오늘 살펴볼 논문은 “TABLEFORMER: Robust Transformer Modeling for Table-Text Encoding”이다.
해당 논문은 TAPAS의 문제점을 지적하고 해당 모델을 개선한 모델이다.
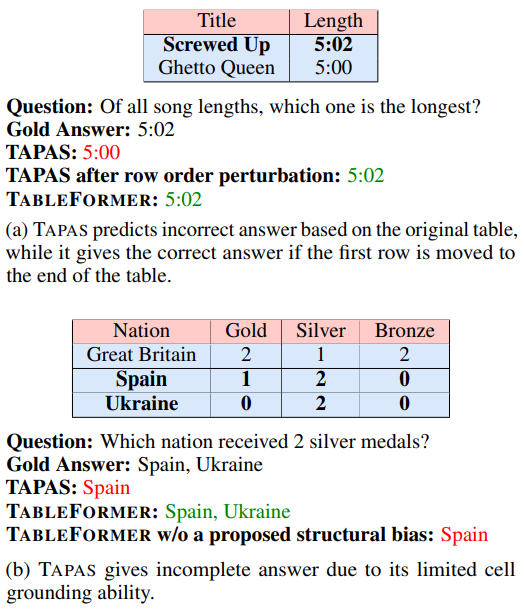
그림 1. 기존 표 인코딩 모델의 문제점 제시
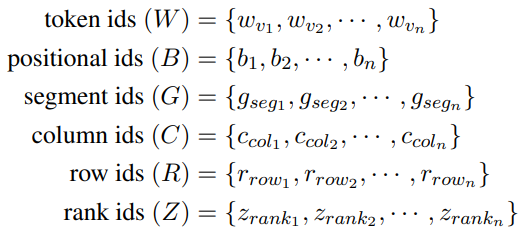
그림 2. TAPAS에 입력되는 임베딩 목록
위의 그림은 TAPAS의 한계점을 지적하고 있다. 우선 TAPAS에서 제안했던 핵심 아이디어를 살펴보면, 2차원 구조를 가지는 표를 BERT와 같은 언어모형에 입력하기 위해서는 평면화하는 작업이 필요한데, 이러한 평면화 과정에서 표가 가지고 있던 2차원의 구조적인 정보가 손실되게 된다. 이러한 구조적인 정보를 인코딩하기 위해서 TAPAS에서는 표를 위한 특수한 임베딩(Row, Column, Rank, Inverse-Rank 등)을 추가하여 표의 구조적인 정보를 인코딩하였다는 것이다.
이러한 특수 임베딩은 마치 Position 임베딩과 같은 구조로 추가가 되었는데 예를 들어 3번째 Row에 해당하는 토큰들에는 마치 3번쨰 위치의 포지션 임베딩이 추가되는것과 같이 적용되는 것이다. 하지만 이러한 임베딩 추가로 인해서 위의 그림에서 지적한 TAPAS의 한계점이 발생하게 되었다. Position 임베딩은 결국 위치에 종속적인 특성을 가지게 되는데 Table Parsing 태스크는 일반적으로 셀과 셀의 비교를 통한 연산 결과를 얻는 것이 주 목적이다. 그렇기에 위의 그림과 같이 똑같은 표를 위치만 바꾸어서 입력하면 Row의 순서가 뒤바뀐 것 외에는 완전히 똑같은 표 데이터임에도 불구하고 제대로된 예측을 하지 못하는 경우를 보여주게 된다. Tableformer에서는 이러한 문제를 해결하고 Row의 위치가 뒤바뀌더라도 강건한, 특수 임베딩 추가로 인한 행과 열의 위치에 종속적이지 않은 표 인코뎅 모델을 제안했다.
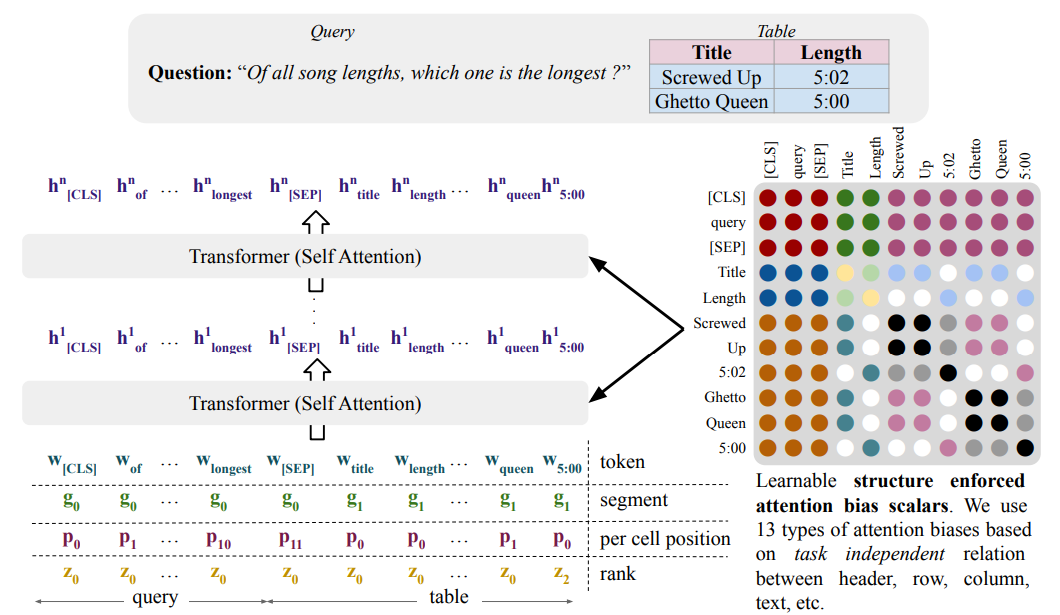
그림 3. Tableformer의 Attention Bias 구조
위의 그림은 Tableformer에서 제안한 표의 구조적인 정보를 잘 포착하도록 하면서도 행과 열의 위치에 종속적이지 않은 모델을 위해 추가한 모델의 구조이다. 해당 논문에서는 행과 열의 임베딩을 추가하는 대신 셀프 어텐션 레이어에서 적용되는 Attention Bias를 추가하였다. 예를 들어, Title 셀과 Screwed UP은 서로 헤드와 셀 텍스트의 관계를 가진다. 5:02 셀과 5:00 셀은 서로 같은 Column에 있는 관계를 가진다. 이러한 각 토큰들의 관계를 13가지로 정의하고 Selft Attention Layer에서 적용되는 Bias를 추가한 것이다.
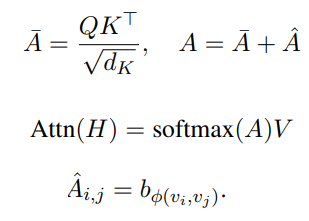
그림 4. Attention Bias 관련 수식
수식만 봐서는 직관적으로 어떤 구조로 적용되는지 이해되지 않을 수 있다. Tapas의 github 레포지토리의 modeling.py를 살펴보면 어떻게 구현되었는지 살펴볼 수 있다.

그림 5. Attention Bias 구현 코드
Self Attention의 확률 값에 bias 값을 바로 더하는 것을 확인할 수 있으며, 이 Bias는 당연히 Trainable Weights이다. Bias는 attention score에 바로 더하기 때문에 Head 개수만큼의 크기를 가지는 것을 확인할 수 있다.
그렇다면 여기서 생각할 수 있는 부분은 왜 Relative한 정보를 가지고 새로운 Layer를 만들어서 적용하거나 하지 않고 단순한 Bias만 적용한 것일까? 해당 논문은 Robust하지 않는 기존 모델을 지적하면서 해당 아키텍쳐를 제시하였다. 복잡한 레이어의 추가는 또 다른 fitting이나 문제를 만들어낼 수 있다고 생각한다. 그렇기에 단순하면서도 강력한 방법을 적용하였다고 생각했다.
이번 글에서는 강건한 표 인코딩 모델을 구현하기 위해 Self-Attention에 각 토큰의 관계를 나타내는 Bias를 추가한 Tableformer 모델을 살펴보았다.