오늘 살펴볼 논문은 “Training Language Models to Self-Correct via Reinforcement Learning”이다.
해당 논문은 DeepMind에서 발표한 Self-Correction과 관련된 논문이다.
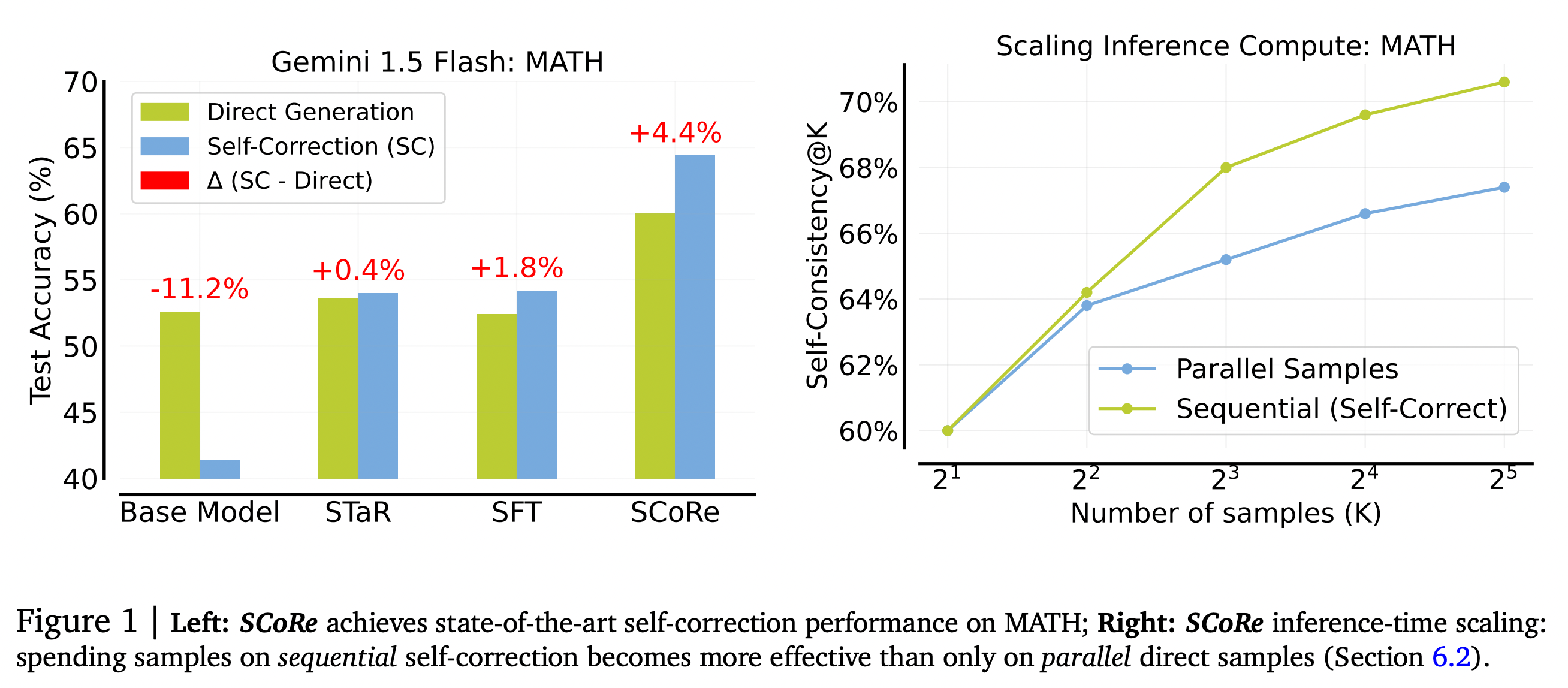
그림 1. 제안된 SCoRE의 성능과 다른 방법들의 성능 비교
Self-Correction은 LLM이 어떤 태스크에 대한 답변을 생성했을 때, 해당 모델이 생성한 답변을 기준으로 틀린 부분을 고쳐서 더 개선된 답안을 얻기 위한 방법이다. 답변에 실패하는 케이스들을 살펴보면, 많은 질문들에서 LLM이 답변할 수 있는 Knowledge를 포함하고 있음에도 불구하고 그러한 지식들을 끌어내어 추론하는데에 실패하여 답변을 제대로 생성하지 못하는 경우가 많다. 예를 들어 Strong LLM들은 수학 증명 문제에서 남은 부분을 채우게 하는 태스크는 잘 수행하지만, Scratch부터 생성하게 하는 경우 잘 동작하지 않을 수 있다. 이러한 것과 마찬가지로, Self-Correction은 이전에 만들었던 답변을 활용하여 더 나은 답변을 생성하도록 유도하는 것이다.
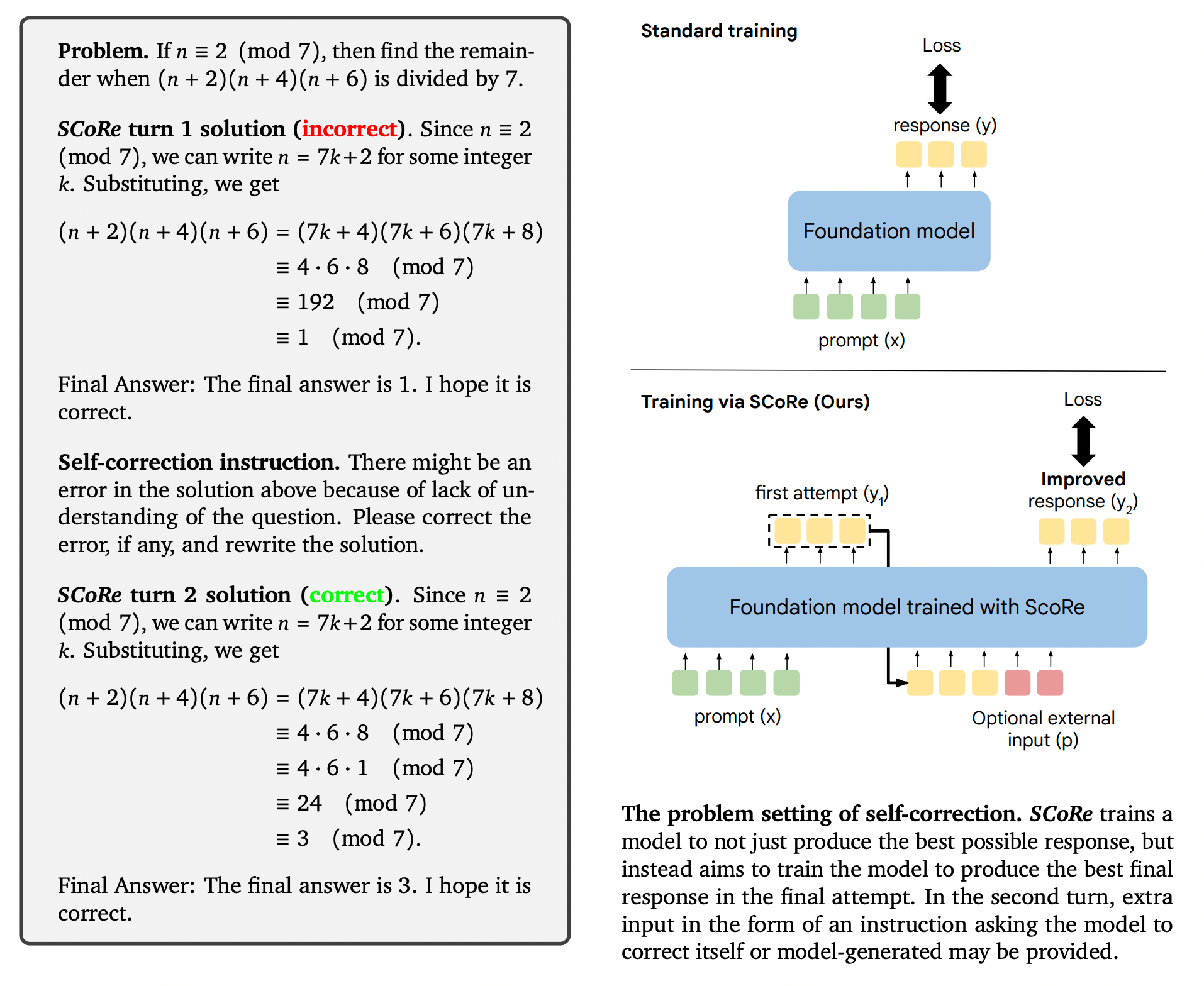 그림 2. Self-Correction의 예시
그림 2. Self-Correction의 예시
기존에 발표되었던 Self-Correction 방법들은 프롬프트 엔지니어링을 이용하거나, Self-Correction 데이터셋을 만들어서 파인튜닝을 시키는 등의 방법을 적용하였다. 프롬프트 엔지니어링 방법은 내제된 의미있는 Self-Correction을 이끌어낼 수 없었다. 후자의 방법은 Separate Verifier나 Refinement Model을 이용하거나, 혹은 Self-Correction을 가이드하기 위한 Oracle “Teacher” 답변을 이용하게 된다. 그렇지 않으면, Self-Correction은 독립적이고 문제와 무관한 해결 방법을 생성하게 된다.
Self-Correction에서 실패하는 문제들을 먼저 조사해보았을 때, Rejection Sampling을 이용한 SFT 방법은 Error Correction을 생성하지 않으려는 모델의 Bias를 증폭시키는 모습을 보였다. 그로 인해서 Minimal edit strategy가 나타나는데, 모델이 Self-Correction 과정에서 잘못된 교정을 생성하는 것을 막기 위해서 아예 교정 자체를 잘 하지 않으려고 하는 현상이다.
Self-Correction을 학습하기 위한 데이터셋으로 STaR와 Pair-SFT 데이터셋이 있다. STaR는 모델이 Self-Correction하는 데이터들을 생성하도록 한 다음, 잘못 생성한 답변들을 올바르게 교정에 성공한 답변들만 필터링하여 학습에 적용하는 방법이다.
Pair-SFT 방법은 독립적으로 Correct, Incorrect 답변을 생성하도록 하고, Incorrect-Correct 답변으로 묶어서 데이터셋을 구성하는 방법이다.
STaR는 모델이 연속으로 생성한 데이터를 사용하기 때문에 Distribution Mistach의 영향을 최소화할 수 있고, Pair-SFT는 모델이 Correction 과정에서 최소한의 Edit만 수행하려는 현상을 줄일 수 있다. 하지만 반대로, Minor Edit만 유도하거나 Distribution Shift로 인해서 교정에서 오히려 더 나쁜 답변을 생성하는 문제가 각각의 데이터에서 발생하게 된다.
해당 논문에서 제안하는 SCoRE는 Reinforcement Learning을 이용한 Online 학습 방법을 통해서 이러한 문제를 극복한 Self-Correction 방법을 제안하였다.
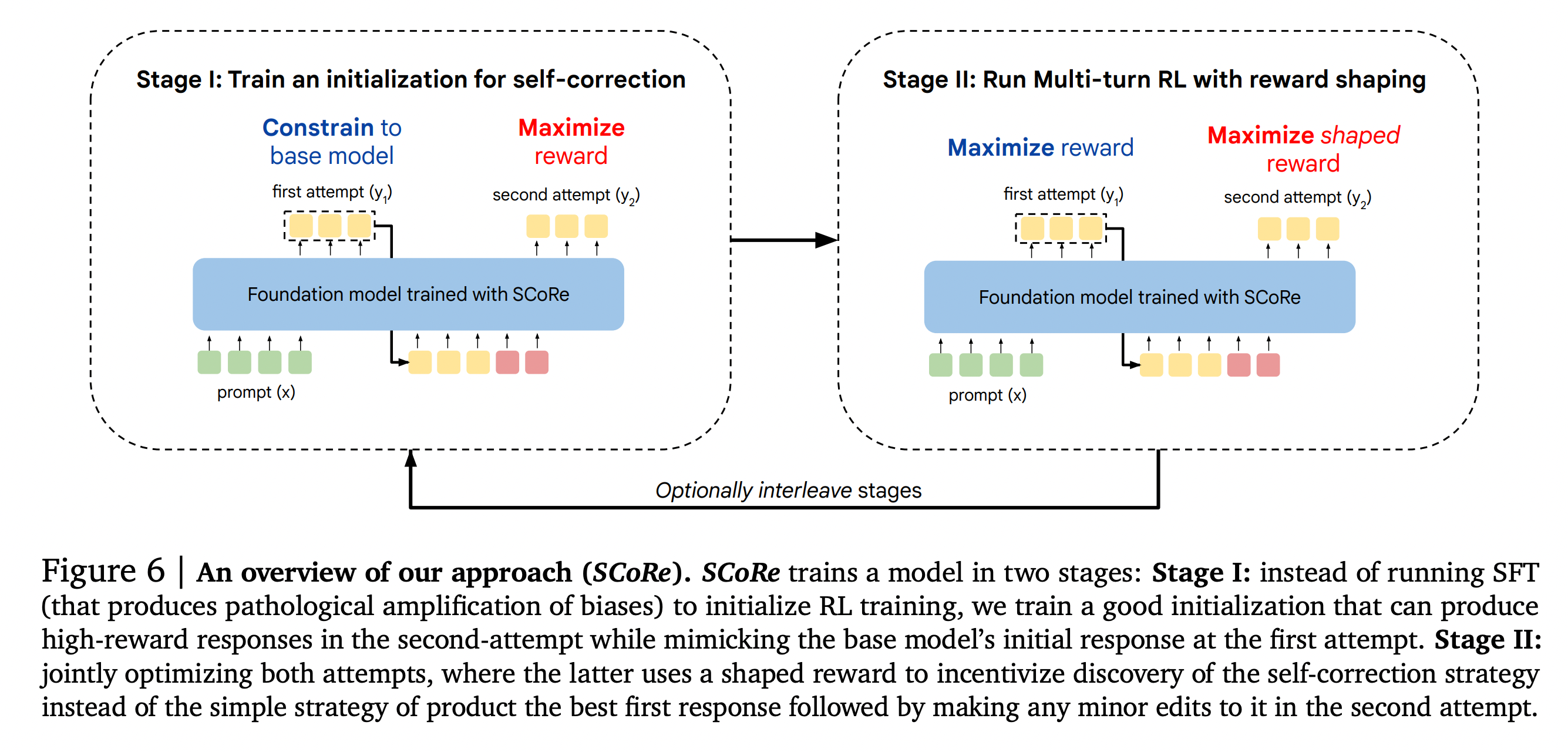
그림 3. SCoRE 학습 방법 및 구조
위의 그림은 논문에서 제안한 SCoRE의 전체적인 구조를 나타낸다. ScoRE는 Stage 1,2의 두 개의 단계로 이루어져 있다.
Stage 1
Step 1에서는 Base 모델의 두 번째 접근에서의 Coverage를 높이는데에 있다. 해당 단계는 사실 SFT를 이용한 파인튜닝에서도 실행 될 수 있지만, SFT 학습은 하나의 수정 방법에만 고착되어서 ‘교정’의 의미에서 제대로된 학습을 하지 못하는 경우가 많았다.
모델의 첫 번째 교정이 Base Model의 답변의 분포와 유사하게 나오도록 제약을 하면서, 두 번째 답변에서는 Reward가 높은 답변을 생성하도록 학습을 하였다. Base 모델의 답변 분포와 첫 번째 답변의 분포가 유사하도록 KL Divergence를 Loss에 추가하였다.
학습은 다음과 같은 수식을 통해서 진행된다.
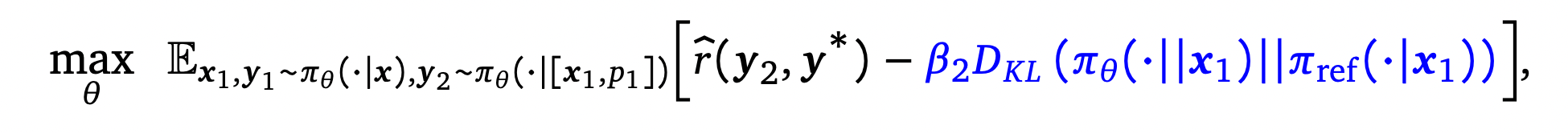
Stage 2
두 번째 단계에서는 첫 번째 Attempt에서는 이전 단계의 두 번째 Attempt를 학습시키는 것과 같이 Reward를 최대화하도록 학습하고, 두 번째 Attempt는 Shaped Reward를 최대화하도록 학습한다.
Stage 2의 학습은 다음과 같은 수식을 통해서 진행된다.
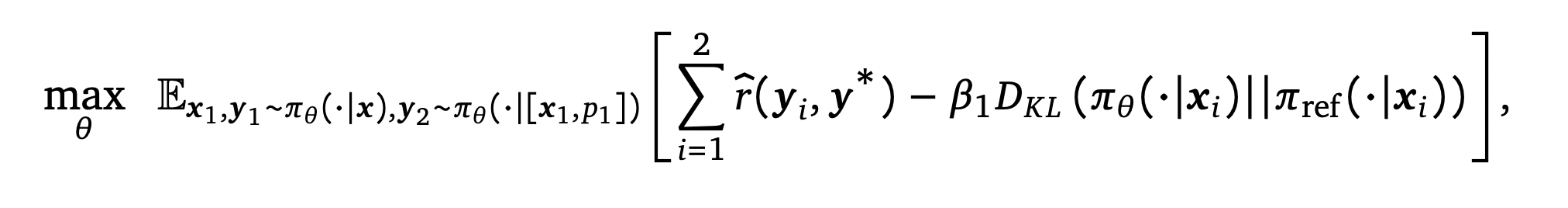
우선 위의 수식을 살펴보면, 첫 번째와 두 번째 답변이 같은 방식으로 학습되는 것을 볼 수 있다. 이렇게 되면 모델은 굳이 두 번째 단계에서 잘 교정을 하기 보다는 그냥 첫 번째 답변에서 바로 좋은 답변을 생성하고, 두 번째 단계에서는 굳이 교정을 하지 않고 첫 번째 단계의 답변을 그대로 가져오기만 하면 될 수 있다. 이러한 문제를 해결하기 위해서, 첫 번째 답변에서 두 번째 답변으로 교정을 할 때 잘 수정을 하면 인센티브를 주는 것과 같은 추가적인 Reward를 구성하였다.
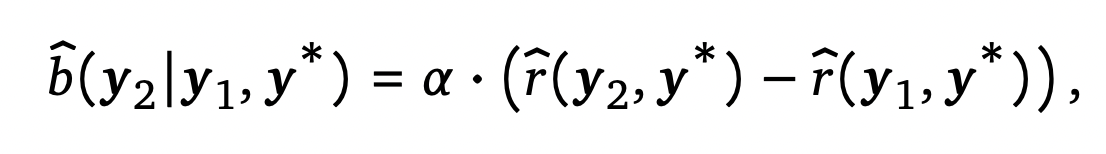
이로 인해서 두 번째 답변에서 더 높은 Reward를 받도록 교정을 하면 더욱 많은 Reward를 얻을 수 있다.
실험 결과
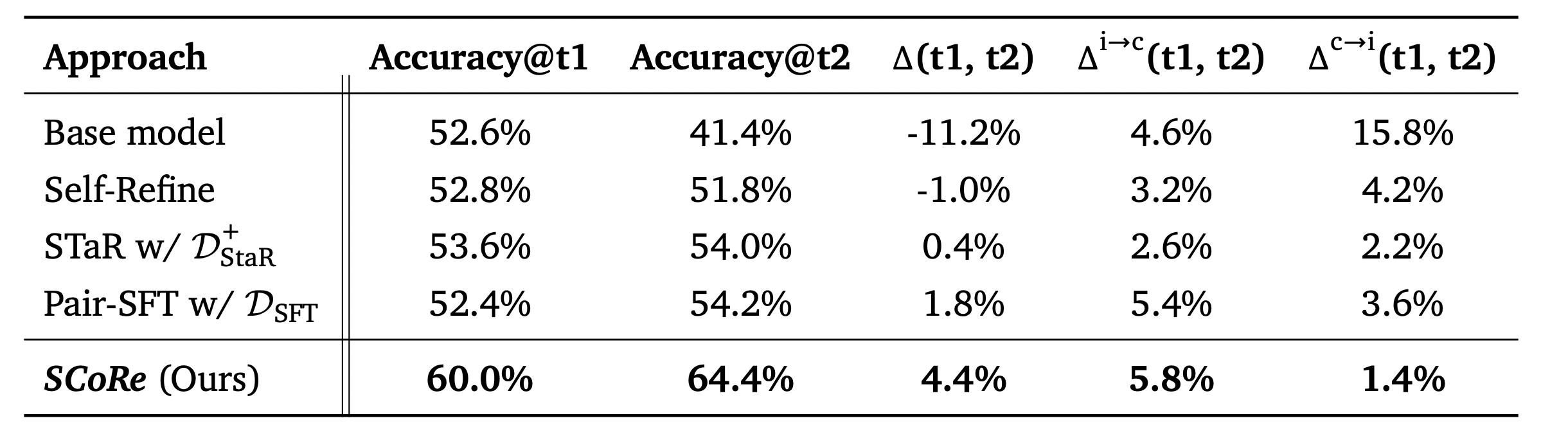
그림 4. 제안된 모델의 성능
모델의 평가는 Accuracy 뿐만 아니라 다른 지표들도 적용하였는데, 그림 4의 세 번째 열의 지표는 첫번째 답변의 성능과 두번째 답변 간의 정확도 차이를 나타낸다. 네 번째 열의 지표는 첫 번째 시도에서 잘못 답변했는데 두 번째 답변에서 제대로 답변한 데이터의 Fraction을 나타내며, 마지막 지표는 첫 번째 시도에서는 잘 맞췄지만 두 번째 시도에서 오히려 잘못 답변한 데이터의 Fraction을 나타낸다.
베이스 모델은 당연하게도 교정을 할수록 오히려 성능이 크게 감소하는 것을 살펴볼 수 있다. STaR는 두 번째 시도에서 답변이 오히려 나빠지는 케이스는 적지만, 교정을 하면서 더 성능이 좋아지는 데이터의 비율도 그만큼 낮았다. Pair-SFT는 두 번째 시도에서 교정된 비율이 많긴 하지만, 그만큼 첫 번째 시도에서 잘 답변한 데이터를 교정하면서 오히려 잘못 답변하게 하는 케이스도 많았다. SCoRE는 Pair-SFT와 STaR의 장점들을 가져오고, 단점들은 제거하여 교정에서 잘못된 답변으로 교정하는 비율은 줄이면서 교정을 통해 답변을 맞게 교정하는 비율은 오히려 증가시킬 수 있었다.
이번 글에서는 강화학습 방법을 이용한 Online 형식의 Self-Correction 학습 방법을 살펴보았다. 교정을 위한 데이터를 구성할 때, 임의로 “잘못 생성된 답변=>잘 생성된 답변”을 묶었을 때는 Distribution Shift 문제가 발생하고, 모델을 통해서 Online으로 한 번에 생성한 연속된 답변을 학습에 사용할 때는 학습된 모델이 교정을 하지 않으려고 하는 문제를 보였다.
해당 논문에서는 Stage 1에서는 기존 방법과 같이 학습하되 강화학습을 젹용하고, Stage 2에서는 두 번째 답변에서 교정이 잘 되면 더욱 Reward를 주는 Incentive를 반영한 Reward를 학습에 적용하였다.
모델의 학습에서 발생하는 다양한 문제점을 분석하고, 차근차근 해결해나가는 부분이 많은 공부가 되었던 논문이다. 꼭 Self-Correction이 아니더라도 추후 다양한 태스크를 학습할 때 적용해볼 수 있는 개념들이 많이 있었던 것 같다.