오늘 살펴볼 논문은 “ADVERSARIAL RETRIEVER-RANKER FOR DENSE TEXT RETRIEVAL”이다.
해당 방법은 GAN에서 Generator와 Discriminator를 minimax 방법을 이용해서 joint하게 학습시켰던 것에서 영감을 받아 AR2(Adversarial Retriever-Reranker) 학습 방법을 제안하였다.
GAN에서는 Generator와 Discriminator의 두 모델이 joint하게 학습되듯이, AR2에서는 Reranker와 Retriever가 그러한 방향으로 학습된다.
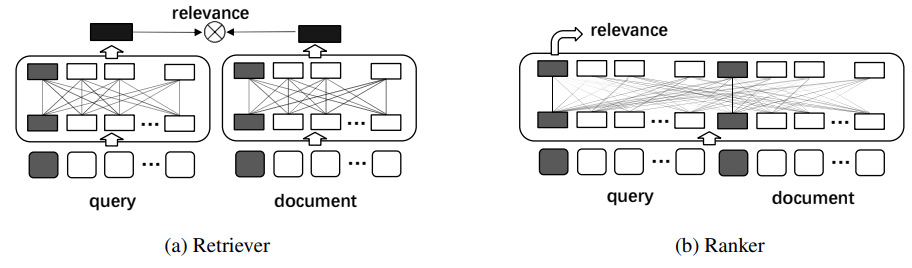
그림 1. AR2 모델의 두 모듈
일반적으로 Cross-Encoder를 이용하는 Reranker 모델이 Bi-Encoder를 사용하는 Retriever보다 더 좋은 성능을 낼 수 밖에 없다. 그렇기 때문에 Reranker 모델을 Teacher 모델로 삼아서 지식 증류와 같은 방법으로 학습시키는 방법들이 다수 제안되었었다. 해당 논문에서는 단순하게 지식 증류를 하는 것 뿐만 아니라 학습된 Reranker 모델이 Retriever의 학습에 관여하고, 반대로 학습된 Retriever 모델이 Reranker의 학습에 관여하는 적대적 학습 방법을 적용하였다.
Reranker 모델을 학습할 때, 그럴싸한 Negative 데이터를 넣어주는 것이 중요하다. 이때, 그럴싸한 Gold Negative 문서가 태깅되어있다면 좋겠지만 대부분은 그렇지 않다. AR2는 Reranker의 학습에서 그럴싸한 문서를 찾고, 그럴싸한 문서를 입력해주는 것을 이용하여 적대적 학습을 진행한다.

그림 2. AR2 모델 Pseudo Code
빠른 이해를 돕기 위해서 이번 글에서는 수식 대신 코드를 중심으로 설명하겠다.
우선 Pseudo Code를 살펴보면 모델의 학습은 두 개의 단계로 나누어져, 두 개의 단계가 반복적으로 학습이 된다. 각 단계에서는 Reranker 및 Retriever의 각 모델의 가중치만 업데이트 된다. Retriever 모델의 학습 단계에서는 Retriever 모델을 학습시켜서 Reranker를 학습할 때 그럴싸한 Negative 데이터를 찾아줄 수 있도록 하는것이 목표이다.
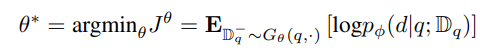
수식 8
수식 8을 보면 Retirever의 가중치를 업데이트해서 Reranker에서 확률이 높게 나오는 데이터를 찾도록 하는 것이 목표인 것을 확인할 수 있다. 하지만 Retriever와 Reranker는 별개의 모델이기 때문에 다음과 같은 목표로 모델을 직접 업데이트하는 것이 불가능하다. 이에 해당 논문에서는 이를 대체하는 upper-bound loss를 찾아서 설정하였다.
해당 부분이 어떻게 구현되고 동작하는지 살펴보기 위해 실제 코드를 살펴보겠다.
(코드는 해당 페이지에서 상세하게 확인이 가능하다)

그림 3. AR2 Retriever 모델의 학습 부분
그림 3을 보면 Loss는 normal_loss와 adv_loss의 두 가지로 이루어진 것을 확인할 수 있다. normal_loss는 retriever의 예측 분포가 Reranker의 예측 분포와 가까워지도록 학습하는 일반적인 방법이다. 여기서 adv_loss가 해당 논문에서 제안하는 학습 방법을 위한 loss인데, total_loss를 학습하게 되면 Reward를 Maximization 하는 방향으로 학습하게 된다. 그렇다면 Reward는 어떤 경우에 높아지고, 어떤 경우에 낮아지는 걸까?
Reward가 만들어지는 부분을 살펴보면 실제 Positive 문서의 Logits 값과 나머지 문서에서 나온 Logits 값을 Softmax하여 구하는 것을 확인할 수 있다. 이렇게 되면 Reward의 값은 Positive Logits의 값이 더 많은 차이로 더 큰 값을 가질수록 커지게 된다. 여기에 Retriever의 예측 확률 값을 곱해주게 되는데, 이렇게 되면 Reranker 모델에서 높은 확률이라고 예측하고 있는 데이터를 Retriever도 높은 확률로 예측했을 때 Reward가 커지는 것을 확인할 수 있다.

그림 4. Reranker 모델의 학습 부분
그림 4는 Reranker 모델의 Loss를 만드는 코드를 나타낸다. Reranker는 기존과 같은 방법으로 학습되기 때문에 코드도 단순한 것을 확인할 수 있다. 하지만 여기서 한가지 다른점은 Retriever가 학습되고 나서 벡터DB를 Refresh하게 된다. 그리고 Refresh된 벡터DB에서 Reranker가 학습하기 위한 Negative 데이터를 뽑아준다. 그렇기 때문에 이전 학습 단계에서 Retriever가 잘 학습될 수록 Reranker 모델이 더 잘 학습될 수 있다. 마찬가지로 Reranker가 더 잘 학습되면 Retriever도 Reranker의 예측 확률을 이용하기 때문에 더 잘 학습된다.
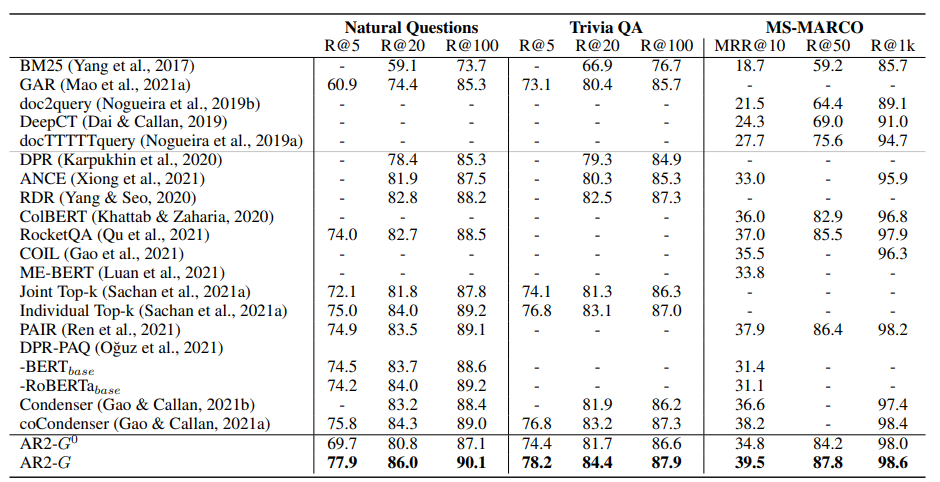
그림 5. AR2 Retriever의 성능
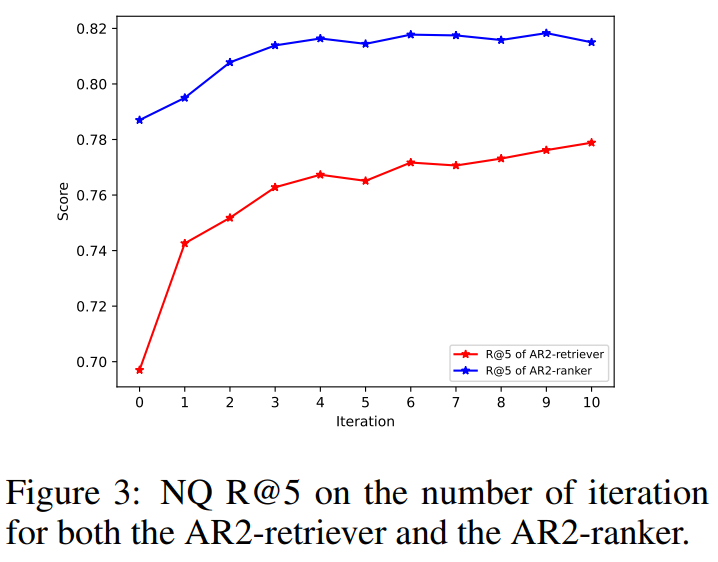
그림 6. AR2 학습 Epoch에 따른 성능 변화
위의 그림을 살펴보면 AR2 학습을 반복하면서 Retriever의 성능이 큰 폭으로 증가하는 것을 확인할 수 있다. 또한 Reranker 모델도 Retriever 만큼의 큰 폭은 아니지만 큰 폭으로 성능이 향상되는 것을 확인할 수 있다.
오늘은 적대적 학습을 Reranker와 Retriever에 적용한 AR2 학습 방법을 살펴보았다. 해당 방법은 Reranker와 Retriever를 Joint하게 학습하면서 두 모델에서 모두 성능 향상을 이루었다.