LLM은 매우 다양한 분야의 태스크에서 압도적으로 높은 성능을 보여주고 있다. 하지만 LLM의 지식의 범위를 벗어나게 되면 제대로 작동하지 않을 수 있는데, 이 때는 일반적으로 파인튜닝을 통해서 새로운 태스크의 패턴이나 지식을 학습시키게 된다.
LLM을 효율적으로 학습시키기 위한 PEFT(Parameter-Efficient Finetuning) 방법으로 LoRA가 가장 많이 사용되고 있다. 이러한 LoRA는 DoRA, AdaLoRA 등 다양한 형태로 응용되어 사용되고 있다.
이러한 LoRA는 학습에 사용되는 파라미터의 수를 매우 크게 줄이면서 학습에 드는 메모리 사용량 및 시간을 크게 줄였음에도 좋은 성능을 보이면서 많은 태스크에서 이용되고 있다. 하지만, 이러한 LoRA는 특정한 태스크에서 Overfitting을 겪으면서 성능이 크게 떨어질 수 있다. 오늘 소개할 논문인 Flexora는 이러한 Overfitting 문제를 해결하기 위해서 자동으로 파인튜닝에서 중요한 레이어들을 선택하고 해당 레이어를 업데이트하는 내용을 담고 있다. 이를 위해서 Layer를 선택하는 문제를 HPO task로 정의하고 UD method를 통해서 이를 해결하였다.
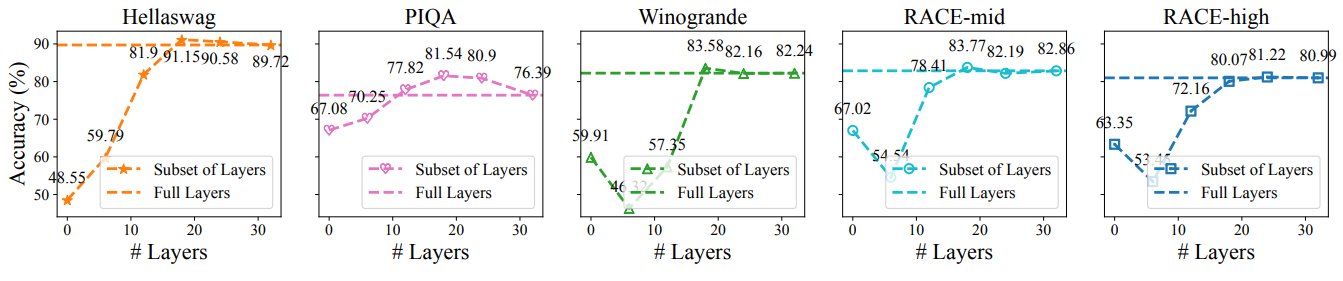
그림. Preliminary Study
위의 그림은 해당 논문에서 진행한 Preliminary Study로 Finetuning하는 레이어의 개수가 성능에 어떤 영향을 주는지를 나타낸 실험 결과이다. 일부 태스크에서는 일부 레이어만 학습시킨 결과가 모든 레이어를 학습시킨 결과보다 훨씬 좋은 성능을 기록한 태스크도 있었으며, 큰 차이는 아니지만 거의 모든 태스크에서 미세하게 나마 일부 레이어만 학습한 모델이 오히려 더 좋은 성능을 보이는 것을 볼 수 있다. 해당 논문은 이러한 필요성에 의해서 시작되었다.
HPO(Hyperparameter Optimization)은 말그대로 하이퍼파라미터를 적절하게 선택하는 것이라고 볼 수 있다. 일반적으로 Learning Rate, Epoch 등의 매개변수는 실무자가 경험을 통해서 설정하는 것이 일반적이다. HPO는 Validation 세트에서 최상의 성능을 제공하는 이러한 하이퍼파라미터를 찾는 것이라고 볼 수 있다. 일반적으로 여기에는 Grid Search, Random Search, Bayesian Optimization 등의 방법이 사용되고 있다. 해당 논문에서는 이를 위한 방법으로 Unfoled Differentiation 알고리즘을 적용했다.
지금부터 Flexora가 어떻게 구현되었는지 살펴보겠다.
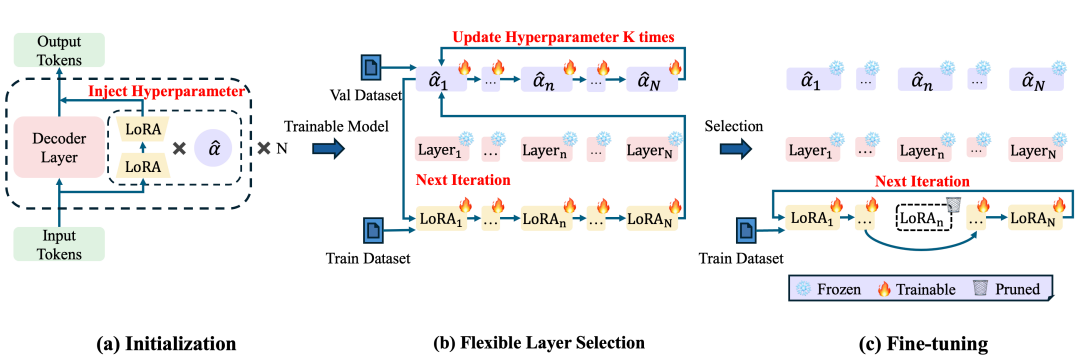
그림 2. Flexora의 구조
위의 그림은 Flexora의 구조 및 파인튜닝 과정을 나타낸다. Initialization 단계에서는 알파가 추가된 것 외에는 일반적인 LoRA와 같은 구조인데 알파={0,1}가 1이면 해당 레이어는 선택된 것으로, 0이면 선택되지 않은 것으로 볼 수 있다.
Promblem Formulation을 살펴보면 다음과 같은 수식이 나온다.
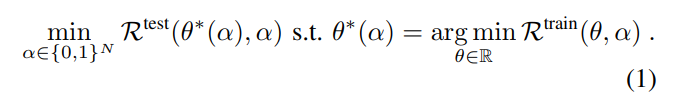
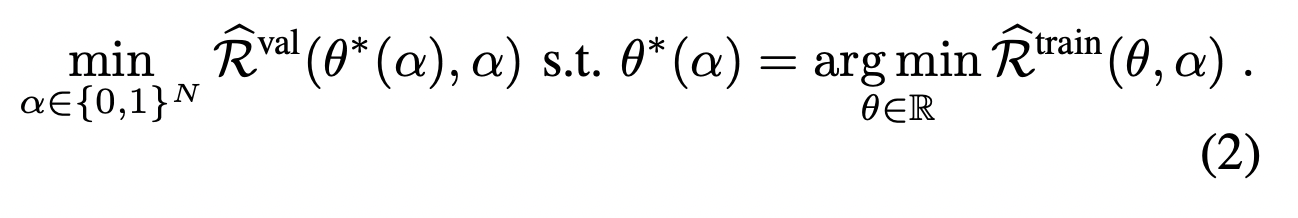
논문에서는 Flexora를 위한 모델 튜닝 과정을 inner problem과 outer problem으로 정의하였는데, inner problem은 모델이 LoRA의 Weight를 업데이트하면서 Train 데이터에서의 Loss를 Minimize하는 것이고, Outer Problem은 Validation Set에서의 Loss를 최소화하도록 하이퍼파라미터를 튜닝하는 것이다. 결국 이 두가지 문제를 최적화하기 위한 bilevel optimization 문제라고 볼 수 있다.
즉, R_train의 과정은 LoRA Adapter 가중치를 튜닝하여 학습셋에서의 Loss를 줄이는 최적화 태스크, R_test는 alpha를 최적화하여 Validation에서의 Loss를 최적화하는 작업이라는 것이라고 할 수 있다.
Layer Selection 과정에서는 Relaxation and Computation 과정을 거치게 되는데, 알파 값은 {1, 0}의 discrete한 값이 때문에 바로 Optimization을 적용하는 것이 힘들다. 그렇기 때문에 아래와 같이 continuous한 countpart로 relax 시켜준다.
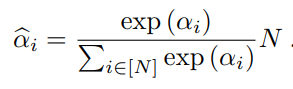
여기서 알파는 0으로 초기화되며, constant scale N은 초기화된 알파^가 모든 레이어를 선택하는 것과 같아지도록 적용된다.
![]()
레이어는 다음과 같이 계산되는데, a^가 0에 가까우면 해당 레이어에서 LoRA 연산은 별로 요구되지 않는다고 판단할 수 있다.
이제 파라미터(알파)를 정의했으니, 이를 어떻게 Optmization하는지 살펴보겠다. Optimization 과정은 수식 2에서 정의된 Optimization HPO를 푸는 작업이라고 할 수 있다.
HPO의 과정은 inner와 outer 두 과정으로 구성되는데, inner layer optimization 과정을 통해서 LoRA의 파라미터를 업데이트하여 R_train의 Loss를 최소화한다. 이와 비슷하게 R_val은 inner layer opimization의 결과를 기반으로 하여 alpha를 업데이트하는 outer layer opmitization 과정을 통해서 최소화된다.
그림 1a에서는 모든 alpha를 0으로 초기화하고, 모든 레이어에 LoRA 가중치를 세팅한다. 그리고 inner training 과정을 통해서 모든 레이어의 파라미터들을 업데이트 시킨다. 이 때, 그래프들은 alpha_hat 변수에 의해서 미분이 가능한(differentiable) 상태가 된다. 그 후, inner training에서 학습된 파라미터를 이용해서 K번의 Outer training 과정을 거치게 된다. 아래의 알고리즘이 K번의 Outer training 과정을 나타낸다.

Validation 데이터에서 랜덤한 샘플의 배치를 선택하고 Optimization을 한다. 이 때, R_train의 LoRA 파라미터와 R_val의 alpha 파라미터는 서로 독립적인 것으로 간주한다.
최적화된 alpha 파라미터를 기반으로, 가장 좋은 성능을 보여줬던 a_i가 0보다 큰 레이어를 선택한다. 만약 학습에 사용할 자원이 제한된다면, 유동적으로 업데이트할 레이어의 개수를 설정할 수 있는데, 가장 큰 a_i 값을 가지는 x개의 레이어를 선택해서 학습시킬 수 있다.
다만 파인튜닝 과정에서, 선택되지 않은 레이어의 가중치도 학습 과정에서는 모두 유동적으로 사용되기 때문에 선택되지 않은 레이어를 물리적으로 지우는 것은 불가능하고, 선택되지 않는 레이어는 freeze하여 파인튜닝을 진행한다.
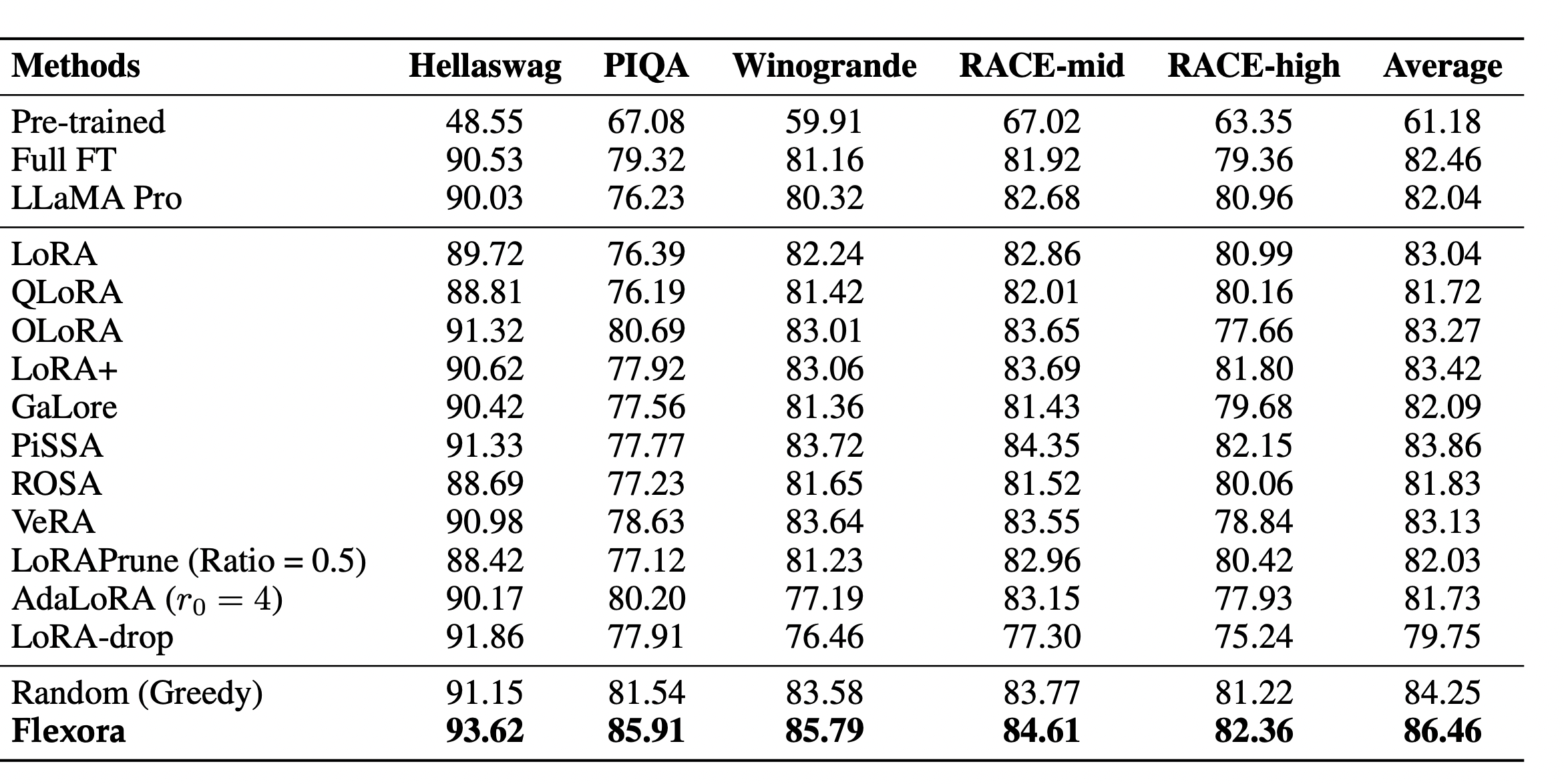
위의 표는 Flexora를 실험한 성능을 나타낸다. Random으로 Greedy하게 업데이트할 레이어를 선택했을 때에도 기존 LoRA에 비해서 더 향상된 성능을 보이는 것을 확인할 수 있다. (해당 실험 결과는 Random하게 K개의 업데이트할 레이어를 선택하도록 하여 그 중 가장 좋은 결과를 선택한 것이다) 이를 통해서 모든 레이어를 업데이트하는 것 보다는 특정한 레이어만을 업데이트하는 것이 LoRA를 이용한 파인튜닝의 성능 향상에 도움이 되는 것을 확인할 수 있다. 다만, Flexora를 이용한 Opimization 과정을 통해서 alpha 변수의 학습을 통해 유동적으로 학습할 레이어를 선택하도록 했을 때, 모든 베이스라인에서 가장 좋은 성능을 보인 것을 확인할 수 있다.
이번 글에서는 Flexora라는 논문을 살펴보았다. 해당 논문은 LoRA를 파인튜닝할 때, 특정 레이어들이 너무 과하게 업데이트되어 과적합될 수 있는 문제를 지적하며, Flexora를 제안했다.
Flexora는 기존의 LoRA 파라미터를 업데이트하는 inner opimization 과정과 레이어를 선택하는 alpha 파라미터를 업데이트하여 파인튜닝할 레이어를 유동적으로 선택하는 outer optmization의 두가지 과정으로 학습을 구성하였다. 파인튜닝 과정 중에 중요도가 높은 레이어를 선별하여 업데이트함으로써 기존 LoRA가 가지는 문제들을 개선하고 성능을 올릴 수 있었다.