오늘은 Bird Benchmark에 올라온 Text-to-SQL 논문들을 살펴보는 마지막 글이다.
오늘 살펴볼 두 논문은 다음과 같다.

- The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models
- CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Distillery
우선 첫 번째 논문부터 살펴보겠다.
첫 번째 논문의 제목은 “The Death of Schema Linking”으로 상당히 의미심장한 부분으로 제목이 시작되고 있다. 이전 글에서 E-SQL 논문을 다뤘었는데, 해당 논문에서도 “필요한 테이블 스키마를 선택하거나 필터링 하는 작업은 굳이 필요없다. 물론 LLama와 같이 Open-Source 언어모델에서는 유용할 지 모르겠지만, GPT-4와 같은 Frontier 모델에서는 충분히 긴 입력을 받을 수 있도록 설계되어 있고 입력된 전체 프롬프트에서 필요한 Feature를 알아서 잘 선별해서 SQL을 생성할 수 있는 능력이 있기 때문이다.”라는 내용을 이야기하면서 “Schema Selection” 모듈을 전체 파이프라인에서 제외하고, Question-Enrichment Module을 새롭게 추가했었다.
이번에 다룰 논문은 해당 내용을 더 자세하게 다루는 논문이다. 해당 논문은 Table Schema Selection이 왜 필요없는지, 그리고 왜 성능에 오히려 악영향을 주었는지를 자세히 분석하고 있고 Bird Benchmark에서 좋은 성능을 보여준 Distillery 모델의 구현에 관한 자세한 설명은 대부분 생략되어 있어 작성된 내용들을 기준으로 최대한 설명할 예정이다.

그림 1. 전형적인 Text-to-SQL 모델의 파이프라인
위의 그림은 전형적인 Text-to-SQL 모델의 전체적인 구조를 나타낸다. 필요한 테이블 스키마, Entity, Value등을 추출하는 Retrieval 과정, 추출된 데이터를 기반으로 SQL을 생성하는 Generation 과정, 생성된 SQL을 교정하는 Correction 과정으로 이루어져 있다.
해당 모델에서는 Retrieval 과정에서 테이블 스키마를 추출하는 과정을 생략하고, 전체 테이블 스키마를 프롬프트의 입력으로 사용한다.
해당 논문의 모델에서는 다음 세 가지 과정을 통해서 성능을 개선하였다.
- Augmentation
Column Description이나 Query Hint를 확장하는 작업 - Correction
SQL Query 후보들을 생성하고, Re-generation 기반의 교정 작업을 거쳐서 에러를 수정 - Selection
Self-Consistency를 이용해서 여러 개의 응답을 생성하고, 가장 Consistent한 응답을 선택
다음으로 테이블 스키마 링킹 과정이 어떤 영향을 미쳐서 어떻게 성능에 영향을 주는지를 자세히 분석하기 위해서 테이블 스키마 링킹의 성능을 두 가지 지표로 평가하였다.
- False Postive Rate(FPR)
주어진 쿼리에 대해, 검색된 열에서 관련 없는 열의 비율을 나타냄
EX) 필요한 Column: A, 예측된 Column: A, B, C => B, C와 같은 필요없는 Column이 얼마나 많이 포함되었는지를 측정 - Schema Linking Recall(SLR)
필요한 모든 열이 검색된 쿼리에 얼마나 포함되었는지에 관한 비율을 나타냄
EX) 필요한 Column: A, B, 예측된 Column: B => 필요한 A가 검색이 안되었기 때문에 SLR은 50%
스키마 링킹은 다음의 네 가지 방법을 테스트하였다.
- Single-Column Schema Linking (SCSL)
각 Column들을 개별적으로 평가하여 선별하는 방법 - Hybrid SCSL (HySCSL)
SLR을 향상시키기 위해 키워드 매칭을 추가 - Table-then-Column Schema Linking (TCSL)
먼저 관련있는 테이블을 필터링하고, 그 후 관련 열들을 필터링하는 방식(SCSL 보다 더 공격적인 방법) - Hybrid TCSL (HyTCSL)
SLR 향상을 위해 키워드 매칭을 추가
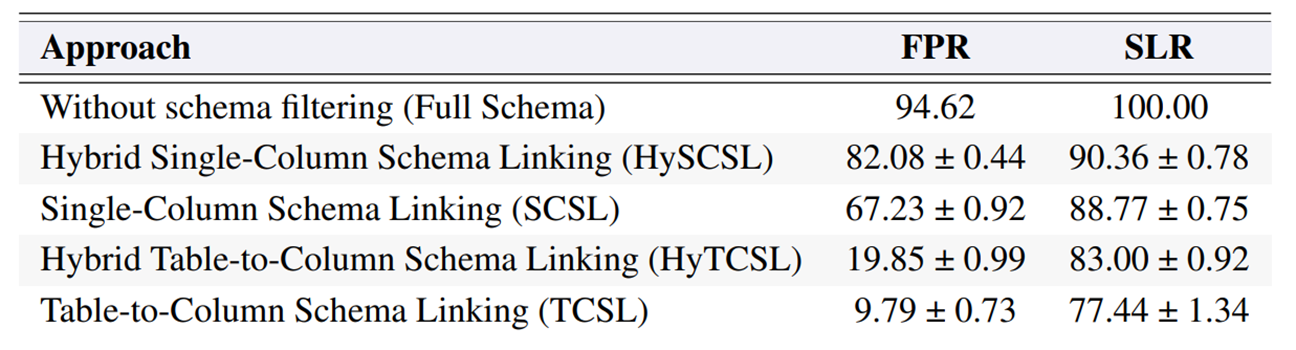
그림 2. 각 스키마 링킹 방법의 성능 평가
우선 Schema Linking 혹은 Filtering을 적용하지 않는 경우, 전체 테이블 스키마를 프롬프트에 전부 입력하기 때문에 당연히 SLR은 100이 나오고, FPR은 매우 높은 값이 나오는 것을 확인할 수 있다.
SCSL을 실행하면 SLR이 88, 키워드 매칭을 추가하면 90으로 높아지지만 그만큼 필요없는 데이터들이 더 많이 포함되기 때문에 FPR도 많이 증가한 것을 확인할 수 있다.
TCSL은 SCSL과 비교하여 FPR은 크게 확 줄어들지만, 그만큼 SLR이 더 낮아지는 것을 확인할 수 있다. 그렇다면 이러한 FPR과 SLR의 변화는 실제 SQL 생성에는 어떤 영향을 미칠까?
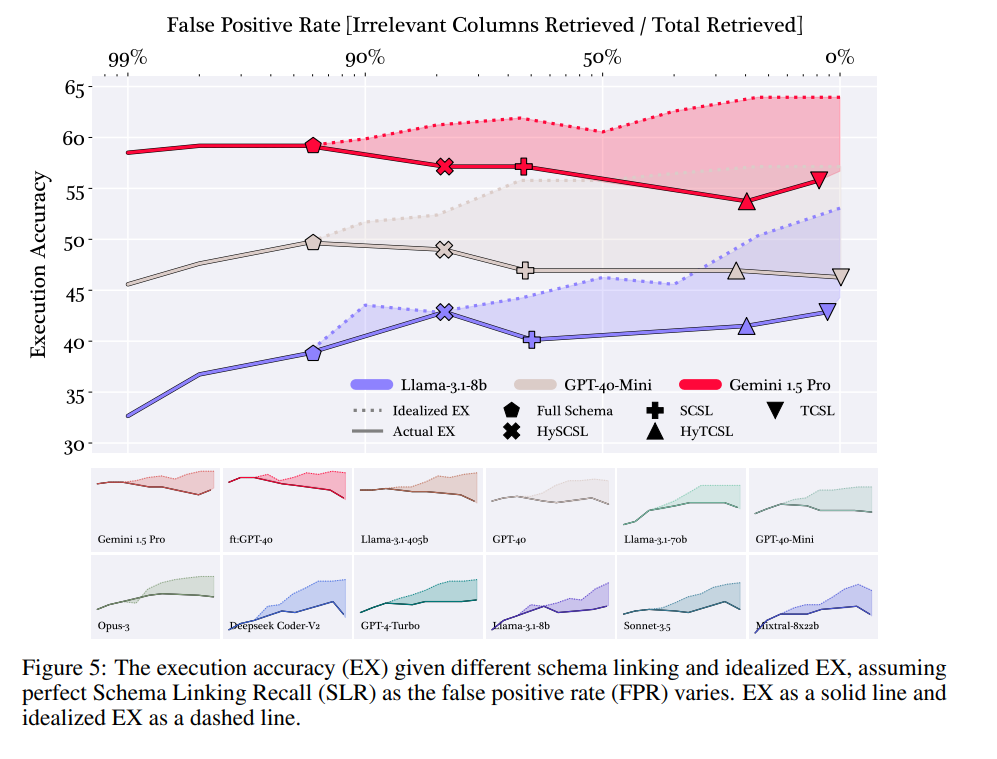
그림 3. Schema Linking 방법에 따른 Execution 정확도 비교
위의 그림에서 Dashed Line은 SLR이 100이라는 가정 하에 각 Schema Linking 성능을 나타내고, 실선은 실제 Schema Linking을 적용했을 때의 성능을 나타낸다. 우선, Schema Linking의 성능이 100인 상황을 인위적으로 만들었을 때는 당연히 FPR이 낮을수록 더 좋은 성능을 보이는 것을 확인할 수 있다. 하지만, 실제 상황에서는 FPR이 높을수록 SLR이 낮아질 수 밖에 없고, 이 때문에 FPR이 높은 방법들이 훨씬 낮은 성능을 보이는 것을 확인할 수 있다.
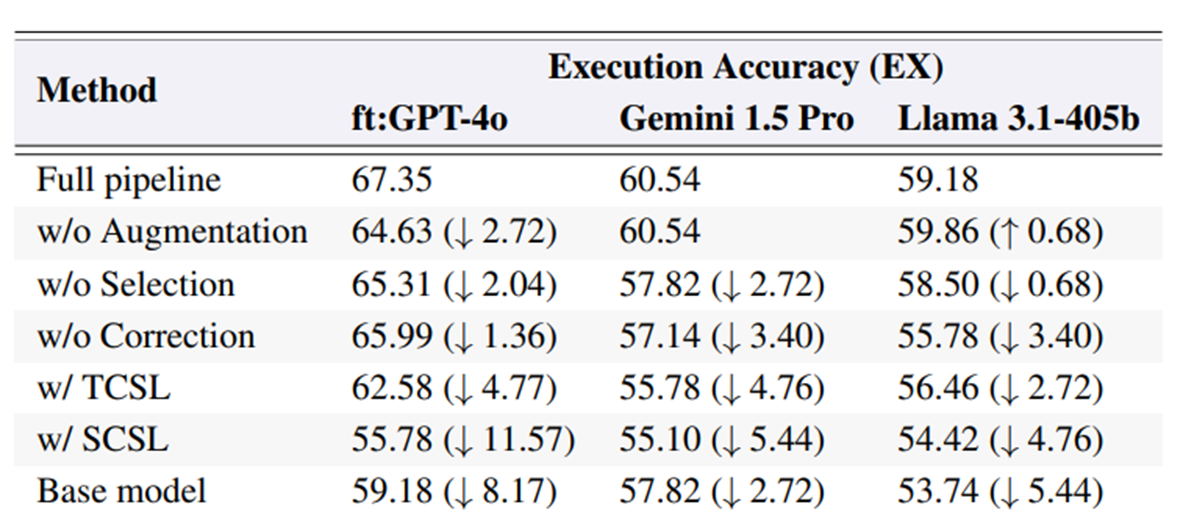
그림 4. Ablation Study
위의 그림은 각 모듈이나 요소를 제거했을 때의 성능 변화를 나타낸다. TCSL, SCSL은 오히려 모듈을 포함시키면 성능이 더 떨어지는 것을 확인할 수 있으며, 오히려 아무것도 적용하지 않은 Base model의 성능보다도 더 감소하는 것을 확인할 수 있다.
CHASE-SQL
다음은 CHASE-SQL 모델을 살펴보겠다.
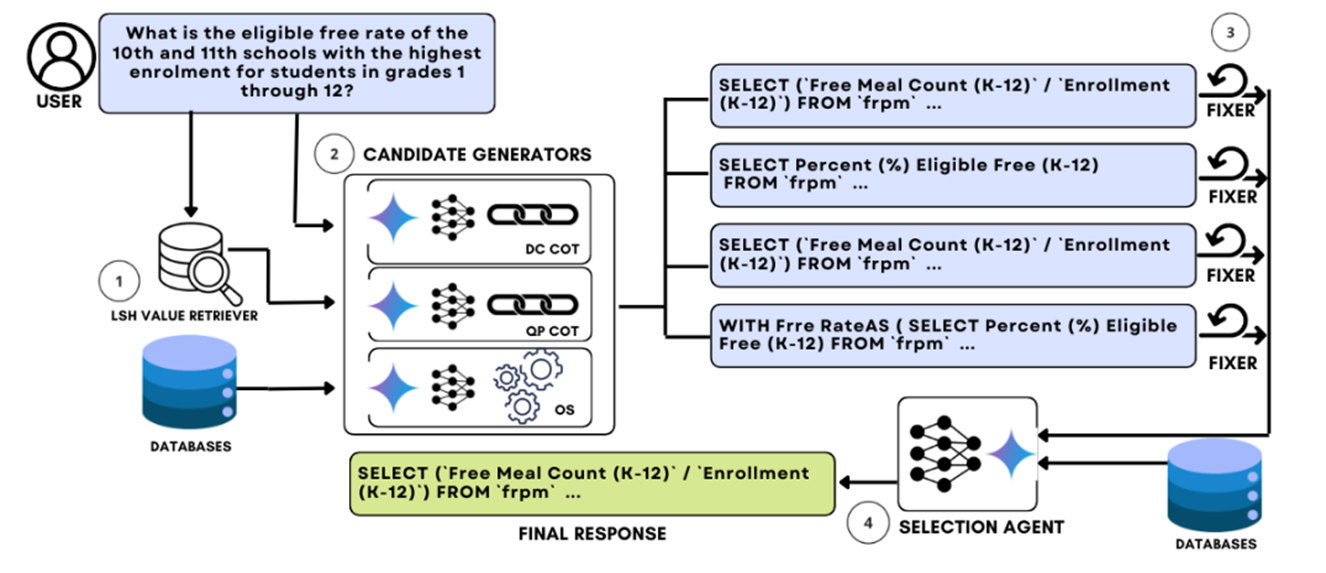
그림 5. CHASE-SQL의 모델 구조
위의 그림은 CHASE-SQL 모델의 구조를 나타낸다.
CHASE-SQL에서도 이전 논문에서 언급한 것과 같이 Schema Linking 모듈은 전체 파이프라인에서 빠져있는 것을 확인할 수 있다. 대신, 각 Column에서 필요한 데이터를 추출하는 Value Retrieval 과정은 포함되어 있다.
Value Retrieval은 이전 CHESS Model에서 Schema Linking을 진행할 때, 입력된 Question에서 주요 키워드를 추출한 것과 같이, 입력된 질문에서 핵심 키워드들을 추출하는 것으로 시작한다. 키워드 추출 방법은 CHESS와 똑같이 적용하였다. 이후, LSH(Locaility Sensitive Hashing)과 Semantic Embedding을 이용해서 가장 유사한 Value K개를 추출한다.
다음은 SQL Generation 단계이다. SQL Generation 단계에서는 최대한 다양한 특징을 가지는 SQL 후보들을 생성하기 위해서 세 가지의 생성 방법을 적용한다.

위의 Pseudo 코드는 Divide & Conquer COT 방법을 적용한 생성 방법을 나타낸다. 해당 방법은 이전에 보았던 모델들 중에서 Decompose 방법을 적용하는 것과 유사한 생성 방법이라고 볼 수 있다.
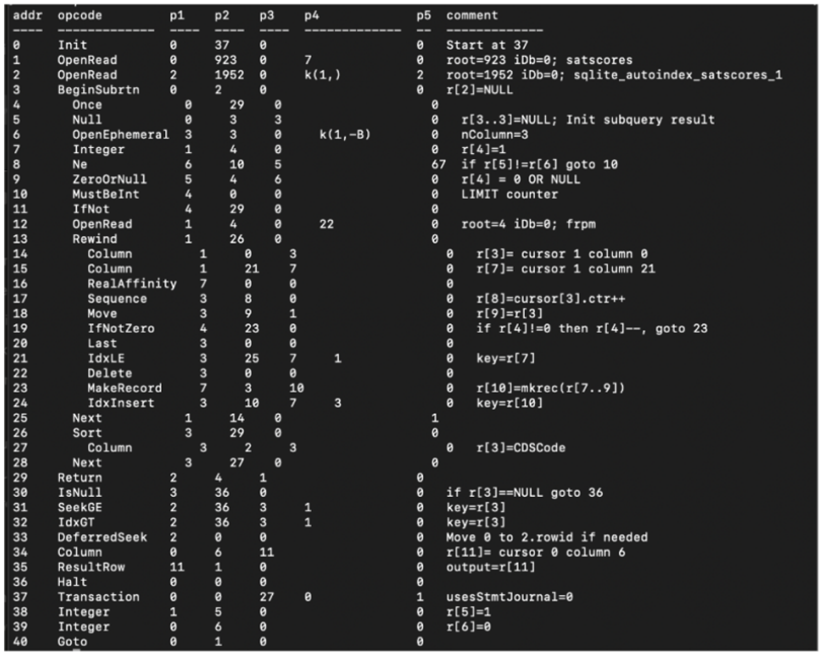
그림 6. SQL의 Query Plan 예시
SLQ Engine에 Explain 명령어를 실행하면 위의 그림과 같이 SQL 명령어가 어떤 프로세스를 통해서 실행되고, 어떤 자원을 가져오는지를 순차적으로 살펴볼 수 있다. 두 번째 생성 방법은 이러한 Query Plan에서 영감을 받아서 Query Plan을 Intermediate하게 생성하도록 하는 CoT 프롬프팅 방법을 적용하였다. 이때, Intermediate하게 생성하는 Query Plan은 좀 더 자연어에 가까운 예제들을 만들어서 In-Context Learning을 적용하였다.

그림 7. Query Plan CoT 프롬프트 예제
마지막 생성 방법은 Online Synthetic Example Generation을 이용한 방법이다. 이전 논문들을 살펴보면 Few-shot 예제들을 가져와서 In-Context Learning을 적용하는 방법을 많이 채택했다. 그러나, Few-shot 예제를 아무리 잘 가져오더라도 현재 입력된 Question과 완전히 결이 다른 Few-shot 예제들이 포함될 수 있고, 이러한 예제들은 오히려 성능에 안 좋은 영향을 줄 수 있다.

Online Synthetic example generation은 Schema Linking을 수행하고, 해당 과정을 통해서 추출된 관련있다고 예측된 스키마들을 기반으로 Question-Query Pair를 합성하도록 하고, 해당 합성된 예제들을 Few-shot In-Context Learning을 적용해서 SQL을 생성하는 방법이다.
SQL 후보 생성이 끝나면 Query Fixer와 Selection Agent가 적용된다.
Query Fixer는 만약 SQL 실행 중 에러가 발생하면 해당 에러 메시지와 프롬프트를 다시 입력해서 Syntax 에러를 교정하도록 하는 과정이다.
두번째로 Selection Agent도 CHASE에서 가장 중요한 부분인데, 세 가지의 Generation 전략을 통해서 다양한 특징을 가지는 SQL 후보들을 생성하였다. 이제 이 중에서 정답을 잘 선택해야만 좋은 성능을 얻을 수 있다.
Selection Agent는 이전 방법들과 다르게 생성된 후보들 중에서 두 개씩 선택을 해서 Binary Classification을 하고 최종으로 선택된 하나의 예제를 선택하도록 하였다.
입력의 순서에 따른 Bias를 제거하기 위해서 [입력1, 입력2], [입력2, 입력1]로 두 개의 입력을 만들어서 예측 확률을 구한다. CHASE에서는 Gemini Pro 1.5 모델을 사용하였는데, 이 모델에 그대로 Binary 분류를 해보았을 때는 정확도가 58% 밖에 나오지 않았다고 한다. 이에 Selection Agent는 Gemini Pro를 파인튜닝 시킨 모델을 적용하였다.
파인튜닝 데이터셋은 Bird의 학습 데이터셋을 이용해서 실제 정답과 다른 생성 결과가 나온 데이터들을 False 케이스로, 실제 정답과 일치하는 SQL 예측 Query들을 True 케이스로 적용하여 파인튜닝 데이터셋을 구축하였다.

오늘은 이전 글들을 포함해서 총 세 개의 글을 작성하는 동안 Bird Benchmark에 공개된 모델 중, 논문이 공개되어 있는 모델들을 살펴보았다.
확실히 이후로 갈수록 모델을 파인튜닝하거나, 후보를 많이 생성해서 최종 정답을 잘 선택하는 방식으로 발전이 되어가고 있는 것 같다. 하지만, 이렇게 되면 하나의 Question을 처리하는데 너무 많은 API 비용이나 시간이 들 수 있다.
이후 글에서는 지금까지 살펴본 내용을 바탕으로 로컬에서 실질적으로 돌려볼 수 있는 파이프라인의 모델을 하나씩 직접 구현해보려고 한다.