오늘 작성할 글은 Bird Benchmark 리더보드에 등록되어 있는 모델들의 논문을 차례대로 정리해보려고 한다.
![]()
|
논문명 |
날짜 |
|
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction |
2023.04 |
|
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation |
2023.11 |
|
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation |
2023.12 |
|
DTS-SQL: Decomposed Text-to-SQL with Small Large Language Models |
2024.02 |
|
CodeS: Towards Building Open-source Language Models for Text-to-SQL |
2024.02 |
|
Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation |
2024.05 |
|
The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models |
2024.07 |
|
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL |
2024.10 |
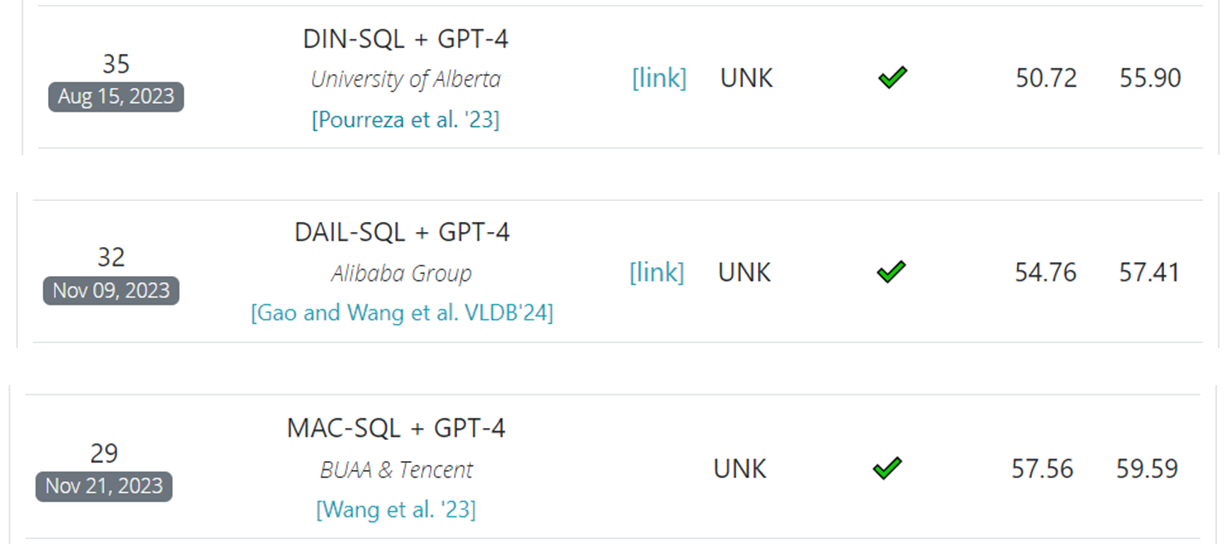
위의 테이블은 Bird에 올라와있는 논문들을 시간순으로 정리한 것이다. 리더보드에서의 성능이 아닌 논문이 Arxiv 등에 처음 올라온 날짜를 기준으로 정리하였다.
이 중에서 오늘 첫번째 글에서 다룰 논문은 다음의 3가지 논문이다.
DIN-SQL
우선 가장 먼저 DIN-SQL을 살펴보겠다.
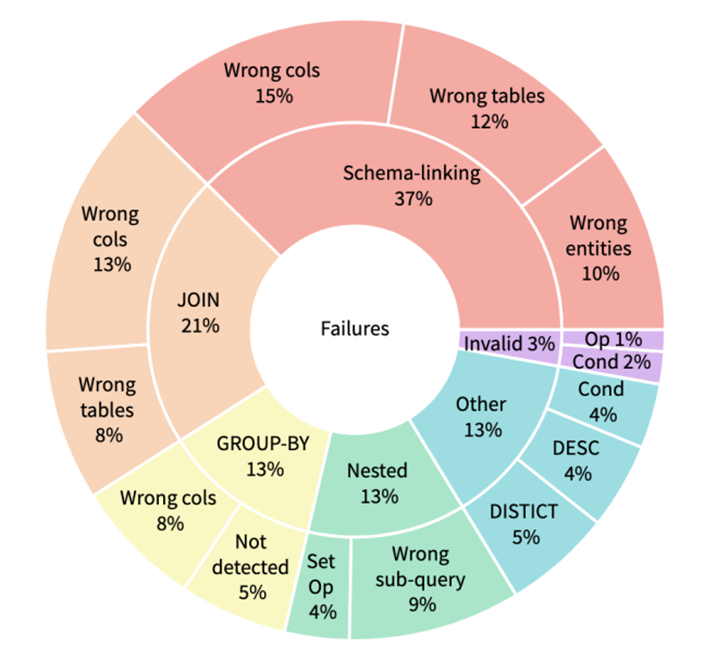
그림 1. Text-to-SQL에서 발생하는 에러의 종류 분석
위의 그림은 Text-to-SQL에서 발생하는 에러의 종류들을 분석한 것이다. 각 에러 종류들을 살펴보면 다음과 같다.
- Schema Linking
에러 중 가장 많은 부분을 차지하고 있따. Column, Table Name, Entitiy 등을 제대로 인식하지 못하고 잘못 선택하는 경우이다.
예를 들어 “What are the average and maximun capacities for all stadium?”이라는 질문이 입력되었을 때, Average 연산을 수행해야 하는 경우에서 “Select avg …”와 같이 avg라는 단어가 포함된 column을 선택하는 오류를 발생시킬 수 있다.
- Join
두 번째로 많이 발생하는 에러는 Join과 관련된 부분이다. Join으로 합쳐야 하는 테이블들을 제대로 인식하지 못하거나 혹은 Join을 위한 Foriegn Key를 제대로 인식하지 못하는 경우이다.
- Group By
Group By가 뒤따라와야하지만 생성되지 않거나, 혹은 잘못된 Column에서 Group By를 적용하는 경우이다.
- Queries with nesting and set operations
Nesting된 구조를 제대로 인식하지 못하거나, 혹은 Set Operation을 제대로 감지하지 못하는 경우이다.
- Invalid SQL
Syntax 에러가 발생하는 경우이며, 자주 등장하지는 않음.
- 기타 등등
Where 절에서 불필요한 조건 생성이 생성되는 경우 혹은 중복된 Distinct나 DESC가 발생하는 경우 등 나머지 에러들을 분류한 것이다.
DIN-SQL에서는 언급한 해당 에러들을 개선하기 위한 구조를 적용하고자 하였다. 일반적으로 논리적인 추론이 필요한 태스크에서는 CoT 혹은 Least-to-Most와 같은 프롬프트 기법들이 많이 사용된다. 하지만 해당 논문에서는 Text-to-SQL 태스크는 Declarative하고 실행 가능한 단계들의 경계가 불명확하기 때문에 해당 프롬프팅 기법들이 적합하지 않다고 하였다. 대신, CoT처럼 Step by Step으로 풀 때 다음과 같은 단계로 나누어 SQL을 실행하는 것이 효율적이라고 하였다.
- 관련있는 Table과 Column들을 인식하기
- 더 복잡한 쿼리를 만들기 위해서 일반적인 구조의 Query를 인식하기 (Group By, Nesting, Multiple Joins, Set Operations 등)
- Sub-Component로 만들 수 있는 쿼리들을 여러 단계로 분할하기
- 분할된 각 Sub-Component들을 하나씩 해결하며 변환해나가기
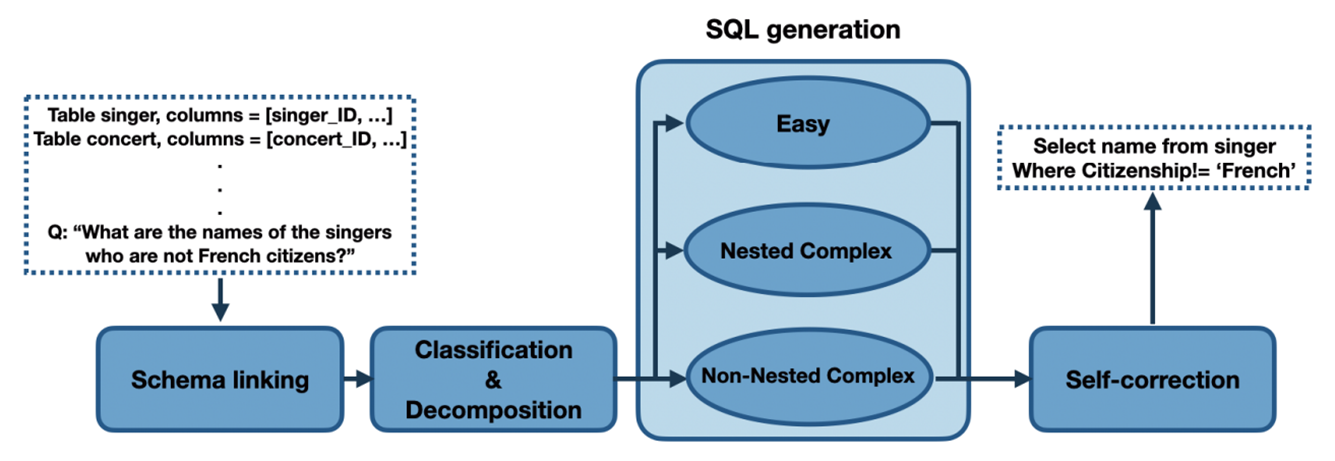
그림 2. DIN-SQL 모델의 전체적인 구조
위의 그림은 DIN-SQL 모델의 전체적인 구조를 나타낸다. 위에서 언급한 4가지 단계 중에 1은 Schema Linking에 해당한다고 볼 수 있고, Classification & Decompose 단계에서 2, 3의 단계를 수행한다. 마지막으로 SQL Generation 단계에서 4의 단계를 수행한다.
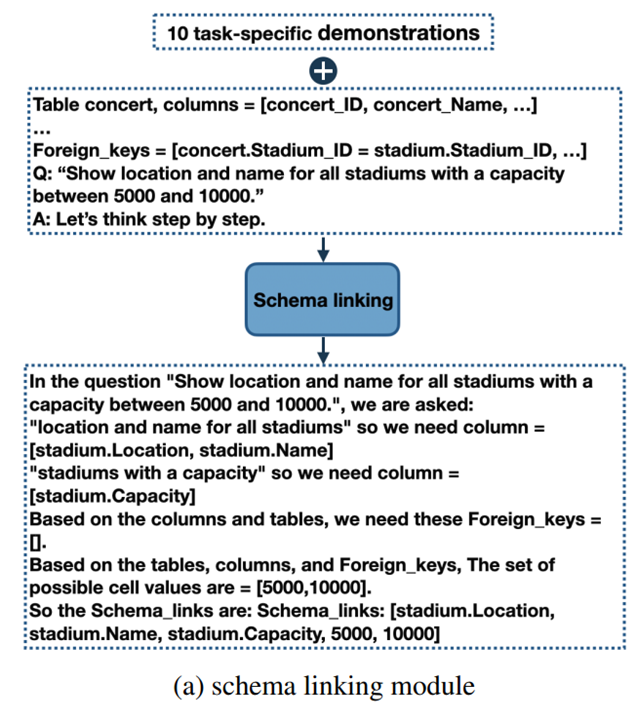
그림 3. Schema Linking 모델의 구조
위의 그림은 Schema Linking 모델의 구조를 나타낸다. 해당 단계에서는 다양한 데이터베이스 스키마를 입력받고, 질문과 관련있는 스키마를 선별하게 된다.
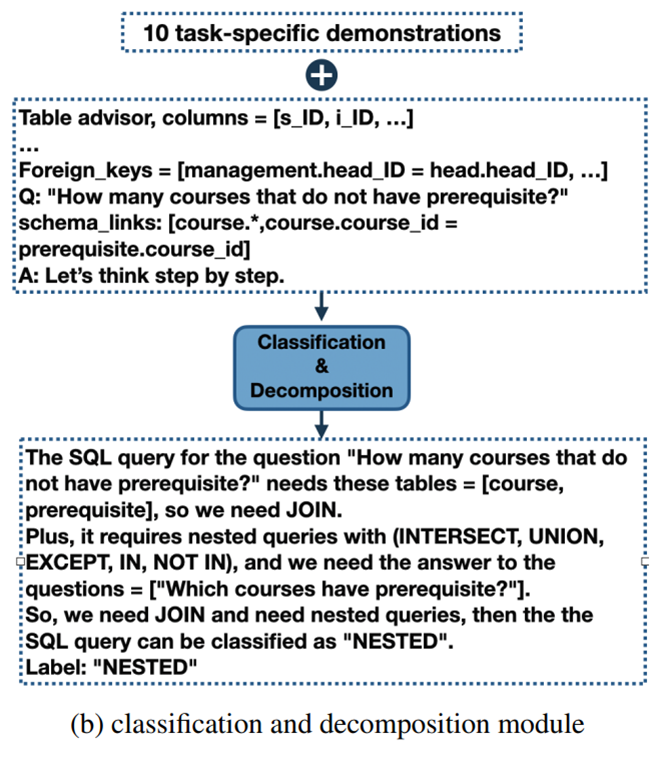
그림 4. Classification & Decompose 모듈
Classification 과정에서는 먼저 질문의 난이도를 세 가지로 분류한다.
- Easy: Single Table로 처리할 수 있는 간단한 구조
- Non-nested Complex: Join을 통해서 여러 테이블로 처리해야 하지만, Nested 구조가 없는 구조
- Nested Complex: Nested 구조가 포함된 복잡한 구조
Decompose 과정에서는 Nested Query의 Sub-Query들을 예측하고, Join할 테이블들을 예측하는 태스크를 수행한다.
SQL Generation 과정에서는 분류된 난이도에 따라서 각각 다른 생성 과정을 거친다.
- Easy: 바로 SQL로 변환.
- Non-nested Complex: Intermediate 표현 값으로 먼저 변환하고, Intermediate를 최종 SQL로 변환. Intermediate는 “Join On, From, Group By”와 같은 SQL에서 사용되는 특수한 명령어들을 제거한 자연어와 최대한 비슷하도록 만든 SQL 쿼리이다.
- Nested Complex: 질문을 Sub-Query로 분해하고 분해된 쿼리들을 하나씩 변환하면서 최종 SQL을 생성한다.
마지막으로 Self-Correction Module은 이전 SQL-Generation 단계에서 생성한 SQL 쿼리를 최종 점검하고 보완하는 단계이다.
이 방법은 Zero-shot 방법으로 수행되며, 실행한 SQL 쿼리에서 오류가 발생했을 때 수행된다. 프롬프트는 “생성한 쿼리에 버그가 있으니까 수정해줘”라는 뉘앙스의 Generic Prompt와 “생성한 쿼리에 버그가 있을수도 있으니까 수정해줘”라는 뉘앙스의 Gentle Prompt가 있다. GPT-4에서는 Gentle Prompt를, CODEX 계열의 모델에서는 Generic 프롬프트를 사용했다고 하였다.
DAIL-SQL
다음으로 살펴볼 논문은 DAIL-SQL을 발표한 “Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation”이다.
해당 논문은 프롬프트 형식, 예시 선택, 예시 구성 등 프롬프트 엔지니어링 방법을 체계적으로 비교하고 장단점을 분석하였다.
프롬프트 형식
먼저 텍스트 표현 부분을 살펴보면 Basic Prompt, Text Representation Prompt, OpenAI Demonstration Prompt, Code Representation Prompt의 네 가지 방법의 프롬프트를 비교하였다.

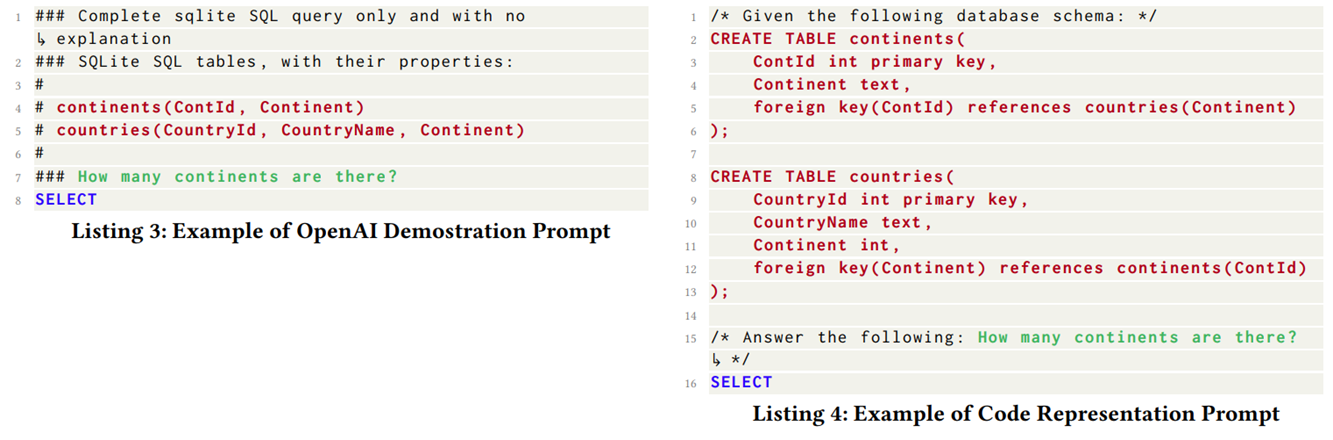

위의 그림은 네 가지의 프롬프트 형식을 나타낸다. Basic은 말 그대로 데이터베이스 스키마를 단순하게 나열한 것을 나타내며, Text REpresentation은 자연어에 가까운 형태로 나열한 것을 나타낸다. OpenAI Demonstration Prompt는 OpenAI의 Text-to-SQL 태스크의 프롬프트를 이용한 것이며, Code Representation은 코드 형식으로 데이터베이스 스키마를 나열한 것을 나타낸다.
In-Context Learning
In-Context Learning은 별도의 Finetuning을 하지 않고, 프롬프트 내에 예제를 추가하여 추가된 예제에서 태스크를 학습하여 성능을 높이는 방법이다. In-Context Learning에서는 Finetuning처럼 몇 만개의 데이터를 모두 학습할 수 없기 때문에, 정말 도움이 되는 예제들을 잘 선별하여 프롬프트에 포함시키는 것이 중요하다.
- Random
가장 기본적인 예제 선택 방법으로 전체 데이터셋에서 K개의 데이터셋을 선택하는 방법이다.
- Question Similarity Selection
입력된 자연어 질문을 임베딩 벡터로 변환하고, 전체 학습 데이터셋에서 입력된 질문의 임베딩 벡터와 가장 유사한 벡터를 가지는 질문의 데이터셋을 선택하는 방법이다.
- Masked Question Similarity Selection
SQL 쿼리에서 Domain-Specific한 부분을 Masking 처리하고 유사도를 구하는 방법이다. Domain-Specific한 부분은 Column Name, Table Name 등이 있을 수 있다.
- Query Similary Selection
Question Similarity Selection과 이름이 유사하여 헷갈릴 수 있는데, 해당 방법은 In-Context Learning 없이 SQL로 먼저 변환을 하여 예측 쿼리를 생성하고, 해당 쿼리의 임베딩과 가장 유사한 벡터를 가지는 SQL 쿼리를 가지는 K개의 데이터셋을 학습 데이터셋에서 선택하는 방법이다.
DAIL-SQL에서는 Masked Question Similarity Selection과 Query Similarity Selection을 혼합하여 적용하였다. 먼저 Query Similarity Selection을 먼저 적용하기 위해서 SQL 쿼리를 In-Context Learning 없이 생성한다. 생성된 쿼리와 유사한 임베딩 벡터의 SQL 쿼리를 가지는 데이터를 학습 데이터셋에서 선별하는데, 이때는 유사도가 특정 임계치보다 높은 데이터들만 따로 선별한다.
선별된 데이터셋 중에서 Masked Question Similarity Selection을 실행해서 가장 유사한 임베딩 벡터를 가지는 K개의 데이터를 최종적으로 선택한다.
Example Organization
선택된 데이터를 프롬프트에 포함시킬 때, 어떤 형태로 포함시킬지 결정할 필요가 있다. 해당 논문에서는 Full-Information, SQL-Only Organization, DAIL Organization의 세 가지 방법을 비교하였다.
Full Organization은 전체 데이터를 다 포함시키는 방법, SQL-Only는 SQL 데이터만 포함시키는 방법이고, DAIL은 매핑된 자연어 질문-SQL 쿼리 쌍을 포함시키는 방법이다.


다음은 프롬프트 방식에 따른 Text-to-SQL의 성능 비교이다.
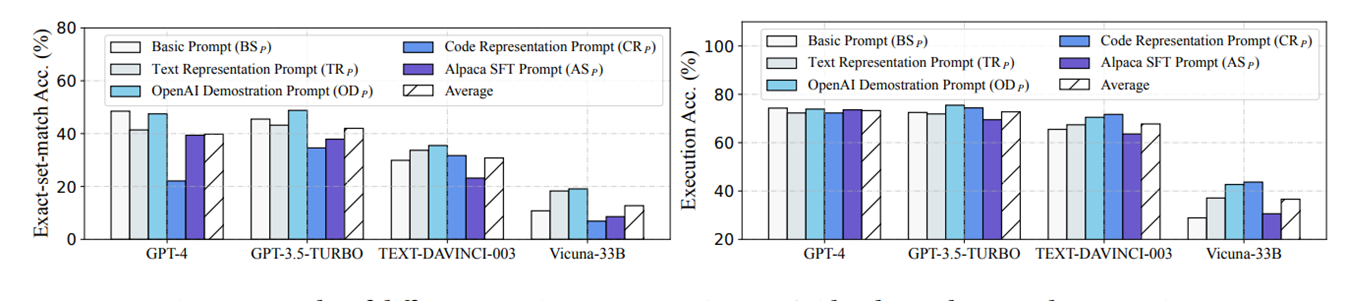
모델에 따라서 효과적인 프롬프트 방식이 조금씩 차이가 나는것을 확인할 수 있다.
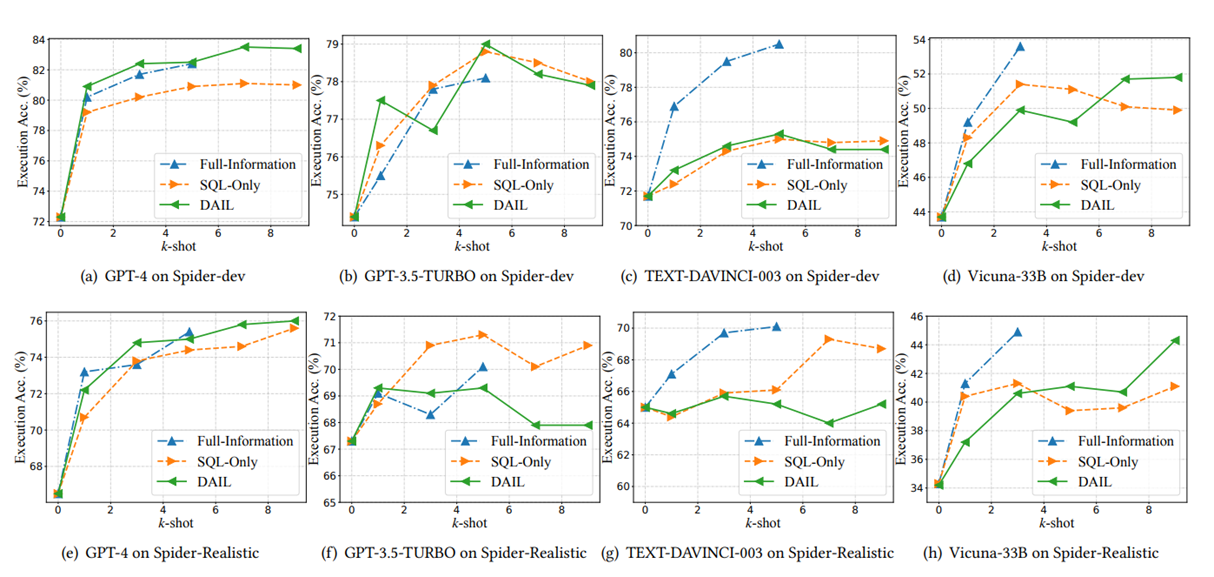
다음은 Few-Shot Learning의 데이터 갯수와 Data-Organization을 다르게 설정했을 때의 성능 변화를 나타낸다. 당연하게도 많은 데이터를 포함하고 있는 Full-Organization이 낮은 K에서 대체로 좋은 성능을 내고 있지만, 데이터의 개수가 높아질수록 API 호출 비용이나 모델의 실행 시간 및 비용이 기하급수적으로 증가하기 때문에 K=5까지만 실험을 한 것을 확인할 수 있다.
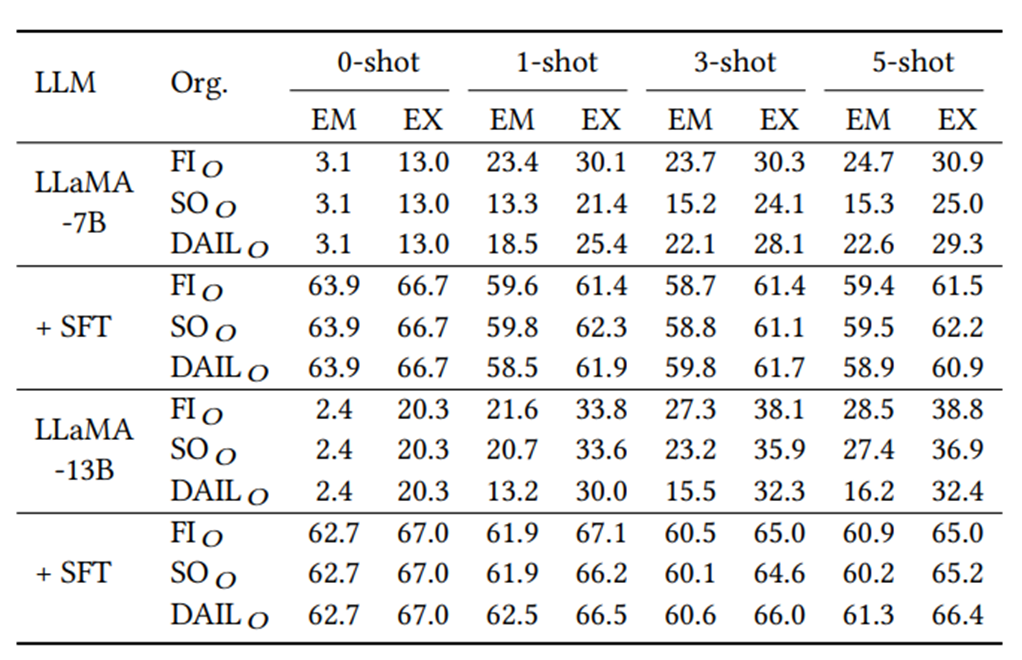
위의 그림은 LLaMA-7B 모델을 SFT를 통해 파인튜닝했을 때의 성능 비교이다. 당연하게도 파인튜닝을 했을 때는 프롬프트의 형식이나 Data-Organization 등에는 영향을 잘 받지 않는 것을 확인할 수 있다. 또한 Few-Shot 예제가 프롬프트에 포함될 때 오히려 성능이 감소하는 것을 확인할 수 있다.
MAC-SQL
마지막으로 살펴볼 모델은 MAC-SQL이다.
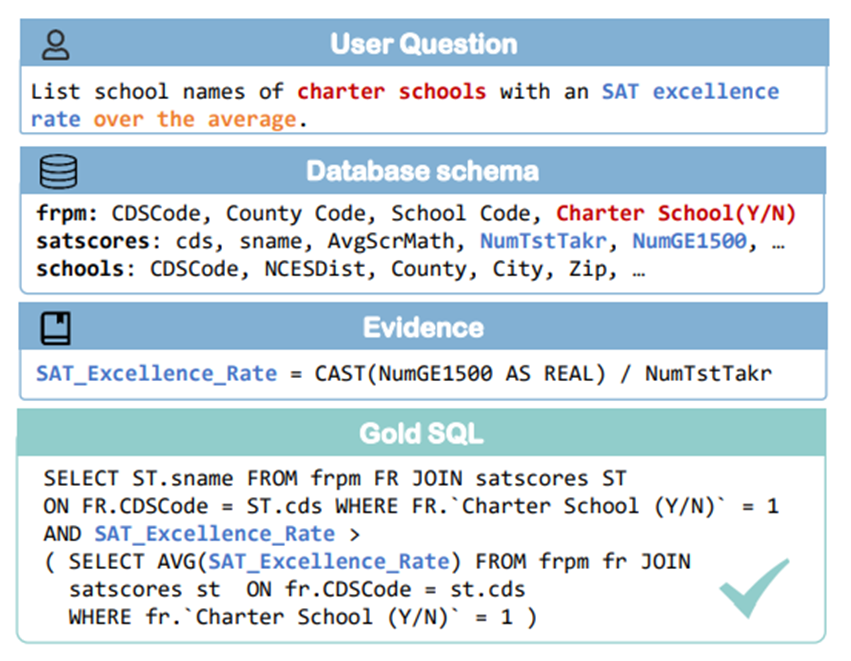
그림 5. Text-to-SQL 태스크 예제
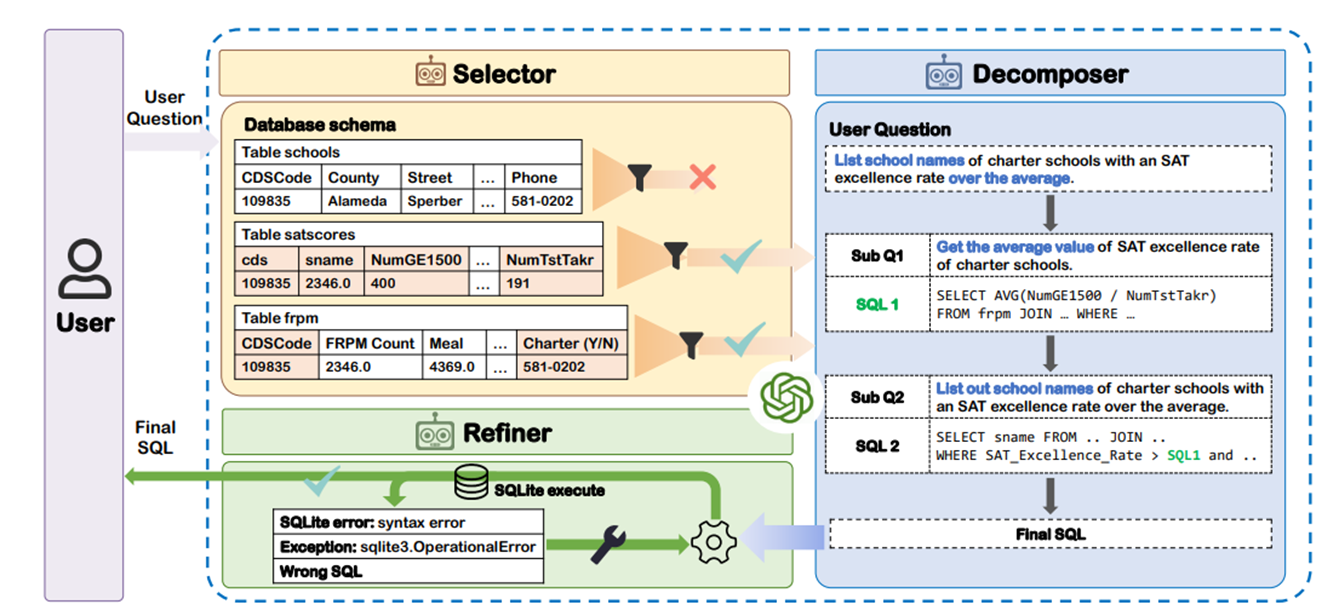
그림 6. MAC-SQL 모델 구조
위의 그림은 MAC-SQL의 구조를 나타낸다. 해당 모델은 Selector, Decomposer, Refiner의 3가지 컴포넌트로 이루어져 있다.
Selector
필요한 데이터베이스 스키마를 선별하는 컴포넌트이다. 불필요한 스키마 항목이 프롬프트에 포함되는 것을 방지하고, 필요한 스키마 항목을 잘 선별하기 위한 컴포넌트인데, 만약 스키마의 전체 길이가 임계 값을 넘지 않을 때는 해당 컴포넌트를 스킵한다.
Decomposer Component
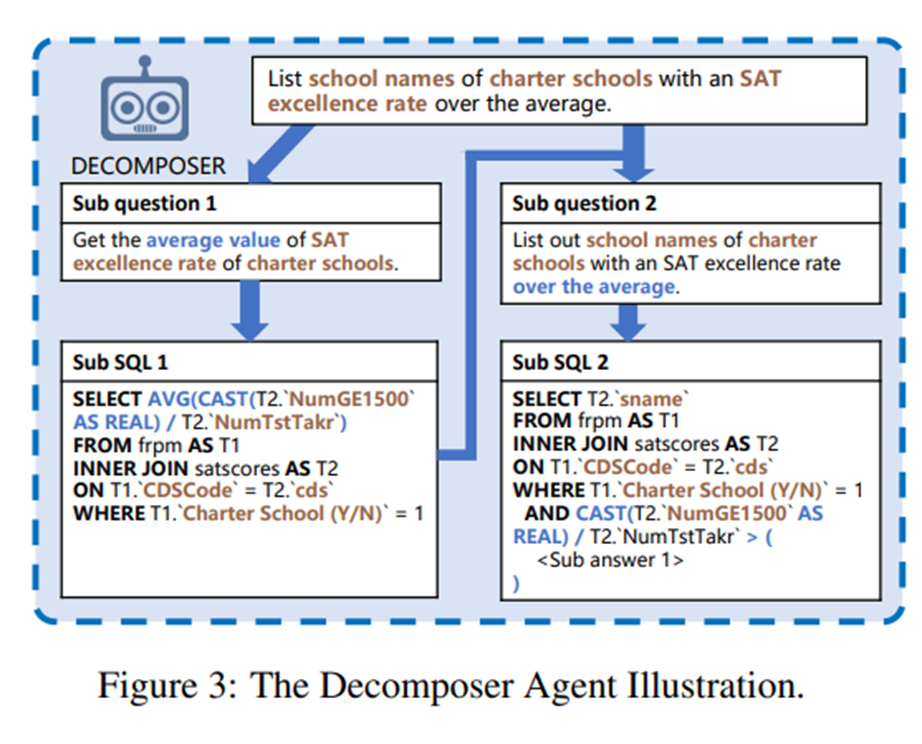
위의 그림은 Decomposer 컴포넌트의 구조를 나타낸다. Decomposer은 Question을 여러 개의 Sub-Question으로 변환하고 Sub-Questions을 하나씩 SQL로 변환하여 합쳐간다.
Refiner

다음은 Refiner인데, 해당 모듈은 Syntax 에러가 난 SQL 쿼리를 Syntax 에러문과 함께 입력하여 에러를 교정하도록 하는 모듈이다.
Supervised Finetuning
MAC-SQL의 각 컴포넌트에서 수행한 내용들을 Instruction Dataset으로 구축하고 Code-LLama-7B로 파인튜닝하는 실험을 진행했따. Selector, Decomposer, Refiner의 태스크를 학습시키는 Multitask 학습을 진행하였다.
Result
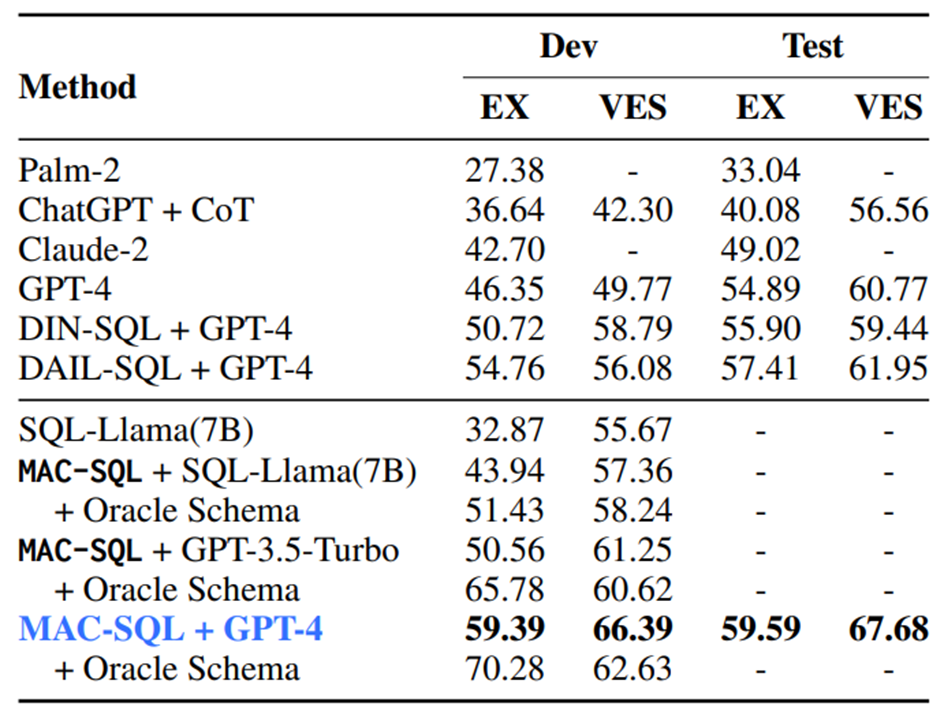
위의 그림은 MAC-SQL 모델의 성능을 나타낸다. Oracle Shema는 Selector를 실행하지 않고, 정말 필요한 스키마만을 입력하여 실행한 결과를 나타낸다. 즉, Selector 모델의 Upper bound 성능이라고도 볼 수 있다.
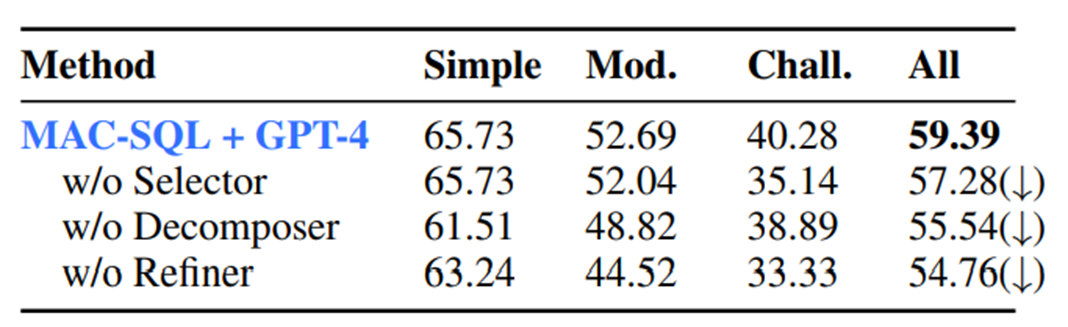
다음은 Ablation Study 결과이다. 의외로 Refiner 모듈을 제거 했을 때, 성능이 가장 크게 하락하는 것을 확인할 수 있다.
이번 글에서는 Bird 벤치마크의 리더보드에 등록된 모델들을 순서대로 살펴보았다.
시간 순서대로 최신 모델까지 이어서 계속 글을 작성할 예정이다.