현재 RAG는 매우 많은 분야에서 다양한 응용으로 적용되고 있다. 하지만, RAG는 단순하게 관련성을 기반으로 몇 개의 데이터들을 가져와서 한번의 LM 호출(Single LM invocaton)으로 결과를 생성한다. 이러한 모델은 일부 답변가능한 질문들 밖에 처리할 수 없으며, Computational 태스크인 Counting, Math, Filtering과 같은 연산에서는 에러에 취약할 수 밖에 없다.
이러한 점을 고려하여, 해당 논문에서는 table-augmented generation(TAG) 방법을 제안하였다.
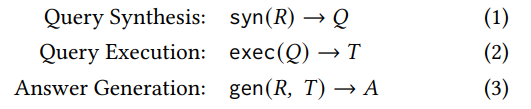
TAG는 Query Synthesis, Query Execution, Answer Generation의 3가지 단계로 이루어진다. 우선 Query Synthesis에서는 LLM에서 정답 생성에 필요한 정보들을 DB로 부터 얻기 위해서 SQL 쿼리를 생성한다. 그 후, Query Execution에서는 Synthesis 과정에서 만든 SQL 쿼리를 실행시켜 DB에서 정보를 추출한다. 마지막으로 Answer Generation 단계에서 원래 입력된 자연어 쿼리(R)과 DB에서 추출한 정보(T)를 입력하여 최종 정답을 생성한다.
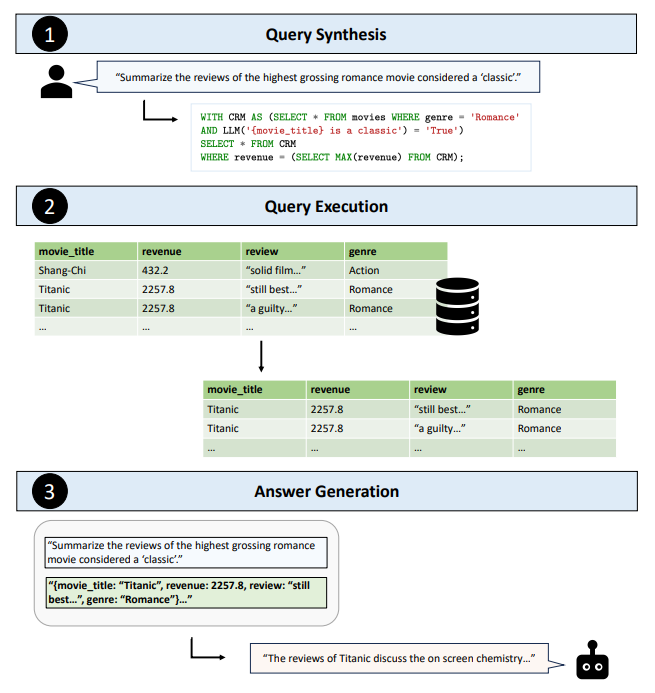
그림 1. TAG(Table-Augmented Generation) 모델의 구조
Query Synthetis 과정을 좀 더 살펴보면, 해당 과정은 일종의 Text-to-SQL 과정과 비슷하다고 볼 수 있다. 자연어 질문을 먼저 입력받고, SQL Engine에서 실행 가능한 SQL 쿼리를 생성하는 과정이기 때문이다. 하지만, Text-to-SQL과 한가지 다른 점은 해당 태스크는 자연어 질문을 입력받고 해당 자연어 질문의 정답을 직접적으로 바로 생성하기 위한 SQL 쿼리를 생성하는 것을 목적으로 한다면, TAG에서의 과정은 LLM에서 참고하여 최종 정답을 생성할만한 단서가 되는 정보들을 추출하는 것을 목표로 한다. 해당 과정을 순서별로 나타내면 다음과 같다.
- Table Schema를 이용하여 어떤 데이터들이 질문의 요청과 연관이 있는지를 추론한다.
- Semantic Parsing을 수행하여 유저의 요청을 DB에서 실행될 수 있는 형태의 쿼리로 변환한다
Answer Generation 과정은 LLM에서 정답을 생성하는 것과 똑같다고 볼 수 있다. 이 과정에서는 이전 단계에서 추출한 정보들과 유저의 질문을 조합하여 프롬프트를 구성하고 해당 프롬프트를 입력하여 최종 결과를 생성하게 된다.
이제, TAG의 Design Space를 살펴보겠다.
TAG에서는 다양한 범위의 자연어 질의를 다룰 수 있는데, 여기서는 두 가지를 기반으로 질의를 Categorization 하였다.
- level of data aggregation
- the knowledge and capabilities
Query Types 우선, TAG는 위의 두 가지 특징들을 모두 질의에 포함하고 있는데, 하나씩 살펴보면
TAG는 여러 행을 가져와서 요약을 하거나 랭킹을 적용하는 논리적인 추론을 필요로 하는 질의뿐만 아니라 답변하는데에 필요한 행들을 찾는 Retrieval-based 질문들도 포함하고 있다. 그리고 두번째로 분류나 Sentiment Analysis와 같이 넓고 다양한 태스크에 적용되는 질문들을 포함하고 있다.
Data Model 해당 논문의 구현에서는 지식을 기반으로 하는 다양한 Downstream 태스크로의 적용을 위해서 관계형 데이터베이스(Relational Database)를 사용하고 있다.
Database Execution Engine and API 해당 시스템은 다양한 데이터베이스의 실행이 가능한데, SQL 기반의 데이터베이스 엔진이나 벡터 임베딩 기반의 Retrieval 시스템 등 다양한 시스템의 선택이 가능하다. 가장 보편적인 해당 두 데이터베이스 시스템 말고도 다양한 데이터베이스 시스템의 고려가 가능한데, 해당 논문에서는 MADLib, Google’s BigQuery, Microsoft’s Predictive SQL 등의 ML-based function 들을 예시로 들었다.
LM Generation Patterns 일반적으로 RAG에서는 사용자 질문에 관련 있는 데이터를 채워넣은 Context를 입력하고 한번의 LM-call 생성으로 정답을 생성한다. TAG에서는 다른 방식도 적용될 수 있는데, 최근 연구인 LOTUS에서는 추론 기반의 Trnasformation을 포함하는 iterative 하거나 혹은 recursive한 Generation Pattern을 구성하였다.
실험에 사용된 데이터셋은 BIRD 데이터셋을 기반으로 하고 있는데, 실험을 위한 데이터셋으로 BIRD 데이터셋에서 California_schools, debit_card_specializing, formula_1, codebase_community, european_football의 DB 소스들과 쿼리를 선택하였다. BIRD에서 선택된 데이터셋의 질문들은 Match-based, 비교, 랭킹, Aggregation 등의 다양한 Query Type들을 포함하고 있는데, 이러한 유형들의 쿼리들이 정답을 찾을 떄 World Knowledge나 Semantic Reasoning을 요구하도록 변형하여 사용하였다. 예를 들어, California_schools 데이터베이스에서 질문을 변형 할 때 Bay Area에 있는 학교들을 찾는 등의 구문을 추가하는 것이다.
벤치마크에서 평가를 위한 모델들은 다음으로 구성되었다.
- Text2SQL
- 이 방법에서는 LM 모델이 정답을 얻기 위한 SQL 코드를 생성한다. LM의 프롬프트에는 모든 테이블의 스키마를 포함하도록 하였으며, BIRD의 연구에서 사용되었던 프롬프트를 그대로 사용하였다.
- Retrieval Augmented Generation
- RAG 방식의 방법으로 표 데이터를 임베딩하여 RAG 방식의 방법을 적용하였다. 이 때, 표를 임베딩 할 때는 Row-level Emgedding을 적용하였다. 10개의 가장 관련성이 높게 예측된 Row를 프롬프트에 포함시켜 정답을 생성하도록 하였다.
- Retrieval + LM Rank
- RAG를 확장한 방법으로, LM을 이용해서 Retrieved된 Row를 다시 Rerank하여 선별하였다. (STaRK에서 적용되었던 방법)
- Text2SQL + LM
- 이 방법에서는 모델이 먼저 SQL을 실행해서 관련성이 높은 Row들을 찾도록 한다. 그리고 추출된 Row들을 LM의 프롬프트의 Context에 입력하여 최종 정답을 출력한다.
- Hand-written TAG
- 이 방법에는 SQL을 생성할 떄, LM을 이용한 Text2SQL 방법 대신 전문가들이 직접 필요한 SQL 코드를 작성하고 해당 쿼리를 통해 추출된 Row들을 프롬프트의 컨텍스트에 추가하여 정답을 생성하도록 하는 방법이다.


위의 그림들은 벤치마크에서의 Baseline 모델들의 실험결과, 그리고 RAG, Text2SQL + LM, Hand-written TAG에서의 추출된 데이터 결과를 나타낸다.
아직은 전문가가 생성한 SQL을 기반으로 한 결과와 LLM 모델이 생성한 SQL을 기반으로 한 결과의 차이가 많이 큰 것을 확인할 수 있다. 이는 앞으로 TAG에서 적절한 Row들을 추출하는 SQL 생성 모델이 성능의 많은 부분을 차지할 수 있을 것으로 생각된다.
이번 논문에서는 DB를 기반으로 데이터를 추출하고 해당 내용을 기반으로 정답을 생성하는 TAG를 살펴보았다. 많은 중요한 데이터들이 DB에 존재하며, 이러한 DB 정보를 잘 활용하여 질의응답을 처리하는 것은 많은 분야에서 요구되고 있다. 앞으로도 이러한 연구들의 중요성 및 관심은 갈수록 높아질 것으로 생각된다.