
예를 들어 “[INST] Hi ! [/INST]가 있을 때, [INST]는 Pre Query Template이 되고, [/INST]는 Post Query Template가 된다. Instruction 튜닝된 LLama 모델에 이러한 Pre Template만 입력했을 때, 다양한 템플릿을 생성하는 특성을 이용해서 Alignment 데이터를 위한 다양한 Instruction 데이터를 합성하도록 하였다. Instruction에 대한 답변은 마찬가지로 생성된 Instruction을 Post Template까지 모델에 입력하고 나머지 답변을 생성하도록 하였다.
이전 연구들은 Instruction을 다양하고 잘 생성하도록 하기 위해서 적절한 프롬프트 엔지니어링을 적용하는 것이 필수적이었는데, 해당 논문의 방법은 그냥 Pre Template만 입력하면 모델이 알아서 Instruction을 생성하도록 하는 방법이기 때문에 훨씬 간단하면서도 모델이 다양한 Instruction을 생성하도록 할 수 있었다.
이 방법을 응용하면 Multi-Turn을 위한 Alignment 데이터셋도 구축할 수 있다. 우선, 첫 번째는 Instruction과 답변쌍을 가장 먼저 생성한다. 그리고 이렇게 만들어진 데이터의 끝에 다시 Pre Template을 넣어서 Instruction을 생성하는데, 이때 모델이 자체의 역할을 잊고 제대로 생성을 하지 못하는 경우가 잦았다고 한다. (특히 8B 모델에서) 이러한 문제를 해결하기 위해서 모델이 Multi Round의 대화를 하고 있다고 지정해주는 System Prompt를 작성하여 추가해주었다. 이를 위한 시스템 프롬프트는 아래와 같다.

그림 2. MT 데이터셋 생성을 위한 시스템 프롬프트
수학, 법률 시험, 수능 시험 등과 같이 특정한 도메인에 특화된 Instruction-Tuning을 원할 때도 있을 수 있다. 특정 카테고리에 관한 Instruction 및 답변을 생성하는 Controlling Instruction 생성 방법도 추가로 적용하였는데, 시스템 프롬프트에서 이와 같은 내용을 추가하는 방법을 적용하였다. 아래는 이를 위한 시스템 프롬프트 예시를 나타낸다.

그림 3. Controlling Instruction 데이터 생성을 위한 시스템 프롬프트 예시
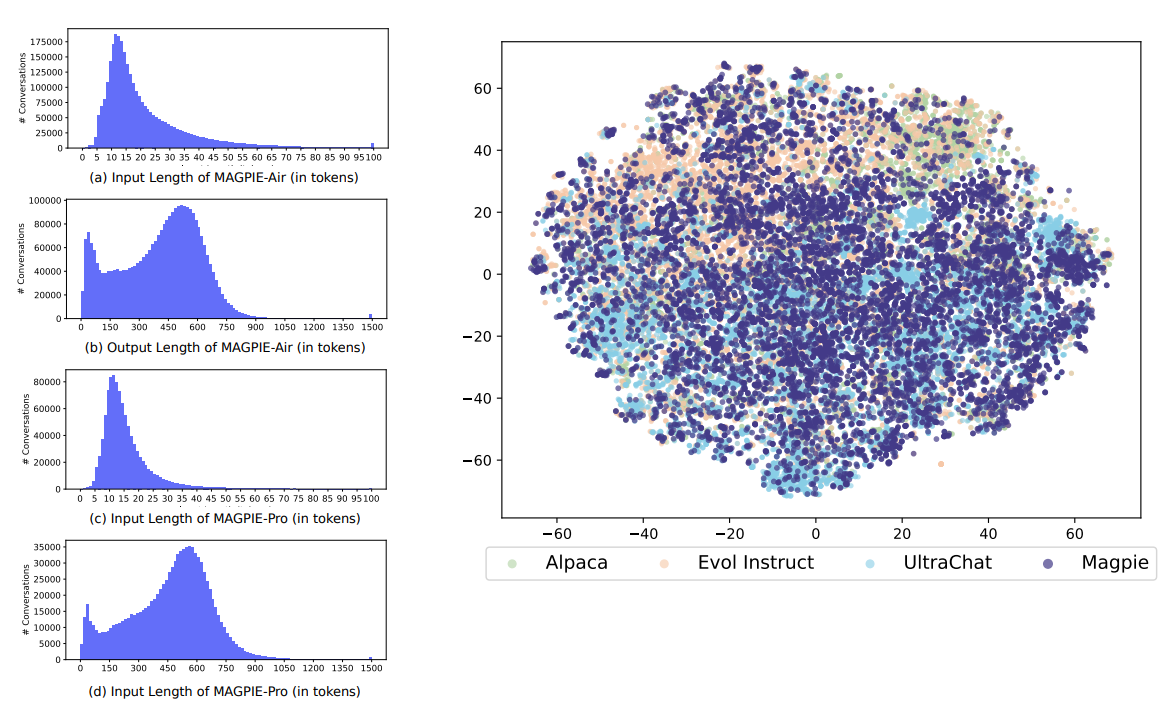
그림 4. 만들어진 MEGPIE 데이터의 특성 분석
그림 4는 MEGPIE 데이터셋의 다양한 특성을 분석한 그림이다. 우선 그림의 왼쪽은 만들어진 데이터셋의 입력 및 출력의 길이 분포를 나타낸다. 오른쪽은 만들어진 데이터셋을 all-mpnet-base-v2 모델을 이용해서 임베딩하고, 임베딩된 표현 벡터를 SNE를 통해서 시각화한 것을 나타낸다. MEGPIE의 데이터셋의 분포가 훨씬 다양하게 분포되어 있는 것을 확인할 수 있다.
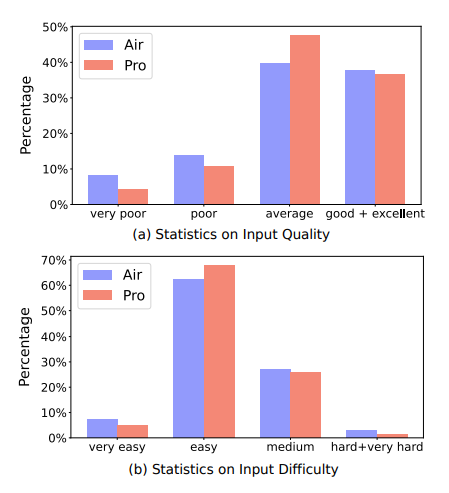
그림 5. MEGPIE 데이터셋의 품질 및 난이도 분석
위의 그림은 MEGPIE 데이터셋의 난이도 및 품질을 분석한 그림이다. 만들어진 데이터셋의 품질이나 난이도를 매기는데에는 Llama-3-8B-Instruct 모델을 이용하였다. 품질에서는 Air와 Pro의 차이가 많이 났지만, 만들어진 데이터셋의 난이도에는 더 크고 성능이 좋은 모델을 사용하는 것과는 큰 연관이 없는 것으로 보인다.
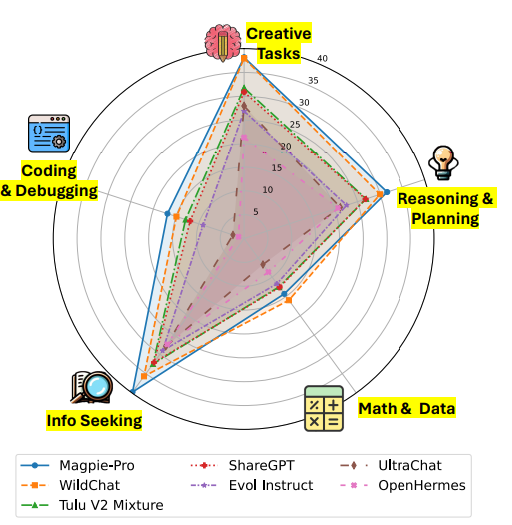
그림 6. 카테고리별 Pro 모델의 성능
다음은 MEGPIE Pro 데이터를 이용하여 학습된 모델의 성능을 나타낸다. 아무래도 대중적인 태스크들은 MEGPIE를 이용해서 잘 합성할 수 있고, 데이터 합성 과정에서 많은 부분들이 해당 카테고리의 데이터일 것이기 때문에 비교적 성능이 높은 것을 확인할 수 있다. 하지만, 데이터의 생성 과정에서 어느정도 사람의 개입이 필요하거나, 혹은 대중적이지 않은 도메인의 태스크에서는 아직 성능이 낮은 것을 확인할 수 있다.
오늘은 Alignment 데이터셋을 사람의 개입없이 합성하는 MEGPIE를 살펴보았다. 합성된 데이터로 튜닝했을 때, Pro 모델은 LLama-3-8B-Instruct 데이터보다 향상된 성능을 보이기도 했는데 앞으로도 데이터 합성을 이용한 모델 학습이 더욱 대중화가 될 것 같다. MEGPIE는 뛰어난 성능을 보여주긴 했지만, 만들어지는 Instruction의 난이도를 조정하는 부분, 그리고 일반적이고 대중적인 프롬프트 외의 카테고리의 데이터들을 생성하는 것에서는 아직 더 개선되어야 할 것 같다.