오늘은 이전 글, Bird Benchmark의 Text-to-SQL 논문 정리 – 1에 이어서 다음 논문들을 정리해볼 예정이다.
오늘 살펴볼 논문은 다음 두 가지이다.
E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL
CHESS: Contextual Harnessing for Efficient SQL Synthesis
E-SQL
- Text-to-SQL 작업을 엔터티 및 문맥 검색, 스키마 선택, 쿼리 생성의 3단계 파이프라인으로 분해
- 중요한 엔터티와 문맥을 추출하기 위한 확장 가능한 계층적 검색 접근 방식
- 개별 열 필터링, 테이블 선택, 최종 열 선택으로 구성된 효율적인 3단계 스키마 정리 프로토콜을 통해 최소한으로 충분한 스키마 추출
그림 1. 기존 Text-to-SQL 방법들의 구조
위의 그림은 일반적으로 적용되는 Text-to-SQL 모델들의 구조를 나타낸 것이다.
우선 Entity Retrieval은 Column 내에 존재하는 Value들이나 Column이나 Table의 Description 문장들을 Retrieval 하는 과정을 나타낸다. 이때, Value를 탐색할 때는 LCS를 많이 사용했지만 해당 방법은 몇 만개 혹은 몇 백만개가 될 수 있는 Value들을 모두 탐색하기에는 너무 오랜 시간이 걸릴 수 있다. 이에 BM25, LSH(Locality Sensitive Hashing) 등 다양한 방법이 함께 사용되곤 한다.
Schema Filtering은 전체 테이블 스키마(Table, Column)에서 답변에 필요한 스키마들만 선별하는 작업이다.
Decomposition은 Nested와 같은 구조를 가진 복잡한 질문을 처리할 때, 여러 개의 Sub-Question으로 나누어서 처리하는 방법이다.
SQL Query를 생성하는 방법론은 크게 2가지 방법론이 있다. 첫 번째는 여러 개의 SQL Query를 생성해서 가장 Consistent한 결과를 내는 SQL을 최종 결과물로 선택하는 Self-Consistency 방법이다. 두번째는 SQL Query 하나를 생성해서 해당 Query에 존재할 수 있는 에러들을 수정해나가면서 최종 결과물을 만들어나가는 Self-Correction 방법이다.
그렇다면 E-SQL에서는 이러한 기존 구조 외에 어떤 새로운 부분을 가지고 있을까?
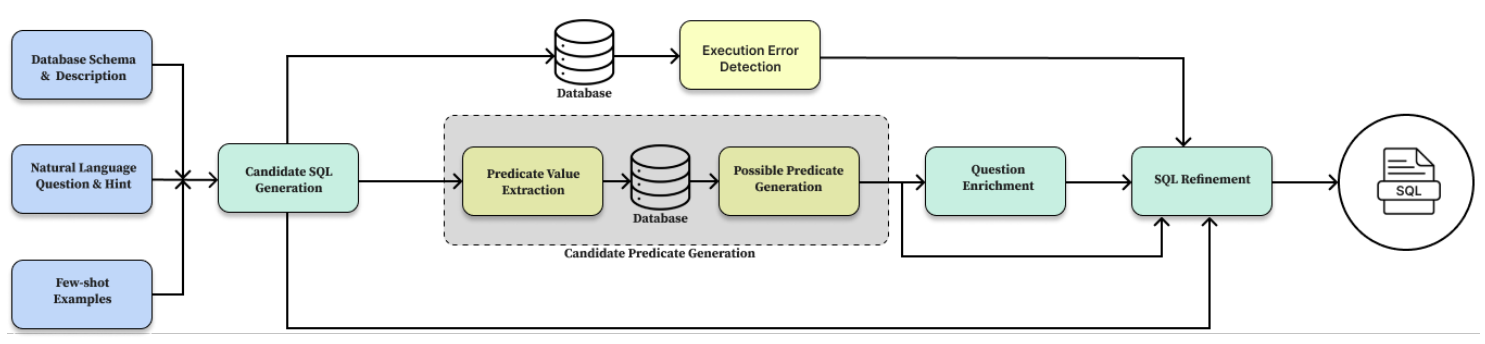
그림 2. E-SQL 모델의 구조
위의 그림은 E-SQL의 구조를 나타낸다. 그렇다면 그림 1의 구조와 어떤 부분이 달라진 것일까? 가장 크게 다른 부분은 Question Enrichment 모듈이 추가된 부분과 Schema Filtering이 생략된 것이라고 할 수 있다.
우선 Schema Filtering이 생략된 이유는 다음 글에서 더 자세히 다룰 논문에서 더 자세히 다루겠지만, Frontier LLM(GPT-4o, Gemini-Pro 등)을 사용할 때는 어차피 충분한 길이의 프롬프트를 입력하여 사용할 수 있고, 스키마 전체가 입력되더라도 LLM이 알아서 필요한 스키마를 걸러낼 수 있는 능력이 있으므로 굳이 Schema Filtering 과정이 필요없고 만약 꼭 필요한 스키마가 혹시라도 필터링된다면 모델의 성능에 악영향을 줄 수 있기 때문이다. 이에 E-SQL에서는 Schema Filtering 모듈을 생략하고 Pipeline을 구축하였다.
Candidate SQL Generation
Candidate SQL Generation에서 우선 Few-shot 예제, Schema, Description 등을 입력받아서 후보 SQL Query들을 생성한다.
생성된 SQL Query를 이용해서 Predictate Value Extraction 과정을 거쳐서 Possible Predictate Generation을 수행한다.
SQL Query가 제대로 생성되지 않는 유형은 아래와 같은 유형들이 있을 수 있다.



에러 유형중 하나를 자세히 살펴보면 “Frenso Country Office of Education”이 Value로 예측이 되어야 하지만, “Frenso”가 Value로 예측이 되어서 잘못 예측한 것을 살펴볼 수 있다. 이런 경우 아래와 같은 LIKE 연산자를 이용하는 명령어를 실행하면 “Frenso” 키워드를 통해서 발생할 수 있는 모든 Value들을 찾을 수 있고 이렇게 확장하여 찾은 Value들을 Refine 과정에서 사용할 수 있을 것이다.

이렇게 생성된 Possible Predictates는 Question Enrichment Module에서 사용된다.
Question Enrichment Module
Question Enrichment Module은 LLM의 Schema Linking 능력을 향상시키기 위한 방법이다.
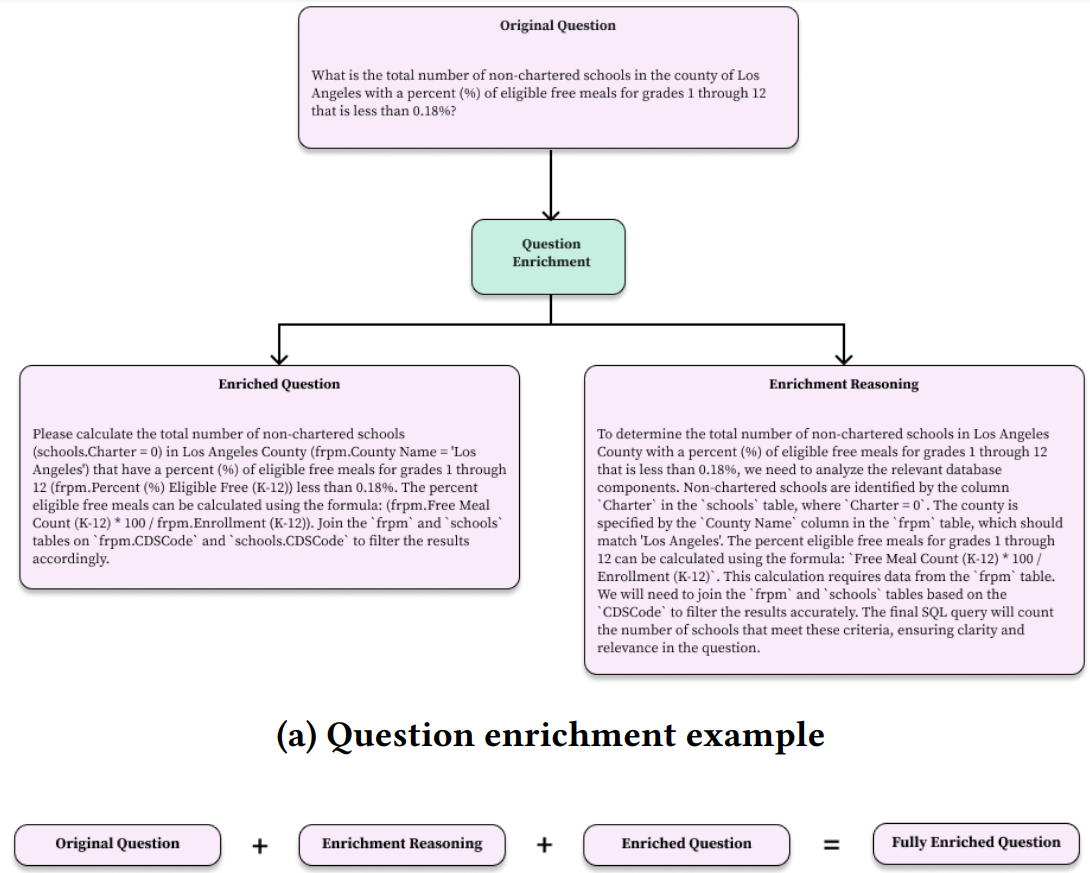
그림 3. Question Enrichment 예제
Question Enrichment는 Enriched Question과 Enriched Reasoning의 두 가지 결과를 생성한다. 우선 Enriched Question을 살펴보면 입력된 Question에 있는 각 엔티티들을 실제 테이블 스키마와 연결하여 Question을 보강하는 것을 확인할 수 있다. 예를 들어 Question에 “Los Angelus Country”라는 엔티티가 있다면 해당 엔티티는 “frpm.country Name = Los Angelus”와 같이 실제 테이블의 스키마를 기반으로 해당 엔티티가 어디에 해당하는지를 표시해준다.
Enriched Question도 마찬가지로 SQL로 변환을 하는 과정에서 해당 엔티티는 어떤 내용인데 어떤 추론을 거쳐서 어떻게 변환을 해야할지를 미리 생성하는 것을 확인할 수 있다.
Question Enrichment 모듈에는 이전의 Candidate SQL Generation 과정에서 생성된 Possible Predictates이 입력된다.
Question Enrichment 성능을 높이기 위해서 few-shot 예제를 추가하는 방법을 적용했는데, Bird의 Dev 데이터셋에 해당 태스크를 정답을 수작업으로 구축하고, 실제 실행 과정에서 Dev 데이터셋에서 랜덤하게 3개의 예제를 추출하여 사용하였다. 랜덤한 예제는 서로 다른 난이도의 예제가 선택되도록 하였다.

위의 그림은 Question Enrichment 모듈의 프롬프트의 일부를 캡쳐한 그림이다. {변수명} 부분이 프롬프트에 함께 입력되는 입력 변수들이다.
Predictate and Error-Aware SQL Refinement
해당 모듈에서는 Database Schema, Candidate Predictate, Enriched Questions를 입력하고 이전 Candidate SQL Generation에서 생성된 SQL Query들을 교정하도록 하였다. 해당 모듈에서는 생성되었던 SQL 쿼리를 가져와서 교정하여 출력하거나 혹은 생성된 후보들 중 맞는 것을 선택하여 그대로 출력할 수 있다.
CHESS
다음으로 살펴볼 모델은 CHESS이다. E-SQL은 Schema Filtering 과정을 생략하고, Question-Enrichment 과정을 추가해서 LLM의 Schema Linking 능력을 향상하려는 시도를 하였다.
CHESS 모델은 이와는 조금 다르게 Context Retrieval, Schema Selection과 같은 과정에 Hierarchical Retrieval 접근 방법을 적용해서 더 세부적으로 적용하고자 하였다.

그림 4. Text-to-SQL에서의 다양한 어려운 부분
위의 그림은 Text-to-SQL의 다양한 Challenge들을 나타낸다. 예를 들어 유저의 질문은 데이터베이스에 저장되어 있는 값들과 직접적으로 연결되지는 않는다. 그렇기 때문에 Database에 존재하는 ambiguos한 table, column, value들은 text-to-sql을 더욱 어렵게 만든다. 또한, 같은 결괏값을 생성하더라도 SQL 쿼리는 다양한 형태로 표현될 수 있다. CHESS는 이러한 부분을 어느정도 해결하기 위해 다음과 같은 시도를 하였다.
- Text-to-SQL 작업을 엔터티 및 문맥 검색, 스키마 선택, 쿼리 생성의 3단계 파이프라인으로 분해
- 중요한 엔터티와 문맥을 추출하기 위한 확장 가능한 계층적 검색 접근 방식
- Individual Column Filtering, Table Selction, Final Column Selection으로 구성된 효율적인 3단계 Schema Pruning 프로토콜을 통해 효율적으로 필요한 Schema를 추출ㅁㄴㅇㅁㄴ
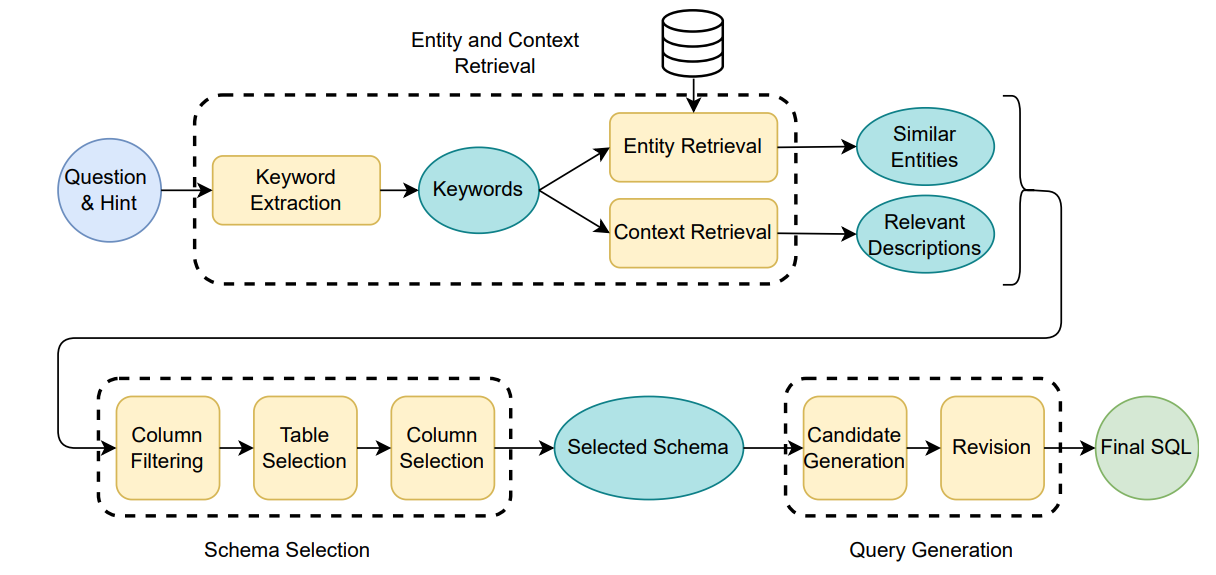
그림 5. CHESS 모델의 PIPELINE 구조
위의 그림은 CHESS 모델의 구조를 나타낸다. 우선 다른 부분들은 이전 모델과 비슷하지만, 가장 핵심이 되는 부분은 세 개의 단계로 이루어진 Schema Selection 부분이라고 볼 수 있다. 우선 차례대로 하나씩 파이프라인의 모듈들을 살펴보겠다.
Entity & Context Retrieval
Text-to-SQL에 필요한 Column의 Value들을 찾거나 Table이나 Column의 Description 문장들을 탐색하는 부분이다.
Entity와 Context를 Retrieval하기 전에 Keyword Extraction 과정이 먼저 적용되었는데, 해당 과정은 LLM에 사용자가 입력한 질문을 넣고 해당 질문에서 키워드들을 모두 추출하도록 하는 것이다. 이후 과정에서는 추출된 키워드를 기반으로 필요한 Entity와 Context를 탐색한다.
Entity Retrieval은 LCS, BM25, LSH 등 다양한 방법들이 적용되고 있는데, 해당 논문에서는 LSH와 Semantic Similarity(Emhedding)을 이용하여 Entity를 탐색하였다.
Context도 마찬가지로 추출된 키워드들과 가장 유사한 문장들을 추출하였는데, 여기에도 벡터 DB를 이용한 Semantic Similarity가 사용되었다.
Schema Selection
다음으로 Schema Selection이다. 해당 모듈의 목적은 Schema를 Narrow Down해서 결국에는 SQL 생성에 꼭 필요한 스키마만 남기는 것이다.
- Individual Column Filtering
해당 과정에서는 데이터베이스에 포함된 수백 개의 열 중에서 질문과 의미적으로 관련이 없는 열들을 제거하고, 관련있는 열들만 Table Selection 단계로 넘긴다. 열 하나만 보고 복잡한 스키마들의 관계를 고려할 수는 없기 때문에 해당 부분은 간단하게 적용하고 넘어간다. - Table Selection
필터링된 열들을 바탕으로 SQL 쿼리 생성에 필요한 테이블을 선택하는 단계이다. - Final Column Selection
마지막 단계에서는 필요한 열만 남기기 위해서 필터링된 테이블의 열을 평가한다. 각 열의 필요성을 CoT 설명과 함께 모델에 제시하고, 필요한 열만 선택하도록 하는 방법이다.
Query Generation
Query Generation 단계는 Candidate Generation과 Revision의 두 가지 단계로 이루어져 있다.
Candidate Generation 단계는 이전 과정을 통해 얻은 스키마를 프롬프트에 입력하여 SQL Query들을 생성하는 단계이다.
Revision 단계에서는 나타날 수 있는 Logical 에러나 Syntatic 에러를 찾아내기 위해서 생성된 Query를 LLM에 입력하고 교정하도록 한다. LLM에는 Temperature를 0으로 설정하더라도 매번 다른 답변이 나올 수 있고, SQL은 다른 답변의 형태를 가지고 있더라도 같은 결과를 생성할 수 있다. 이를 고려하여 Self-Consistency를 이용해서 여러 개의 샘플 중에 최종 SQL query를 생성하도록 하였다.
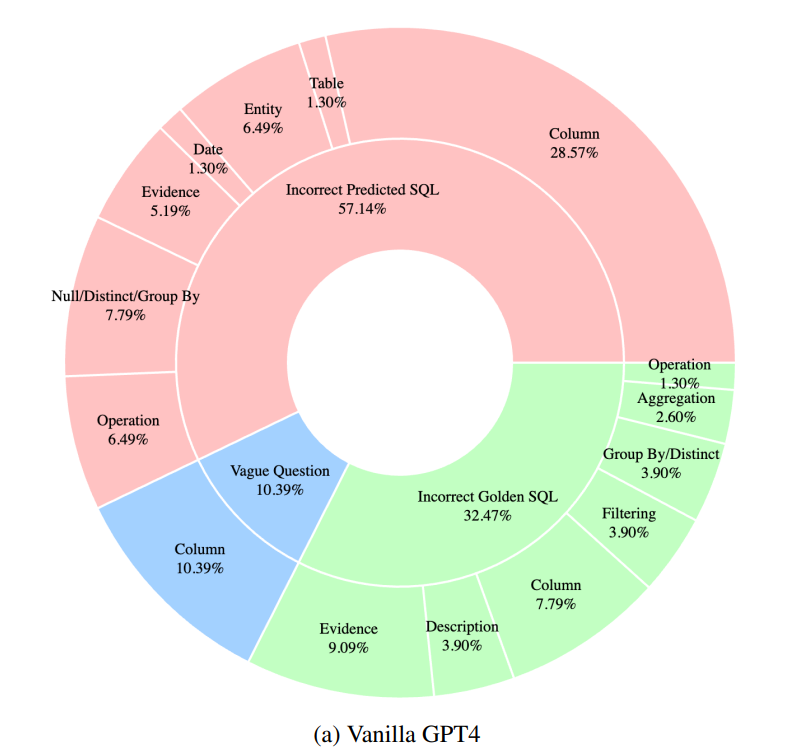
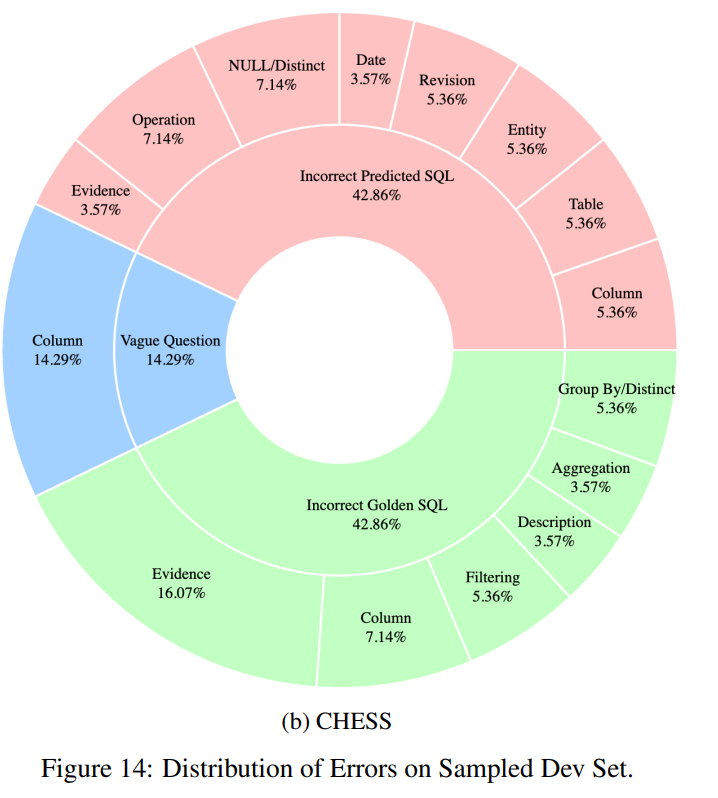
위의 그림은 GPT-4o와 CHESS 모델 간의 에러 분포를 나타낸다. CHESS 모델의 에러 분포를 살펴보면 Incorrect Predicted SQL에서 Column과 관련된 에러의 비율이 크게 감소한 것을 확인할 수 있다.
이번 글에서는 E-SQL과 CHESS의 두 가지 모델을 살펴보았다. 많은 Text-to-SQL을 살펴보면서 서로 공통적으로 나타나는 모듈들이 많아지고 있다. 하지만 그럼에도 E-SQL과 CHESS는 서로 다른 방향으로 모델을 구성한 것을 볼 수 있었다.