오늘은 저번 글에서도 자주 등장했던 BIRD 데이터셋을 공개한 논문인 “Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs”을 설펴보겠다.
우선, BIRD는 Text2SQL 태스크의 벤치마크 데이터셋 중 하나이다. Text2SQL 태스크는 자연어 질문을 SQL로 변환하고 그것을 SQL Engine에서 실행시켜 자연어 질문에 대한 답을 얻는 태스크이다. 해당 데이터셋이 등장하게 된 배경을 살펴보자면, 우선 Text2SQL 태스크의 목적은 비전문가가 해당 시스템이나 모델을 통해서 관계형 데이터베이스에서 원하는 데이터셋을 추출하는데에 있다. 그런데, 기존에 있던 벤치마크인 SPIDER나 WIKISQL과 같은 데이터셋들은 LLM이 등장하면서 매우 높은 성능 향상을 보여주었는데, 예를 들면 SPIDER 리더보드에서는 LLM이 등장하면서 약 53.5%의 성능에서 85.3%까지 증가하였다. 그렇다면 이런 의문이 들 수 있다: “Can LLM alreay serve as a database interface? (LLM은 이미 데이터베이스 인터페이스로 사용될 수 있는건가?)”. 이에 대한 답은 당연하게도 “아니요”이다. LLM들이 거의 만점에 가까운 성능들을 내고 있는 벤치마크들은 실제 사용 시나리오와는 너무나 다른 단지 몇 개의 데이터베이시의 Row들을 사용하여 정답을 출력하는 방식으로 구성되어 있기 때문이다.
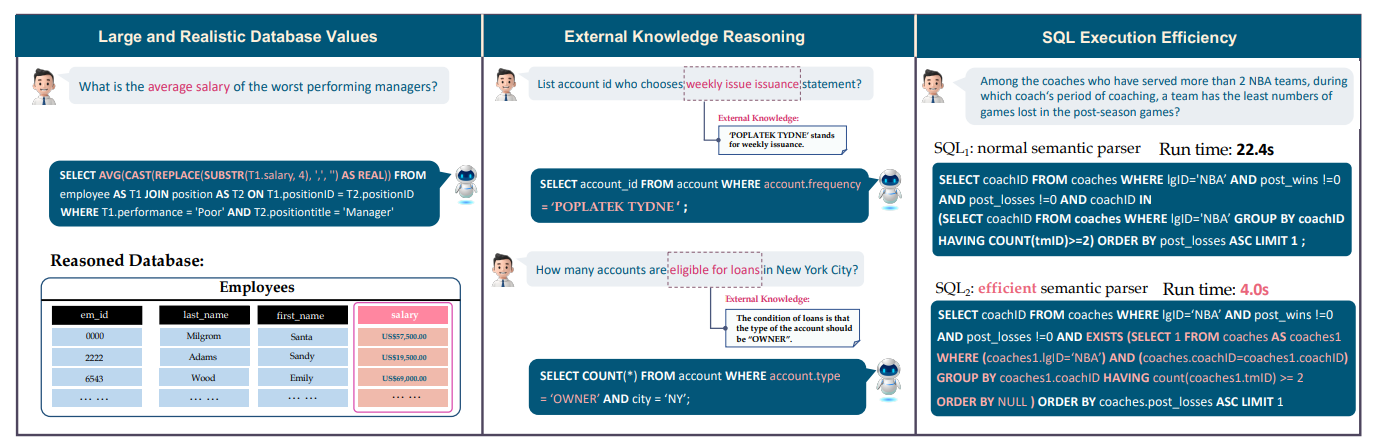
그림 1. BIRD 벤치마크의 예시
위의 그림은 BIRD 벤치마크의 예시를 나타내는데, 기존 벤치마크와의 차이를 살펴보면 다음과 같다. 우선 첫번째로 실제 SQL에서 사용되는 데이터베이스들은 몇 만개 혹은 몇 백만 개와 같이 무수히 많은 Row들을 포함하고 있는 경우가 많다. 또한, 노이즈가 제거된 깔끔한 데이터셋들만을 가지고 있는 경우가 극히 드물다. 둘째, 데이터가 커질수록 Context 안에는 필요한 데이터를 모두 담기 힘들수 있고, 이에 추가적인 외부지식이나 추론이 요구될 수 있다. 셋째, 기존의 벤치마크들은 SQL 실행의 효율성을 전혀 고려하고 있지 않지만, 이는 실제 Real-life 어플리케이션에서는 매우 중요한 문제이다.
BIRD는 이러한 기존 벤치마크들의 한계점들을 개선하여 만들어진 데이터셋으로 12,751개의 데이터로 구성되어 있으며, 37개의 전문적인 도메인의 33.4GB에 해당하는 크기의 데이터베이스를 이용한다.
Dataset Construction
아래의 그림은 BIRD 데이터셋의 Annotation 과정을 나타낸다.
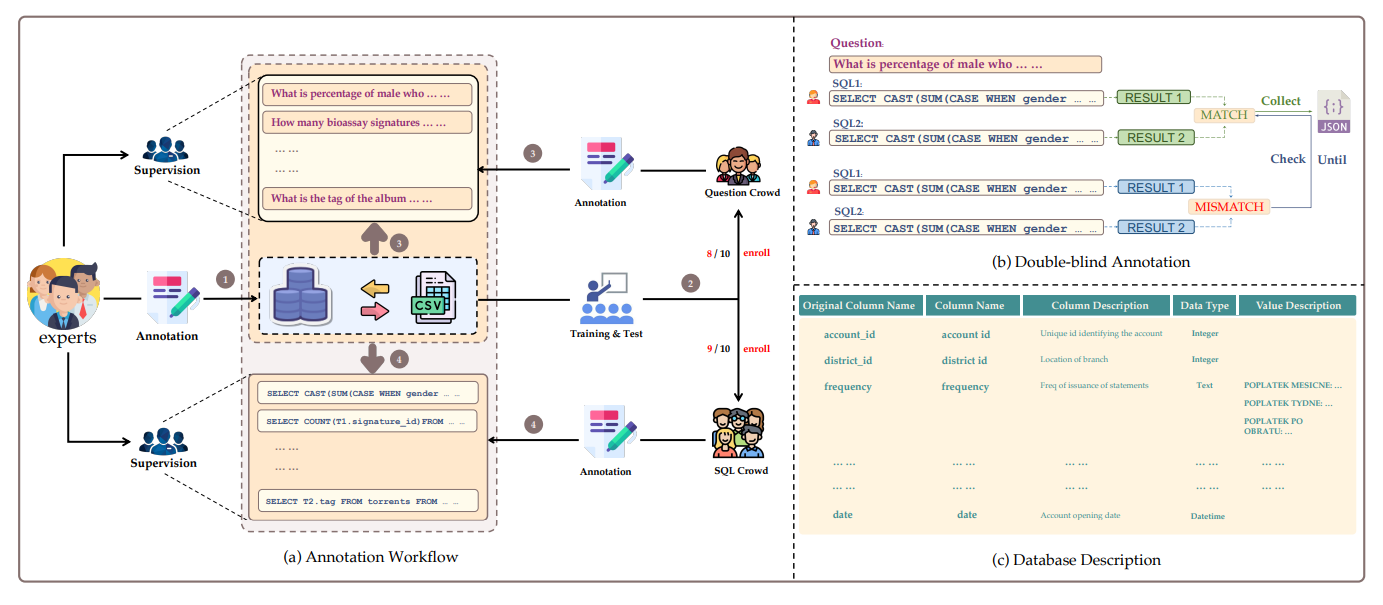
그림 2. BIRD 데이터셋의 Annotation 과정
Database Source
보통 이러한 데이터셋의 구축에는 개인정보 보호 문제로 적절한 데이터베이스를 구하는 것이 가장 어려운 일이다. 해당 논문에서는 실제 데이터베이스에 내용을 보강하는 방식으로 구했는데, 우선 32%의 데이터베이스는 Kaggle에서 구하였다. 다른 48%의 데이터베이스는 CTU Prague Relational Learning Repository에서 구하였다. 해당 플랫폼은 Multi-Relational 데이터를 이용한 머신러닝 연구 공개 플랫폼이다. 남은 20%의 데이터셋은 공개되어 있는 테이블 데이터를 이용하거나, 데이터를 합성하는 등의 방법을 통해서 생성된 데이터베이스를 이용하였다.
External Knowledge Evidence
자연어 명령어를 실제 데이터베이스의 값과 mapping하기 위해서는 External Knowledge Evidence가 요구된다. 해당 논문에서는 이러한 Knowledge를 4가지 종류로 분류하였다.
- Numeric Reasoning Knowledge: 이 카테고리는 SQL 명령어에서 명확한 수학적 연산을 요구로 하는 부분을 나타낸다. 여기서는 8개의 일반적인 수학 Operation과 4개의 복잡한 Operation이 포함된다. (MINUS, ADDITION, DIVISION, MULTIPLY)
- Domain Knowledge: 해당 지식은 domain-specific한 지식들을 요구하는 유형이다. 예를 들어 은행 업무의 사업 데이터를 분석할 때는 금융 관련 지식들이 요구된다.
- Synonym Knowledge: 이 유형은 다른 Phrase의 표현을 가지고 있지만 같은 의미나 혹은 비슷한 의미를 가지는 구문들을 처리할 수 있도록 하는 유형이다.
- Value Illustration: 이 유형은 데이터베이스의 value, value type, value category, mapping combinations of columns and values와 같은 데이버에스의 상세한 Description을 나타낸다. 예를 들어 professional_basketball 데이터베이스에서 “center”는 “pos = C”와 같이 표현될 수 있다.
아래는 데이터셋의 대략적인 통계에 관한 정보들을 나타낸다.

그림 3. 데이터셋의 통계
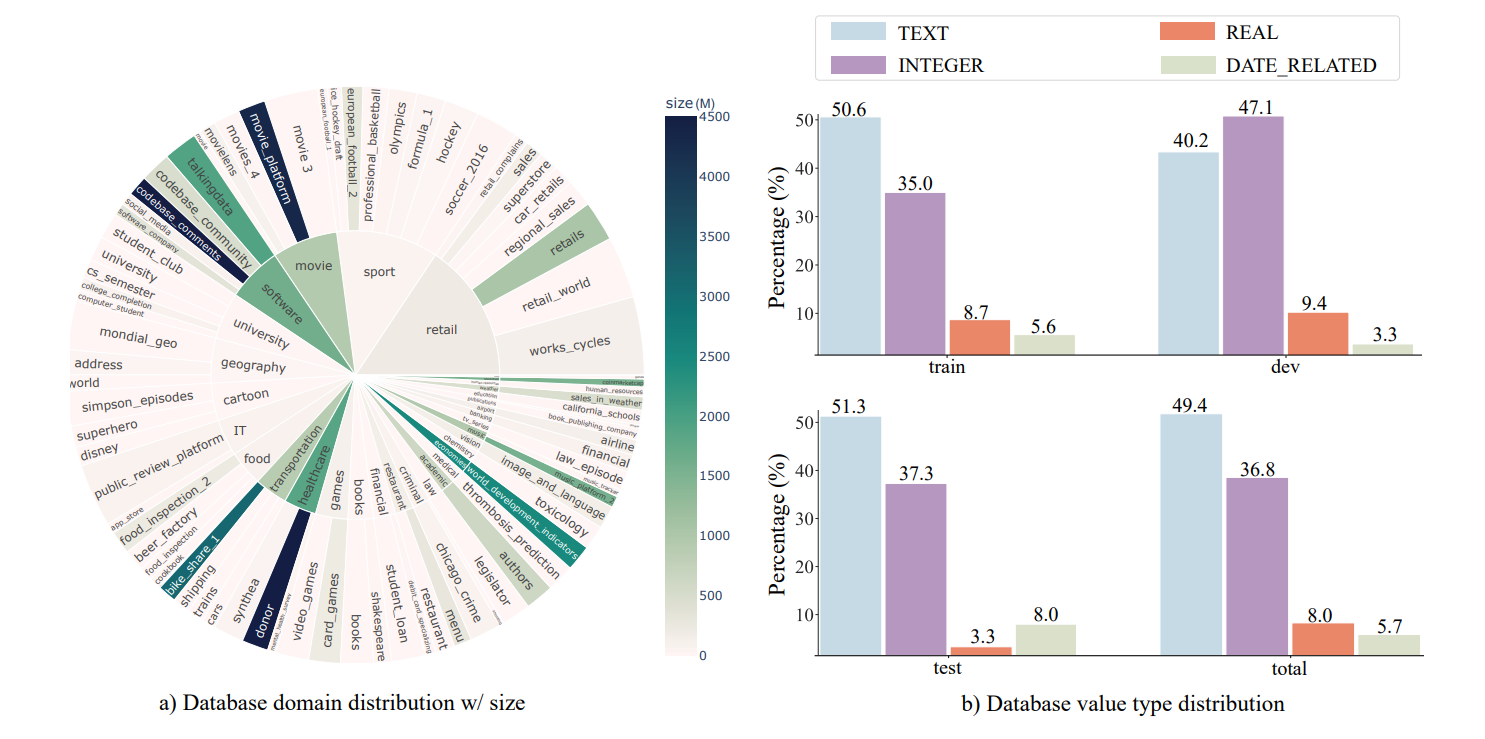
그림 4. 데이터셋의 도메인 분포
이번 글에서는 Text2SQL 태스크 관련 벤치마크인 BIRD를 살펴보았다. 기존의 벤치마크인 SPIDER나 WIKISQL은 LLM이 등장하면서 거의 만점에 가까운 성능을 내고 있지만, 해당 벤치마크들은 실제 데이터베이스에 적용하기에는 너무나 다르기 때문에 실제 SQL 사용 환경과 가까운 벤치마크를 제안하였다.