공개되고 있는 여러 모델의 사전학습에는 엄청나게 많은 데이터들이 이용되고 있다. 자연어 기반의 사전학습 데이터는 다양한 매체에서 다양한 형태나 정보의 데이터를 수집하는 것이 가능하지만, 표 데이터를 이용하는 사전학습 데이터는 종류가 다양하지도 않으며 엄청나게 많이 구하는데에 한계가 존재한다. 또한 사전학습 과정에서 유의미한 의미를 도출하려면 표 데이터뿐만 아니라 해당 표 데이터와 함께 얻을 수 있는 다른 추가 정보들이 필요하지만 이러한 조건을 모두 갖추는 데이터를 구하는 것은 더더욱 쉽지 않다.
하지만 표 데이터는 자연어 텍스트와 다르게 (반)구조화된 데이터이므로 표 데이터에 있는 정보를 조합해서 새로운 텍스트나 정보를 생성하는 것이 비교적 용이하다. 이에 Table QA 연구에서는 이러한 특성을 이용해서 인공적으로 합성한 데이터를 사전학습에 이용하고자 하는 연구들이 많이 공개되었다. 이번 글에서는 합성 데이터를 사전학습에 이용하여 TaLM의 성능을 향상시키고자 한 연구들을 몇 가지 소개하고자 한다.
이번 글에서는 다음 논문들을 다뤄보려고 한다.
- Understanding tables with intermediate pre-training(2020)
- GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing(2021)
- SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing(2021)
- Logic-Consistency Text Generation from Semantic Parses(2021)
- STAR: SQL Guided Pre-Training for Context-dependent Text-to-SQL Parsing(2022)
본 글에서는 논문 하나하나를 자세히 다루기보다는 데이터 합성에 관한 부분만 다루면서 데이터 합성 방법이 연구마다 어떻게 다른지 비교해보았다.
합성되는 데이터는 다양한 형태가 될 수 있는데, 테이블 T가 있다고 했을 때 다음과 같은 형태가 될 수 있다.

Intermedidate Pretraining에서는 표의 내용과 관련된 Statement를 인공적으로 생성하도록 하였다. 위의 그림에서 Counterfactual은 위키피디아 문서에서 테이블의 엔티티를 언급하는 문장을 찾아내고 해당 문장의 엔티티를 임의로 변경해서 표의 내용에 반하는 문장을 생성한 것을 나타내며, Synthetic은 Statement 생성을 위한 데이터를 선택하고 해당 데이터를 기반으로 인공적으로 데이터를 만들어낸 예시이다.

Statement의 생성에는 Context-free Grammar를 적용하였다. 다음 문법을 적용하면 특정 조건(Compare)을 만족하는 Value를 가진 Statement를 생성하게 되며 해당 데이터는 인공적으로 생성된 데이터이므로 임의로 값을 변경하고 해당 값을 변경했을 때 테이블 데이터에 반하는지 아닌지를 알 수 있다. 이를 통해서 Positive, Negatvive 데이터를 생성하고 사전학습 과정에서 입력된 Synthetic 데이터가 Positive한지 Negative한지를 예측하는 방식으로 사전학습을 하였다.

GraPPa도 마찬가지로 Context-free Grammar를 통해서 데이터를 생성하였다. GraPPa에서는 합성 데이터 생성을 위한 Synchronous Context-free Grammar 규칙을 생성하기 위해서 Spider 데이터셋을 사용하였다. Spider 데이터셋의 (x: 자연어 Utterance, y: SQL Utterance)를 이용하였는데, 우선 SQL의 자주 쓰이는 템플릿을 정의하기 위해서 Spider 데이터셋 내에서 가장 자주 쓰이는 템플릿 90개를 추출하였다. 그리고 해당 템플릿에서 사용된 자연어 질의를 랜덤하게 4개씩 추출하였다. 그리고 추출된 자연어 질의의 엔티티/구문을 Non-Terminal로 치환해서 자연어 템플릿을 생성하였다. 이렇게 만든 약 500개의 데이터를 통해서 수작업(Manual Alignment)을 통해서 Production Rule을 맞추는 작업을 진행하였다. 이렇게 생성된 규칙을 통해서 새로운 테이블이나 데이터베이스를 이용하면 합성 자연어와 SQL 질의를 생성할 수 있다. 이를 통해 약 47만 개의 question-SQL 쌍을 생성하여 사전학습에 활용하였다.
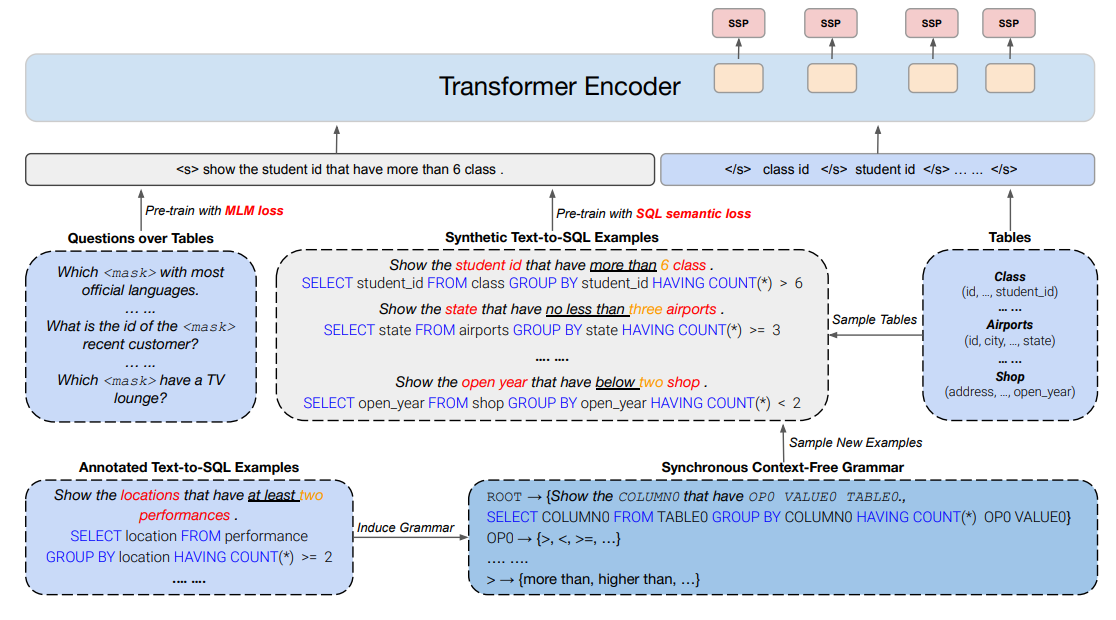
GraPPa에서는 기존의 MLM Objective와 함께 SSP Objective를 적용했다. 해당 태스크는 자연어 질의와 테이블 헤더가 입력되었을 때, SQL 쿼리에 Column이 나타나는지 안나타나는지 그리고 나타난다면 어떤 Operation이 적용되는지를 예측하는 태스크이다. 예를 들어 위의 그림에서 Location은 “SELECT”, “GROUP BY”, “HAVING”의 Operation이 적용되는 것을 예측해야 한다.
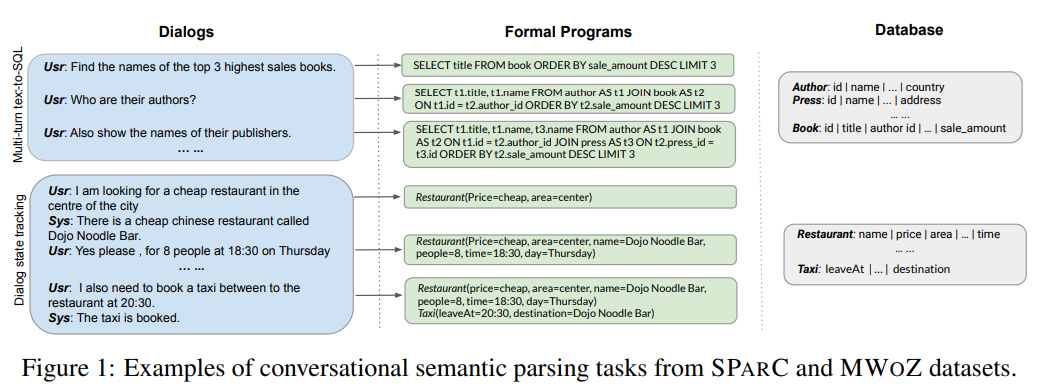
Score는 SPARC나 MWoZ와 같은 Conversational Semantic Parsing 태스크를 위한 합성 데이터를 이용한 사전학습 방법을 제안하고 있다. CSP는 말 그대로 대화 문장들을 입력받고 해당 대화 문장들을 Formal Program으로 변환하는 태스크이다. 여기서도 MLM을 베이스 Objective로 설정하고, 태스크에 특화된 보조 사전학습 Objective를 추가하는 방법을 적용했다.

첫번째 Obejctive인 CCS(Column Contextual Semantics)는 GraPPa에서 적용된 SSP와 유사한 Objective인데 Column Representation을 입력받고 해당 Column에서 등장할 수 있는 Operation들을 예측하는 태스크이다. GraPPa에서는 약 250가지의 Opeation을 예측하도록 하였는데, 여기서는 등장할 수 있는 148가지의 Operation 중에 입력된 Column에서 사용하는 Operation을 예측하도록 하였다.
두번째 Objective는 TCS(Turn Contextual Switch)로 대화의 흐름 정보 및 그것들이 어떻게 정형화된 형태로 변환되는지를 Formal한 Represenatation으로 나타내기 위한 태스크이다. 즉, TCS는 Context Flow가 정형화된 형태로 변환되는 과정을 잘 이해하기 위한 태스크라고 볼 수 있다. SQL의 Context-free 문법을 기반으로 대화의 Turn이 변화하는 연산(Turn Difference Openration) 26가지를 정의하고 이를 예측하도록 하였다. 예를 들어 “Show the all ages intead ~”와 같은 질문ㅇ 있다면 “SELECT MAX(age) … => SELECTT age …)가 될 수 있다. 각 대화 턴의 <s>토큰을 입력받고 해당 턴의 Turn Difference Openration을 예측한다.
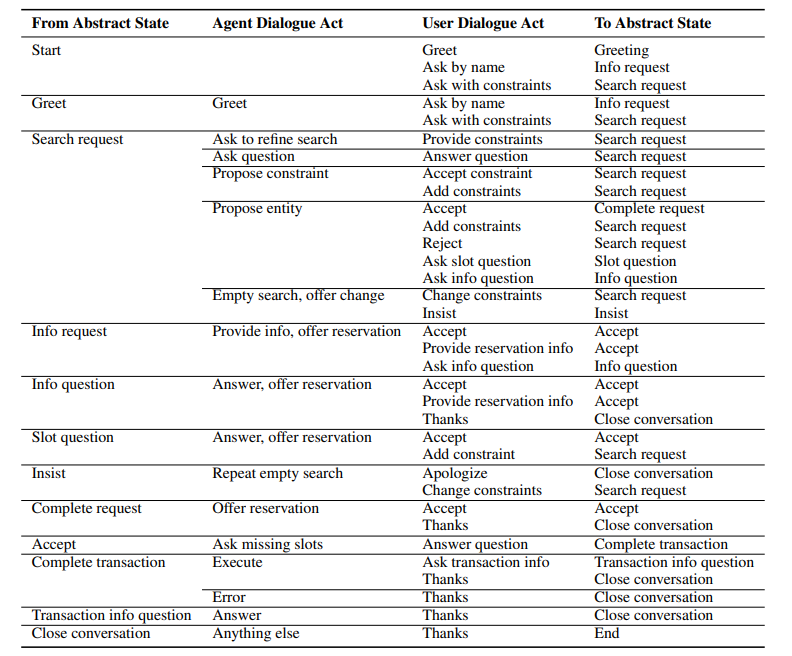
그림. Abstract Dialogue Model

그림. 데이터 합성 템플릿
Score에서도 Pretraining 데이터를 위해서 데이터 합성을 이용했는데, “Zero-Shot Transfer Learning with Synthesized Data for Multi-Domain Dialogue State Tracking”의 방법을 응용하여 적용하였다. 해당 논문에서는 데이터 합성을 위한 템플릿들을 생성하고 생성된 템플릿을 기반으로 데이터를 합성하였다. 해당 논문에서는 데이터를 합성하기에 앞서서 여러 대화의 상황, 화자의 행동, 대회의 내용에 필요한 Slot 등을 먼저 정의를 하였는데 이를 Abstact Dialogue Model로 정의하였다. 위의 그림의 템플릿을 통해 대화를 생성하면 다음과 같다.
State: SEARCHREQUEST resturant(…)
Agent: “How about Curry Garden? It is an Indian Restaurant in the south of town.”
User: Is it Expensive?
State: SLOTQUESTION resturant(price=”?”)
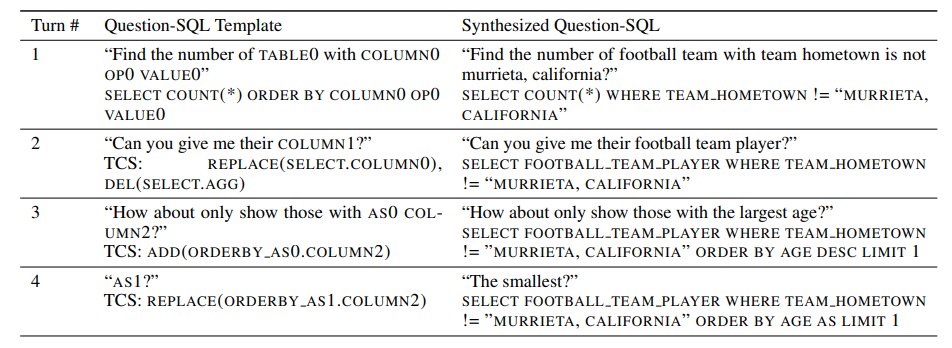
SCoRE에서는 해당 논문의 방법을 확장해서 Table 데이터에 적용하였다. WikiTables, WikiSQL, Spider에서 약 40만 개의 테이블을 추출했다. 그리고 SPARC 데이터의 Dev 데이터셋에서 추출한 약 500개의 데이터를 통해서 데이터 합성 규칙 및 문법을 생성하고 이를 통해서 최종적으로 47.5만개의 데이터를 합성하였다.
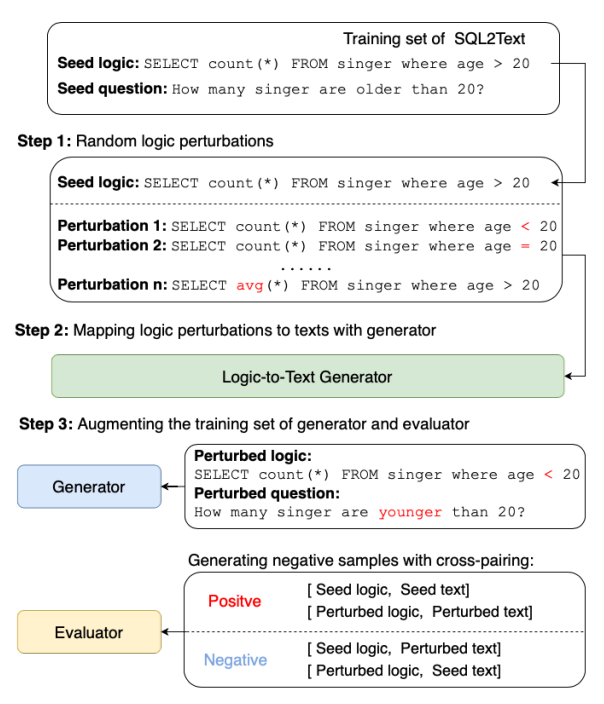
“Logic-Consistency Text Generation from Semantic Parses”에서는 Iterative Training 방식을 이용하는 SNOWBALL framework를 제안하였다. SNOWBALL 프레임워크에는 Generator와 Evaluator의 2가지 모델이 사용되는데, 이 두가지 모델을 이용해서 데이터를 학습하고 평가하는 과정에서 데이터를 Augmentation하여 학습 데이터를 증가시키는 방법을 적용했다. 위의 그림은 모델의 동작 과정 및 데이터 예시를 나타낸다. Generator는 Logical Form(SQL 등)을 입력받으면 이를 표한하는 Natural Sentence로 변환하여 생성을 하게 된다. Evaluator는 Logical Form과 자연어 Sentence가 입력되면 둘의 Logical Consistency를 평가하게 된다. 예를 들어 “Select Max(age)”와 “가장 작은 나이를 알려줘”가 입력되면 둘은 다른 논리적 의미를 가지기 때문에 Negative한 데이터가 된다.
데이터를 Augmentation 하기 위해서 해당 논문에서는 Logical Perturbation을 적용했는데, Positive한 Logical Form-NL 쌍의 데이터를 입력받아서, Logical Form의 Operation들을 임의로 변경하여 일부로 Negtaive한 데이터쌍을 만드는 작업이다. 이를 통해서 Evaluator의 Negative 데이터를 생성할 수 있으며, Perturbation이 적용된 데이터를 Generator에 입력하면 새로운 데이터셋을 생성할 수 있다.
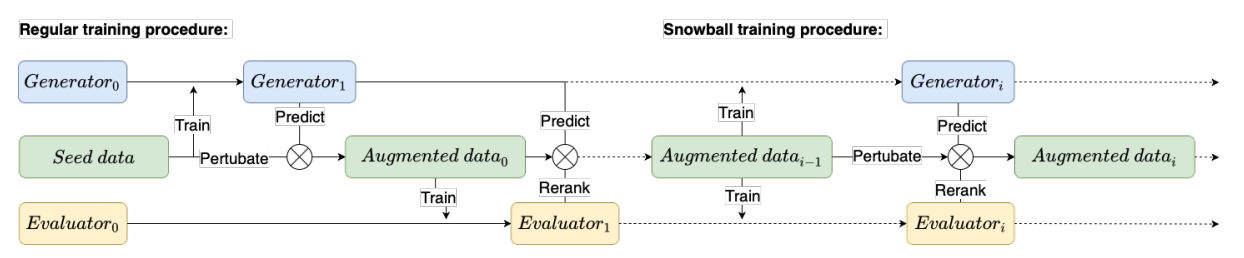
Generator와 Evaluator는 서로 상호작용을 하면서 반복해서 학습을 하게 되는 Iterative Training이 적용되었다.
- Human Annotated 된 데이터셋으로 Generator와 Evaluator를 학습한다.
- Logic Pertubation을 적용해서 새로운 Logical Form들을 생성한다.
- Generator를 이용해서 새로운 Logical Form들을 생성한다.
- Evaluator는 Beam Search 결과들을 Re-Ranking한다.
- 선별된 증강 데이터셋을 추가하여 다시 학습 과정을 반복한다.
다음과 같은 방법으로 데이터의 성능폭이 무의미해질 때 까지 반복해서 학습을 진행한다.
마지막으로 살펴볼 논문운 “STAR: SQL Guided Pre-Training for Context-dependent Text-to-SQL Parsing”이다. 해당 논문에서는 SCoRE에서 적용된 방법을 채용하여 한계점을 극복하기 위해 일부 방법을 변경하는 하여 적용하였다.
해당 논문에서 언급한 SCoRE의 한계점은 다음과 같다.
- template filling 기반의 데이터 생성 방법을 사용하기 때문에 생성된 Utterance는 Rigid한 형태를 가지게 된다.
- 여기서 Rigid하다는 것은 생성된 문장의 형태가 고정되어 있으며 부자연스럽다고 해석할 수 있을 것 같다.
- SPARC를 데이터 합성을 위한 유일한 자원으로 이용하여 Contextual Diversity가 부족하다.
이러한 단점을 극복한 데이터 생성 방식을 적용하기 위해서 해당 논문에서는 SNOWBALL의 방법과 같이 BART와 같은 생성형 모델을 데이터 생성에 적용하는 데이터 생성 방법을 제안하였다. 또한 SPARC와 함께 COSQL 데이터를 데이터 합성에 함께 적용하였다.
이번 글에서는 테이블 데이터와 같은 구조화된 데이터에 관한 데이터 합성을 다루는 논문들을 살펴보았다. 대부분의 논문에서는 기존에 사람이 태깅한 데이터셋들을 이용해서 자주 등장하는 데이터 형태를 템플릿으로 저장해놓고 Context-free Grammar 규칙을 적용해서 데이터를 자동으로 합성하는 방법을 채용하였으며, 일부 논문에서는 생성형 모델을 이용해서 데이터 생성에도 적용을 하였다.