
본 글은 얼마전 데이콘에서 열렸던 “재정정보 AI 검색 알고리즘 경진대회”를 진행하면서 적용해보았던 방법들을 간단하게 정리한 글이다.
해당 대회는 데이콘에 잠깐 접속을 하였다가 RAG와 관련된 대회를 진행하는 것을 보고 좋은 경험이 될 것 같아서 진행하게 되었다. 해당 대회에서는 재정 보고서, 예산 설명 자료, 기획재정부 보도 자료 등을 바탕으로 질의응답을 수행한다. 각 질문마다 어떤 PDF 파일에서 정답을 추출해야 하는지 태깅되어 있는데, 이 부분에서는 RAG와는 조금 접근 방법이 다를 수 있다. 하지만, 일부 파일들은 파일 하나당 100 페이지를 넘는 경우도 있기 때문에 답변에 필요한 정보를 Retrieval하는 과정이 아예 생략될 수 있는 태스크는 아니였다.
우선 대회를 시작할 때는 다음과 같은 방향으로 진행하였다.
- PDF의 텍스트를 적절하게 전처리 및 Chuncking
- 테이블과 같은 구조화된 데이터에 대한 답변 강화
- 적절한 품질의 답변 결과 생성을 위한 다양한 파인튜닝 적용
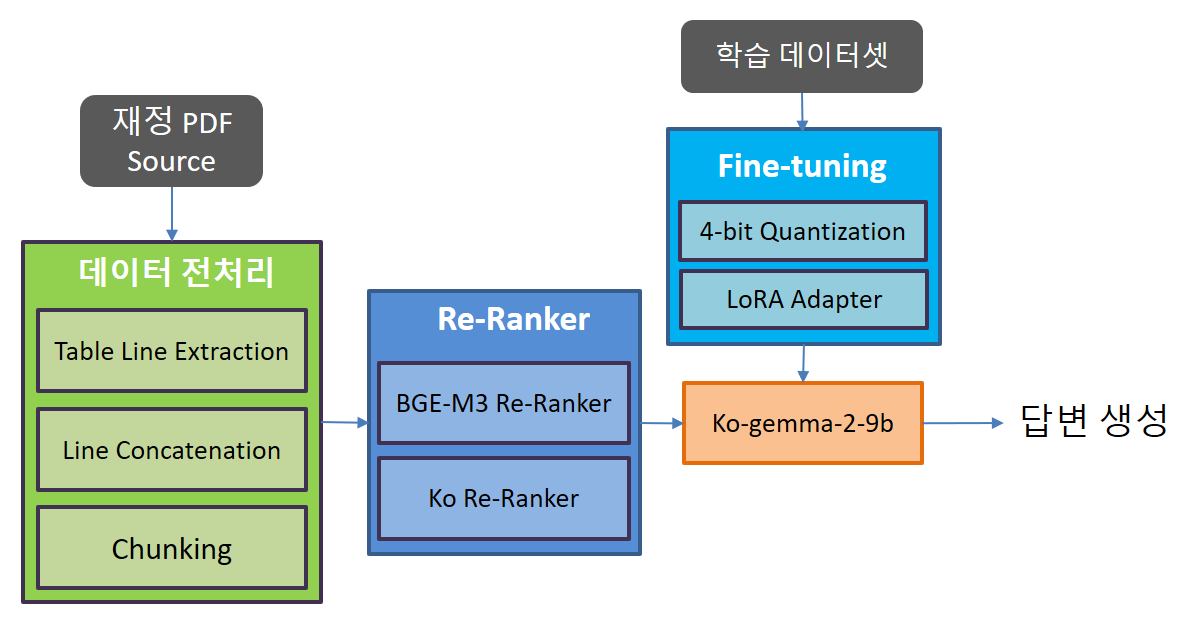
그림 1. 전체적인 시스템의 구성도
위의 그림은 대회를 진행하면서 적용한 방법들의 전체적인 파이프라인이다. 학습에 적용했던 컴퓨터에는 RTX-3090 2대의 GPU가 설치되어 있었기 때문에 Full-Finetuning은 적용해볼 수가 없었고, 적은 VRAM에서 원할하게 학습을 하기 위해서 4-bit로 모델을 양자화하고 LoRA를 학습시키는 QLoRA를 이용하였다.
앞서 언급했듯이 학습 및 평가 데이터셋의 각 질문에는 어떤 PDF 데이터를 이용하여 답변을 생성해야하는지가 태깅이 되어 있었다. 한 파일당 백 페이지가 넘는 파일도 존재하긴 했지만, 따로 BM-25나 벡터 DB를 이용하여 데이터를 검색해야 할 정도로 파일당 많은 수의 Chunk 데이터가 생성되지는 않았기 떄문에 데이터를 검색하는 부분은 생략할 수 있었다.
대신 LLM에서생성된 모든 Chunk를 입력하고 정답을 생성하기에는 모델의 실행시간이 너무 오래 걸릴뿐만 아니라, 생성된 답변들 중에 어떤 답변을 최종적으로 선택할지도 결정하는 것이 거의 불가능하다. 이에 Bi-Encoder 보다 조금 더 좋은 성능을 낼 수 있는 Cross-Encoder 기반의 리랭킹 모델을 적용하여 답변에 필요한 Chunk들을 선별하였다.

PDF의 전처리에는 텍스트를 추출하는 가장 기본적인 툴인 PyMuPDF를 이용하였다. PDF 파일에 다수의 표 데이터들이 포함되어 있었고, 이러한 표나 차트를 기반으로 답변해야 하는 질문들이 다수 존재했기 때문에 표를 구조적인 형태를 가지고 있는 원본 형태로 추출하고 싶었다. 그래서 Camelot과 같은 표에 특화된 PDF 추출기도 이용을 해보았는데, Camelot을 사용했을 때는 표가 올바르게 잘 추출되긴 했지만 아예 추출하지 못하는 표의 숫자가 더 많다는 문제점이 있었다.
표 형태 복원
그래서 표는 그냥 PyMuPDF에서 출력되는 방식으로 두고, 이후 후처리를 통해서 표의 형태로 복원하는 방법을 적용해보았다.
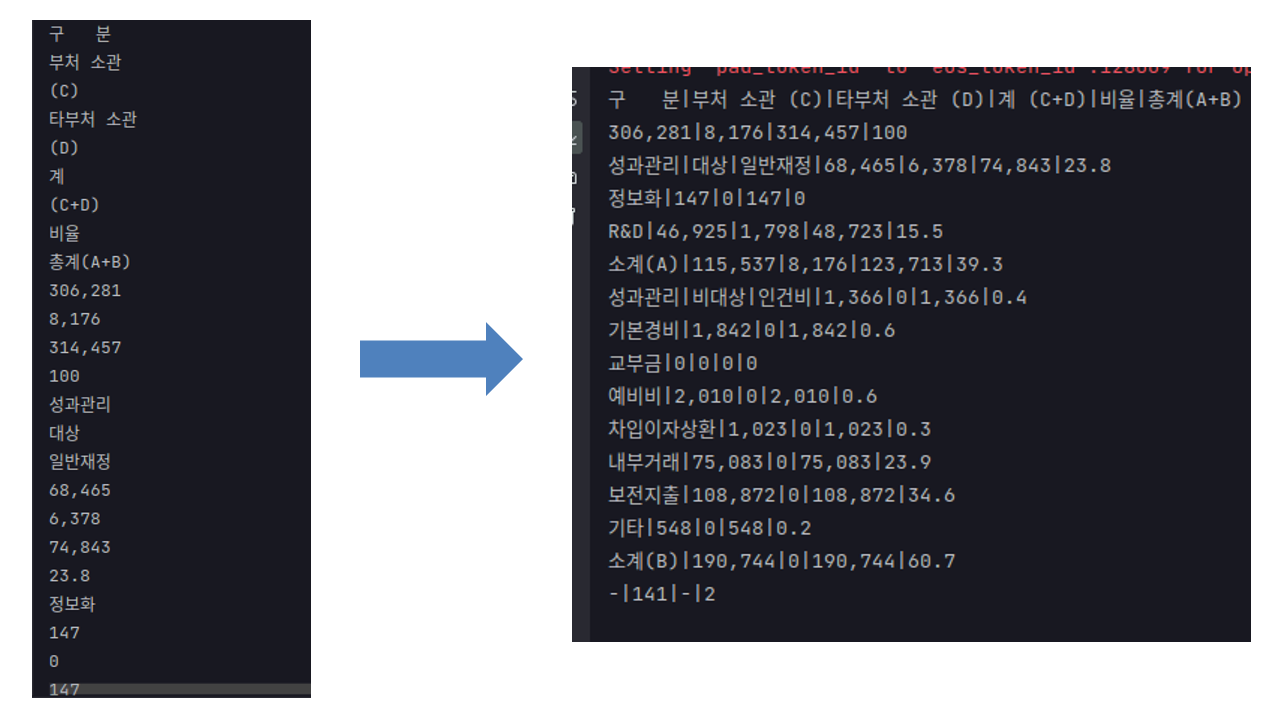
그림 3. 블로썸을 통해 적용한 표 형태 복원 방법
표 형태를 복원하는 방법으로 LLM들을 이용해서 표 데이터를 무작위로 생성하도록 하였다. 위키피디아와 같이 공개된 표 데이터를 사용하는 것이 아니라 표 데이터를 굳이 LLM을 통해서 생성하여 사용한 이유는 해당 대회에서는 어떠한 외부 데이터도 사용하는 것이 금지되어 있었기 때문이다. 표의 데이터를 복원하는 방법은 간단하게 적용했는데, 프롬프트에는 그림 3의 왼쪽과 같이 표의 구조적인 정보가 사라진 텍스트를 입력하고 출력에는 그림 3의 오른쪽과 같이 구조적인 형태가 복원되도록 학습하였다. 이러한 방법으로 표의 구조적인 정보는 잘 복원이 되었으나, 몇 가지 문제점이 있었다. 첫 번째는 왼쪽과 같은 형태의 데이터가 표만 존재하는 것은 아니였다. 차트나 리스트와 같은 데이터도 저러한 방식으로 추출되기 때문에 복원이 불필요한 데이터까지 표의 형태로 어거지로 복원되는 경우가 많았다. 두 번째는 저러한 구조화된 형태의 표 데이터에 학습되지 않았기 때문에 성능 향상에는 크게 영향을 미치지 않았다. 마찬가지로 외부 데이터는 일체 사용이 금지되기 때문에 저러한 구조적인 데이터의 정보를 잘 포착하도록 추가적으로 학습하는 것도 어려움이 있었다.
이에 해당 대회에서는 그림 3의 왼쪽 형태와 같이 PDF 추출기에서 출력된 형태를 따로 처리하지 않고 그대로 입력으로 사용하였다.
리랭킹 모델
외부 데이터를 사용할 수 없었기 때문에, 마찬가지로 리랭킹 모델도 따로 학습하는 것이 아니라 공개된 모델에서 찾아야 했다. 당시 공개된 리랭킹 모델 중 성능이 가장 좋다고 알려져 있던 BGE-M3 Reranker 모델을 이용하였다. ko-reranker는 BGE-reranker-large 모델을 한국어 데이터에 파인튜닝한 모델인데, 가장 최근에 공개되었던 리랭커 모델인 bge-reranker-v2-m3 모델과 예측의 분포가 조금씩 다르게 나왔으며 잘 예측하는 부분이 조금씩 다른 것 같아서 두 모델의 예측 값을 결합하여 사용하였다.
처음에는 리랭킹 모델에서 확률 값이 가장 높은 Chunk를 5개 추출하고, 조금 더 무거운 리랭커 모델인 gemma 기반의 m3-reranker 모델을 이용하여 최종적으로 답변을 생성해보는 방향으로 진행을 하였다. 이때, Chunk와 해당 Chunk에서 생성된 답변을 이용하여 리랭킹 하는 방법, Chunk만을 이용해서 리랭킹하는 방법, 생성된 답변만을 이용하여 리랭킹하는 방법 등을 적용해보았는데 그냥 ko-reranker와 bge-reranker-v2-m3를 결합하여 생성한 결과에서 Top-1을 고르고 바로 답변을 생성하여 출력하는 것의 결과가 더 좋았다.
우선, gemma-reranker의 성능 자체가 해당 태스크에서는 bge-m3 reranker보다 그리 좋지 못하였으며, 답변을 같이 입력하여 리랭킹하는 방식은 그러한 포멧의 더 많은 학습 데이터를 적용해야 어느정도 효과가 있을 것 같았다.
모델 입력 구성
모델의 학습을 위한 입력에는 토큰 사이즈를 256으로 제한하여 Chunk를 생성하였고, 정답을 추론하는 단계에서는 토큰 사이즈를 512로 제한하여 Chunk를 생성하였다. 학습과 추론에서 길이를 달리 한 이유는 사용할 수 있는 학습 데이터의 개수가 많지 않았기 때문에 학습에서는 리랭커 모델에서 상위 3개의 단락을 추출하고, 해당 단락들의 순서를 다르게 하여 Permutation하는 방법으로 학습 데이터 수를 늘리고, 프롬프트에서 정답에 대한 단서가 어느 위치에 있더라도 있더라도 강건하게 모델이 학습되도록 하기 위함이였다.
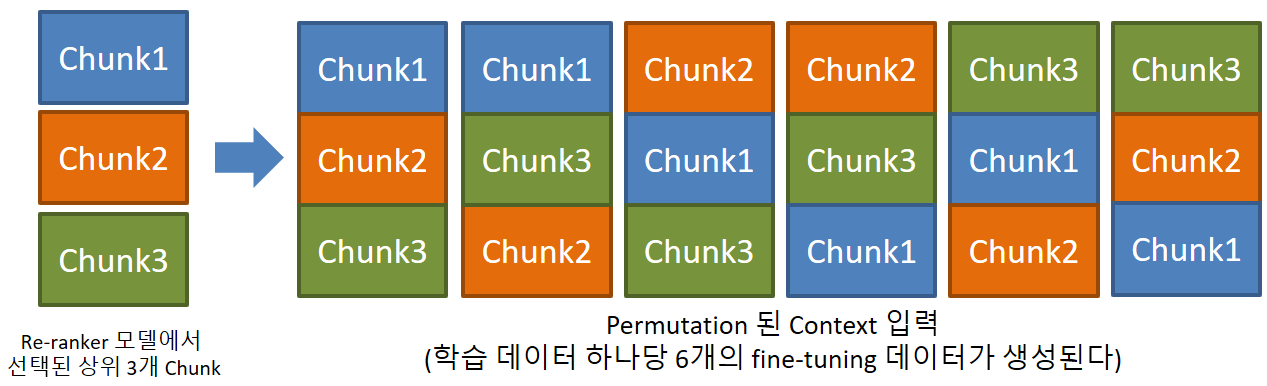
그림 4. 3개의 청크를 이용한 학습 데이터 구성 방법
파운데이션 모델 선택
대회를 시작했을 때 고려했던 모델들은 다음과 같다.
- ko-gemma-9b-it
- LLama-3.1-8B
- Blossom-8B
- Qwen-7B
이 중에서 ko-gemma-9b-it와 LLama-3.1-8B가 가장 좋은 성능을 보였는데, 그 중 성능이 조금 더 좋고 생성되는 답변의 어순이나 문체가 조금 더 자연스러운 ko-gemma를 선택했었다.
데이터 증강
표 데이터에서 성능을 늘리고 싶었지만, 외부 데이터를 사용할 수 없었기 때문에 표에 대한 학습 데이터를 생성하는 방법을 적용하였다. 우선, 표 구조 복원을 적용해보았을 때와 마찬가지로 LLM에서 임의로 표 데이터를 생성하게 하였는데 본 대회에서 질의응답해야하는 ‘재정’ 도메인과 관련된 테이블들을 생성하도록 하기 위해서 학습 데이터셋에서 추출한 문장들을 컨텍스트로 입력하고 해당 컨텍스트와 관련된 테이블들을 생성하도록 설정하였다.
학습 데이터 및 정답 데이터를 생성하는 방법은 이전에 소개했던 GraPPa의 방법을 기반으로 적용하였는데, Context-free 문법 기반의 규칙들을 생성하고 해당 규칙을 기반으로 질문 데이터를 생성한다. 그리고 해당 규칙에 맞는 셀들을 추출하여 정답 데이터로 설정한다.

그림 5. Context-free 문법을 통해서 질문 데이터가 생성되는 예시

그림 6. LLM을 통해서 임의로 생성한 표 데이터 예시
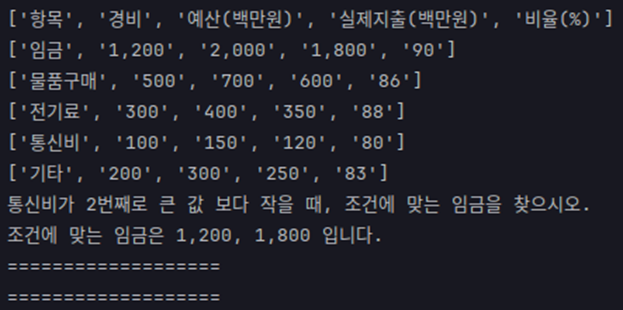
그림 7. 합성된 데이터 예시
그림 5는 Context-free 문법을 통해서 질문 데이터가 생성되는 예시이다. 정답 셀은 만들어진 규칙에 따라서 해당하는 셀을 추출하기만 하면 된다. 이번 대회에서는 한국어 어순 등을 맞춰주기 위해서 논문에서 적용되었던 방식을 조금씩 변형하여 적용하였다.
일부분이 생략되긴 했지만, 여기까지가 대회를 진행하면서 적용해보았던 내용들을 간략하게 정리한 것들이다.
진행하면서 성능에 가장 영향을 많이 주었던 요소들을 정리해보면 다음과 같았다.
- Chunk 랭킹
- 파인튜닝
- 데이터 증강
- Chunking 형식
- 프롬프트
최종 성능에 가장 많은 영향을 주었던 것은 당연하게도 리랭킹 모델의 적용이었다. 그리고 두 번째로 영향을 많이 주었던 요소는 파인튜닝 방법인데 파인튜닝에 적용하는 여러 파라미터 조정 및 입력 형식 등을 조정하여 성능을 올릴 수 있었다. 세 번째로는 표 데이터에 대한 학습 데이터 증강이었는데, 평가 데이터셋을 자세히 보지는 않았지만 표에서 정답을 추출해야 하는 유형이 좀 더 많은 데이터에서는 조금 더 많은 영향을 줄 수도 있을 것 같다. 다음으로 Chunking 방법은 시멘틱 청킹, 마크다운 청킹 등 여러 유용한 청킹 방법들이 공개되어 있는데 여러 가지 청킹 방법을 비교해보았을 때 큰 성능 차이를 발견하지 못하여 가장 기본적인 청킹 방법을 적용하였다. 마지막으로 프롬프트의 경우, 프롬프트를 바꿔봄에 따라 유의미한 성능 차이는 존재하였지만 결국 파인튜닝을 하게 되었을 때는 프롬프트 간의 성능 차이가 거의 없었다.