오늘 살펴볼 논문은 “DIFFUSION MODELS ARE REAL-TIME GAME ENGINES”이다.
해당 논문은 완전히 신경망 기반 모델을 기반으로 동작하는 실시간(Real-time) 게임엔진에 관한 논문이다. 해당 논문을 통해서 1장의 TPU로 20 FPS의 둠 게임을 구동할 수 있었다고 한다.

컴퓨터 게임들은 손수 제작된 소프트웨어 시스템으로 다음과 같은 게임 루프로 구성되어 있다:
- 유저들의 입력을 받는다
- 게임의 상태(State)를 업데이트 한다
- 그것을 화면에 픽셀 형태로 뿌린다
이러한 게임 루프는 높은 Frame Rate로 구동되어 플레이어가 상호작용 가능한 가상의 세계에 있는 것과 같은 경험을 제공한다.
최근에는 생성형 모델이 다양한 분야에서 많은 발전을 이루면서, 이미지 생성, 텍스트 생성, 비디오 생성 심지어는 텍스트와 이미지를 동시에 처리하는 멀티모달 등 다양한 분야에서 다양한 모델들이 적용되고 있다. 이러한 흐름에 따라서 Diffusion 모델은 미디어 생성에서 거의 약방의 감초와 같은 역할이 되어가고 있다.
신경망 기반 게임 제작을 위한 이전 연구들이 존재해왔지만, 이러한 연구들은 제한된 환경에서 제한된 프레임에 시뮬레이션 형태로 진행되어 왔다. 해당 논문은 실제와 비슷한 환경에서 실시간으로 시뮬레이션이 가능한 복잡하고 고퀄리티의 게임을 신경망으로 구동시키고자 하였다.
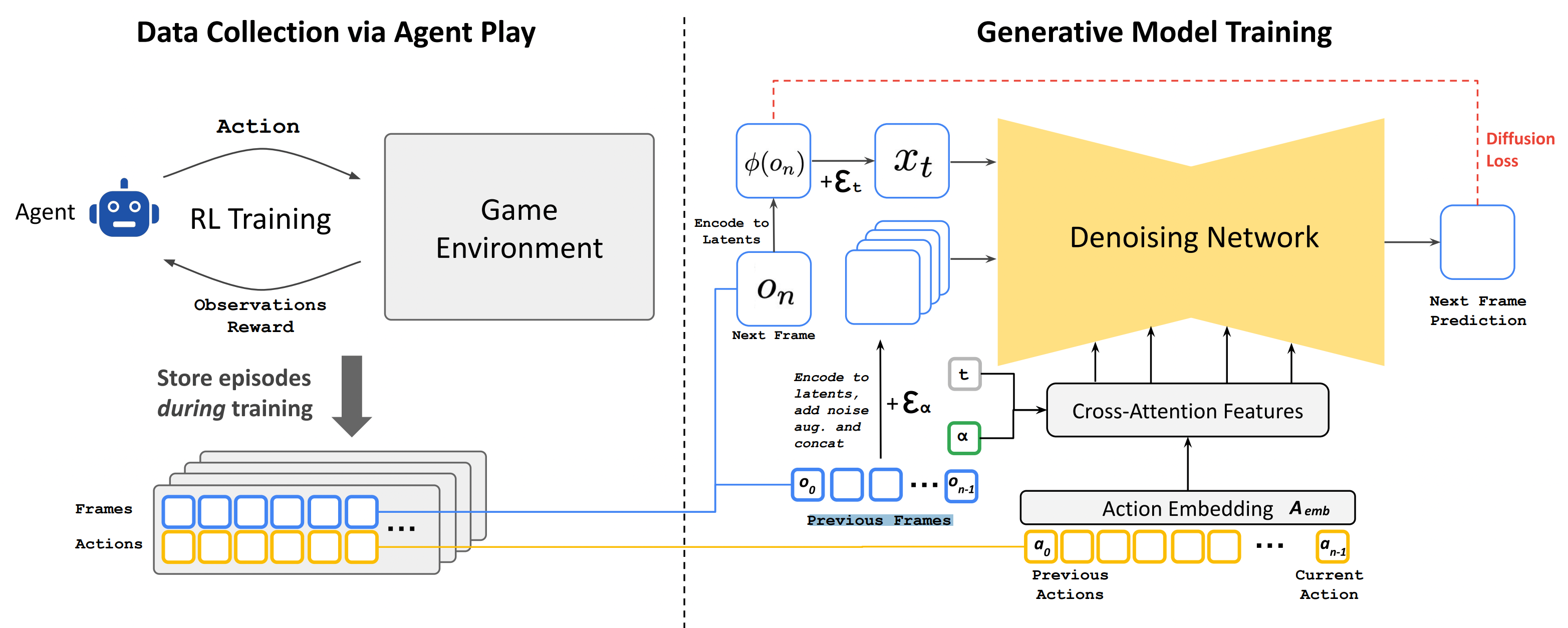
그림 1. GemeNGen 시스템의 전체적인 구조
위의 그림은 신경망 기반 게임 엔진의 학습 과정을 전체적으로 나타낸 그림이다.
우선, 상호작용 가능한 World를 시뮬레이션하는 과정을 먼저 살펴보자. Interactive Environment E는 latent states S, Partial Projection Space O, Partial Projection function V: S=>O, Action들의 모음 A, 그리고 transition 확률 p(a,s’)로 이루어져있다. 둠을 예시로 들면 S는 프로그램의 동적 메모리 콘텐츠, O는 스크린에 렌더링되는 픽셀, A는 키보드 입력이나 마우스 입력, 그리고 p는 유저의 입력에 따른 프로그램의 로직으로 볼 수 있다. Interactive Environment E는 simulation 분포 함수인 q(o_n|o<n, a<=n)이다. 학습을 위해 Minimize 해야하는 Objectives는 아래와 같이 정의할 수 있는데, 결국 Agent에서 관찰된 Observations와 모델이 시뮬레이션한 분포의 차이를 최소화하도록 학습하는 것이다.
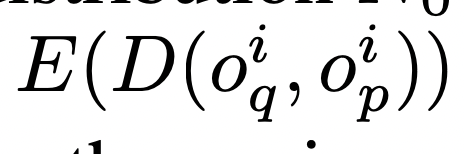
학습에는 에이전트 환경과 상호작용해서 얻은 conditioning action들을 teacher forcing objectives를 통해 학습한다. 이렇게 얻은 가상의 게임 플레이어는 학습된 policy를 통해 사람 흉내를 내면서 게임과 상호작용하면서 Diffusion 모델 학습에 필요한 데이터를 수집하는데에 사용된다. (사람을 완전히 흉내내진 못하더라도 충분히 다양한 시나리오, 예제들을 생성하여 학습 데이터를 효과적으로 구축한다)
이후, 수집된 T_agent 데이터셋을 이용하여 Generative Diffusion 모델을 학습시킨다. 여기에는 사전학습된 State Diffusion 1.4 버전 모델이 사용된다. 이전 단계에서 수집한 T_agent의 행동 데이터와 이전 프레임 데이터를 입력하여 다음에 생성될 프레임을 예측하도록 Diffusion 모델을 학습시킨다. 이 때, 텍스트 조건문들은 전부 제거하고, 행동은 Action Embedding을 만들어서 학습 과정중에 학습되도록 한다. Action Embedding은 예를 들어 유저가 키보드 방향키 위를 눌렀으면 그에 맞는 임베딩 벡터를 할당하고 해당 임베딩 벡터가 학습되도록 하는 것이다. 그리고 Diffusion 모델에서 적용되는 텍스트 데이터간의 Cross-Attention에서 텍스트를 인코딩된 액션 시퀀스로 변환하여 입력한다. 인코딩된 프레임과 액션은 결합되어 Auto-Encoder를 통해 Latent Space로 인코딩한다. 그 후 Latent 공간에서 노이즈가 섞인 형태로 변형되어 다음 프레임을 예측하는데에 사용한다.
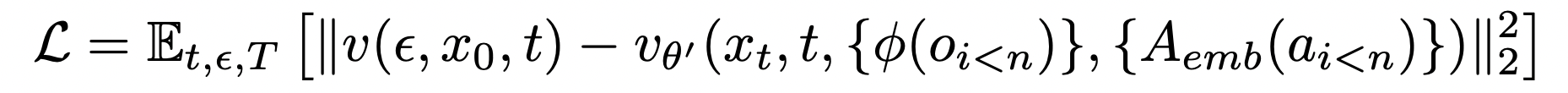
Teacher Forcing과 Auto-Regressive를 이용한 도메인 변화는 에러 축적이나 빠른 성능 감소로 이어질 수 있다. 이러한 문제를 해결하기 위해서 일부러 컨텍스트 프레임에 가우시안 노이즈를 추가하여 학습에 적용하였다. 이를 통해서 모델은 이전 프레임에서 적절한 정보들을 샘플링할 수 있었다. 아래의 그림은 Noise Augmentation을 했을 때와 안했을 때의 차이를 보여준다.
=> Teacher Forcing을 하게 되면, 항상 Ground Truth의 완벽한 이미지가 입력으로 들어오게 된다. 하지만, 실제 실행 과정에서 Diffusion 모델이 생성하는 픽셀은 완벽하지 않을 수 있고 다소 노이즈를 포함하고 있을 수 있다. 그렇기에 완벽한 데이터로만 학습한 모델은 이러한 노이즈가 포함되는 경우 학습 과정에서 경험하지 못한 데이터가 포함되어 빠르게 픽셀이 붕괴될 수 있다.

그림 2. 노이즈를 적용했을 때(아래)와 안했을 때(위)의 차이
사전학습된 Stable Diffusion 모델은 8X8의 픽셀 패치들을 4 Latent 채널로 변환하여 다음 프레임을 예측할 때 의미있는 형태로 만들어준다. 하지만 HUD와 같은 디테일한 부분에는 그러한 인코딩된 형태가 많은 영향을 주지 못한다. 사전학습된 지식들을 잘 이용해서 이미지의 품질을 개선하기 위해서 학습 과정에서 Decoder만 Target Frame과의 MSE Loss로 학습하였다.
Inference 단계에서는 DDIM 샘플링을 채용하고, Classifier-Free Guidance를 적용하였다.
- DDIM 샘플링은 Denoising Diffusion Implicit Models의 약자로, 기존의 DDPM 방법에서 샘플링 품질을 약간 포기하고 속도와 안정성을 개선한 방법(https://junia3.github.io/blog/ddim)
- 기존 Classifier Guidance에서는 추가적인 Classifier를 학습시켜야 하기 때문에 학습의 파이프라인이 복잡해지고 사전학습된 모델을 적용할 수 없다는 단점이 있었는데, 분류기를 따로 사용하지 않고 클래스 정보를 Diffusion 모델에 Condition으로 입력하는 방법으로 해결하였다 (https://pitas.tistory.com/15)
샘플링 단계에서는 급격하게 변하는 예측 값들을 방지하기 위해 병렬로 4개의 샘플을 생성하고 조합하는 방식으로 접근하였다. 예를 들어 4개의 데이터를 샘플링하고 평균을 내거나, 혹은 4개의 샘플 중에 Median 값을 선택하는 등의 방법을 적용하였다. (실험 결과에서는 4개의 샘플을 평균내는게 조금더 나은 결과를 냈다고 하였다)

위의 그림은 모델의 예측 결과와 실제 게임 실행 화면을 비교한 결과이다.
오늘 살펴본 논문에서는 완전히 신경망만으로 게임 엔진을 구현한 결과를 살펴보았다. 그 과정은 크게 2가지로 나누어졌는데,
- 강화 학습을 통해서 유저의 행동을 모방하면서 게임을 플레이하는 에이전트를 만든다. (학습을 위한 프레임 데이터 수집에 필요한 것이므로 에이전트가 정교하게 잘 행동하거나, 아주 똑똑할 필요는 없다)
- 에이전트를 통해 수집된 프레임 학습 데이터를 기반으로 유저의 행동 정보와 이전 프레임들을 입력하고 다음에 나올 프레임을 예측하는 Diffusion 모델을 학습시킨다.
Diffusion 모델에 입력되는 텍스트 정보의 입력 부분을 유저의 행동 정보를 입력하는 부분으로 대체하고 다음 프레임을 예측하는 모델을 만들어 게임엔진을 시뮬레이션하는 모델을 학습시켰다.
이미지 생성 모델을 이용해서 게임엔진을 만든 컨셉 자체가 되게 특이하고 재밌었으며, 앞으로도 이러한 새로운 방식의 게임 컨텐츠 생성에 관한 논문들을 더 찾아볼 예정이다.