이번 연구에서는 Table 데이터에 잘 동작하는 언어모델 구축을 위한 다양한 모델 아키텍쳐, 사전학습 방법 그리고 이와 관련된 Downstream 태스크들을 정리해놓은 Survey 논문을 정리하고 공부해보았다.
사전학습 언어모델은 다양한 자연어처리 태스크에서 활용되어 많은 성과를 보여주었다. 하지만 표 데이터는 자연어 텍스트 데이터와는 다른 특성을 가지고 있기 때문에 사전학습 언어모델을 표 데이터에 그대로 적용하는 것은 때로는 비효율적일 수 있다. 논문에서는 다음과 같은 점들을 표와 텍스트의 핵심적인 차이점으로 보고 있다.
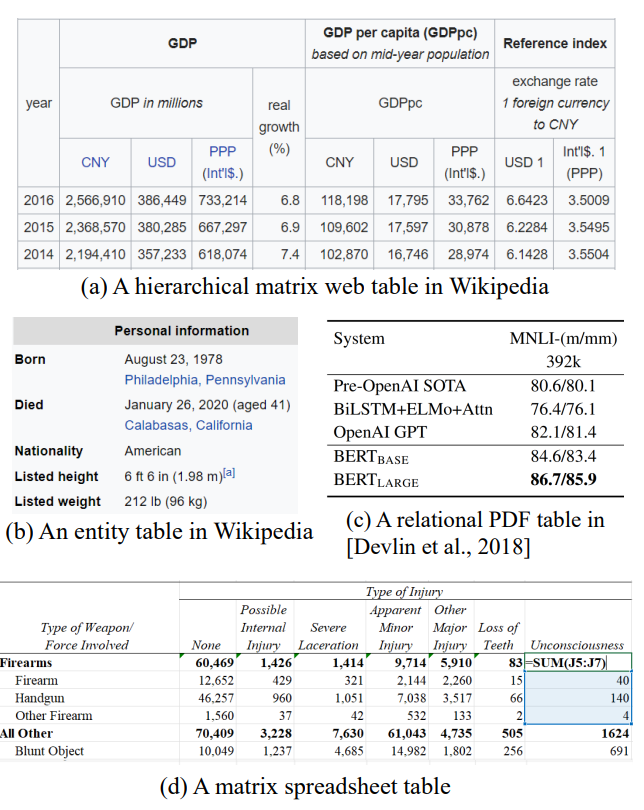
그림. 다양한 형태의 표 데이터들
- 구조적인 차이 – 표는 2-D 형태의 구조를 띄고 있다
- Visuual Formats – 텍스트 데이터와 다르게 테이블은 데이터를 더 잘 표현하기 위한 포멧들을 이용한다(하이라이트, 색, 폰트)
- Numerical Values – 테이블은 일반적으로 잘 정리된 Numerical 데이터를 다루고 있으며, 이를 비교 하거나 계산하는 등에 활용하는 경우가 많다
이러한 텍스트 데이터와의 차이점으로 인해서 표 데이터를 기존의 LM에 그대로 적용하는 것은 효과적이지 않을 수 있다. 이에 많은 연구들이 테이블 데이터에 특화된 TaLM을 위한 사전학습 방법 및 연구를 제안하였다.
본 논문에서는 이러한 TaLM을 위한 여러 가지 사전학습 방법, 데이터, 태스크 등을 정리한 논문이다.
2-D의 구조적인 정보는 반-구조화된 테이블을 이해하는데에 중요한 역할을 한다. 이를 위한 많은 신경망 기반의 모델 구조가 제안되었다.
Skip-gram 구조를 적용한 Table2Vec, CNN을 적용한 모델, 양방향 LSTM(RNN)을 적용한 모델 등 다양한 기법들이 표 데이터에 적용되었었다. 이후 연구에서는 Graph Neural Network를 표 데이터에 적용한 연구들도 공개되었다. 하지만 이러한 CNN, RNN, GNN 등이 이전 연구에서 광범위하게 테이블을 모델링하기 위해 적용되었지만 이러한 구조의 모델들은 표 데이터를 위한 사전학습 모델에는 채택되지가 않았다. 왜냐하면 저러한 모델들은 token/word 임베딩과 모델을 분리하여 학습을 시키기 때문이다.
최근에는 이러한 한계점을 극복한 트랜스포머가 적용된 언어모델들이 테이블 데이터의 모델링에 많이 활용이 되었다. (TaBERT, TAPAS, TRL, TUTA 등…) 테이블 데이터에 특화된 사전학습 없이도 향상된 성능을 보인 모델이 많았는데, 이는 텍스트 데이터로부터 사전학습된 지식이 표를 이용한 태스크에서도 충분히 전이될 수 있음을 보였다.
표 데이터를 트랜스포머 기반의 모델에 입력하기 위해서는 2-D의 표 데이터를 평면화하여 1-D의 형태로 만들어주는 작업이 필요하다. 표를 평면화 하는 작업은 연구에 따라서 조금씩 다르게 적용되었는데 대부분의 연구에서는 Row by Row의 방향으로 셀의 텍스트를 이어붙여서 평면화하는 방법을 적용했다. TAPEX에서는 다른 연구들과 마찬가지로 Row-by-Row로 평면화를 했지만 “Row 1: a | b | c Row 2: d | e | f”와 같이 행/열을 구분하기 위한 부가적인 정보를 부착해주었다. UnifiedSKG의 실험에서는 표와 텍스트를 같이 입력할 때, 텍스트 데이터를 먼저 입력하도록 하는 것이 더 나은 Generalizaion 효과를 보였다고 하였다. 이 외에도 가장 관련있는 Row만 추출하여 입력하는 경우(TaBERT), Head 데이터만을 입력하는 경우(GraPPa)가 있었다.
Input Featurization and Embedding
다음으로는 TaLM에서 적용된 입력 특징(Feature)와 임베딩에 대해서 살펴보겠다.
셀 텍스트 인코딩은 토큰화된 셀 텍스트를 기존의 텍스트 데이터를 인코딩하는것과 같은 방법(BERT의 방법)으로 적용했다. 연구에 따라서 BPE, WordPiece 등 토큰화 방법에서 차이를 보였다.
NL 사전학습 모델에서는 입력된 토큰의 위치를 나타내는 Position Embedding을 적용했다. 마찬가지로 TaLM에서도 이러한 Position Embedding을 적용했다.(TaPas, MATE, StruG, GraPPA, TAPEX) 몇몇 연구에서는 테이블 데이터를 몇 개의 세그먼트로 나누고, 각 세그먼트끼리는 독립된 Position Embedding을 가지도록 하였다. TURL에서는 테이블 데이터와 테이블 Description을 별도의 세그먼트로 나누도록 하였다. TaPas의 후속 연구와 TableFormer에서는 Reset Position Index를 적용하였는데 셀이 바뀔 때 마다 Position을 리셋해서 마치 별도의 세그먼트처럼 처리하였다.
테이블 데이터는 2-D 구조를 가지지만 Postition 임베딩은 1-D 형태로 데이터를 표한하기 때문에 적합하지 않을 수 있다. TaPas, MATE, TUTA에서는 학습가능한 Col/Row 임베딩을 적용하여 2-D 구조를 반영한 추가 Position Embedding을 적용하였다. 위의 그림에서 (C) 부분을 살펴보면 테이블이 계층적인 형태를 띄고 있는데 TUTA에서는 이러한 계층적인 부분까지 고려하여 Tree 구조를 기반으로 한 Position Embedding 방법을 적용했다.
정리하자면
일반적인 Position Embedding: Tapas, MATE, StruG, GraPPa, TAPEX, TaBERT 등..
그 중에서 TAPAS는 후속 연구에서 Reset Position을 적용(예를 들면 셀이 바뀔 때 마다 0으로 Position을 리셋, [0, 1, 2, 0, 1, 2 …]
학습가능한 Col/Row 임베딩 추가: TAPAS, MATE, TUTA(Tree 기반의 구조를 반영하여 적용)
표의 구조적인 위치 정보를 인코딩하는 것 뿐만 아니라 표 데이터에 자주 등장하는 숫자 데이터(Numerical Data)를 잘 처리하기 위한 방법들도 적용되었다. 기존 방법들은 숫자 데이터가 있으면 그걸 텍스트로 변환하고 토큰화하여 처리하는 방법이 대부분이었다. (111500 => “111500” => [115, 000]) 하지만 이러한 방법은 숫자가 가지고 있는 크기 정보나 숫자들간의 관계정보(대소비교 등)가 사라질 수 있다.
금융 관련 문서나 과학 관련 문서에서는 aggregation, division, sorting, change ratio 등의 연산을 다루는 경우가 많기 때문에 Numerical Encoding이 더 중요하다. 숫자를 잘 표현하기 위한 많은 NLP 연구들이 존재하지만 이를 Tabular 데이터에 적용하고자 한 사례는 드물다. Tapas와 TUTA에서는 이러한 숫자 정보를 인코딩하기 위해서 Column-wise Ranking을 도입하였으며, 이는 Comarative, Superlative 질문에서 향상된 성능을 보였다.
FLAP은 텍스트 요약문에서 해당 Value를 언급하는지에 관한 Feature를 추가하였다.
TUTA는 순수 텍스트로부터 온 Numerical Value들을 4가지 특징을 통해서 인식하려고 하였다: First Digit, Last Digit, Magnitude, Precision
마지막으로 TaLM에서 적용될 수 있는 추가 Feature로 Format Encoding이 있는데 이는 테이블 구조를 이해하는데에 필요한 여러가지 힌트나 데이터 강조 정보들을 인코딩하기 위한 방법이다. 이는 TUTA에서 적용되었는데 예를 들면 셀 병합, 셀 경계, 폰트 강조, 폰트 색, 배경 색 등의 정보를 함께 인코딩하도록 하였다.
Encoder and Decoder Architectures
대부분의 TaLM 연구들은 기존의 아키텍쳐(BERT, GPT, BART 등)의 구조를 개량하는 방법으로 진행되었다. 대부분의 연구들은 BERT의 아키텍쳐와 비슷한 인코더 구조를 채택하였다. (TURL, StruG, TaPas, GraPPa, MATE, TUTA, ForTap, TableFormer 등…)
MRC는 토큰 내에서의 정답 위치를 예측하면 되며 이는 입력된 토큰의 위치를 기반으로 예측할 수 있다. 그 외에 감성 분류와 같은 텍스트 분류 태스크는 [CLS] 토큰과 같은 특수 토큰의 표현 벡터를 입력받아서 클래스 확률을 예측하면 된다. 하지만 간혹 일부 테이블 관련 다운 스트림 태스크에서는 인코더 모델에 일반적으로 적용되는 태스크 형태 외의 다양한 응용을 필요로 하는 경우가 많다. 예를 들면 여러 개의 셀을 선택하고 선택된 셀을 이용해서 어떤 계산하는 값을 구해야한다면 token classification 태스크와 text classification 태스크를 동시에 적용하면 되겠지만, WTQ와 같이 Weak Supervision 학습을 요구하는 경우에는 이에 맞는 특수한 예측 레이어 및 학습 방법이 필요하다.
단일 인코더 모델을 사용하는 것이 일반적이지만, TABBIE는 column-wise 인코더와 row-wise 인코더의 2개의 인코더를 사용하기도 하였다.
인코더 모델 외에 TaLM에서 많이 채택되었던 구조는 Encoder-Decoder 구조이다. BERT와 같은 인코더로 입력 시퀀스를 인코딩하고, 인코딩된 내용을 참조하여 문장을 생성하는 방법이다. 대표적인 모델로는 T5, BART가 있다. TaLM에서 이러한 Encoder-Decoder가 적용된 연구로는 대표적으로 TAPEX(BART), UnifiedSKG(T5)가 있다. 인코더 기반의 모델은 다양한 형태의 출력을 요구하는 다운스트림 태스크를 적용할 때 특수한 예측 레이어를 사용했지만 생성을 기반으로 하는 인코더-디코더 모델을 적용했을 때는 정답의 출력 형태에 크게 구애받지 않고 정답을 직접적으로 바로 생성할 수 있다는 장점이 있다.
Structure-based Attention
Transformer의 어텐션 매커니즘은 TaLM에서도 필수적으로 적용된다. 게다가 대부분의 TaLM은 Self-Attention 방법을 직접적으로 채택하고 있다. 테이블의 경우 어떤 셀 텍스트를 인코딩 할 때 대부분은 같은 Row/Column이 아니라면 연관이 없는 경우가 대부분이다. 이와 같이 입력되는 데이터의 구조에 맞게 어텐션을 적용하는 Structure-based Attention이 TaLM 연구에서 많이 적용되었다.
TaBERT에서는 row-wise 인코딩을 하고, 그 후 Column 표현 벡터와 Vertical Attention Layer를 적용하는 방식으로 Row-wise 입력 방법을 적용하였다.
TURL은 같은 Row/Column에 존재하는 토큰/엔티티끼리만 어텐션이 적용되도록 하는 제한적인 어텐션 매커니즘을 적용하였다. 또한 계층 테이블에 대해서는 Cell-to-Cell Distance를 적용하였는데 이는 양방향 트리를 테이블로부터 생성하여 적용하였다.
TABBIE에서는 Cell 임베딩으로 Row와 Column 임베딩을 평균낸 임베딩을 이용하였다.
MATE는 row와 column에 대해서 다른 유형의 Attention Head를 적용하였다. 또한 TURL와 같이 같은 Row/Column 토큰끼리만 어텐션이 적용되도록 하였다.
Table Retrieval 태스크에 초점이 맞춰진 모델인 GTR은 테이블 데이터를 테이블 그래프 데이터로 변환하고 그래프 어텐션을 적용하였다.
TableFormer에서는 Soft Attention Bias 방법을 제안하였는데, 어텐션이 적용되는 두 토큰 간의 관계에 따라서 Bias를 추가해주는 방법이다. (e.g. Cell-to-Cell Bias, Cell-to-Text Bias, Same-Row Bias 등…)
Model Efficiency
Input Selection
최근에는 Long Range Sequence를 위한 모델 아키텍처가 많이 제안되면서 극복되었지만, 일반적인 Self-Attention을 이용하는 Transformer 기반의 모델들은 메모리의 사용량이 입력의 길이에 제곱으로 비례하는 구조를 가지고 있기 때문에 긴 길이를 가지는 테이블 데이터를 처리하는 것은 어려울 수 있다. 초기 연구들은 입력 길이를 줄이기 위해서 Naive Way를 적용하였는데, 예를 들면 “Understaing tables with Intermediate Pre-training” 연구에서는 Max Length까지의 입력으로 입력 길이를 제한하되, 질문과 매칭되는 토큰이 많은 Row들을 선별하는 것과 같은 휴리스틱한 방법을 적용하기도 하였다. TaBERT에서는 질문과 겹치는 n-gram 비율을 기반으로 Content를 선별하였다.
TUTA는 일반적으로 긴 길이를 가지는 스프레드 시트를 이용할 때, 랜덤하게 50%의 텍스트 셀, 90%의 Numeric 셀들을 샘플링하여 입력에 사용하는 방법으로 입력의 크기를 줄였다.
DoT에서는 조금 더 향상된 입력 선별 방식을 제안하였는데, 입력 선별을 위한 비교적 작은 크기를 가지는 트랜스포머와 선별된 입력을 이용해서 태스크를 수행하는 트랜스모머의 2개의 인코더를 이용하는 방식이다. Pruning Transformer에서 태스크 수행에 필요한 관련성이 높은 Top-K 토큰들을 먼저 선별하고 선별된 토큰들을 task-specific 트랜스포머에 입력하여 태스크 예측 결과를 출력한다. 긴 입력의 테이블 데이터는 비교적 작은 크기(small, medium)를 가지는 Pruning-Transformer에서 처리하고, 비교적 큰 크기(base, large)를 가지는 트랜스포머에는 K개의 토큰만 입력되기 때문에 학습 및 추론에서 빠른 속도를 보일 수 있다. 여러 태스크에서 Pruning Transformer는 Medium이나 Small 크기를 적용하는 것 만으로도 충분한 성능을 보였지만 일부 WTQ와 같은 태스크에서는 작은 크기의 Pruning Transformer의 성능이 크게 떨어지기도 하였다.
Input splitting – 입력을 선별하는 방법 외에 입력을 나누어 처리하는 것도 가장 일반적인 방법중 하나이다.
Sparse Attention
MATE에서는 ETC의 구현 방법을 따라서 Sparse Attention 방법을 테이블 인코딩에 적용하였다. 일반적으로 TaLM에서 Sparse Attention은 효율(Efficiency) 보다는 성능(Downstream task에서의 Performance)를 올리는데에 많이 활용되었지만 MATE 및 ForTap에서는 어텐션이 적용되지 않는 부분(Col/Row가 서로 다른 셀)에 관한 필요하지 않는 연산을 최대한 줄이는 연산 방법으로 효율을 높인 아키텍쳐를 제안하였는데, 이는 CUDA kernel을 이용해서 프레임워크를 구현하는 방법을 이용했다.
Pre-training Objectives
TaLM에서는 LM이 표의 구조적인 정보를 잘 캐치하면서도 입력된 자연어 텍스트와 테이블 데이터 간의 상호작용을 잘 할 수 있는 사전학습 방법들이 필요하다. 이 섹션에서는 TaLM에서 적용된 다양한 Pre-training Objectives를 설명한다.
Denoising Autoencoder Objectives
BERT에서는 [MASK] 토큰으로 Denosing한 입력을 받고 [MASK]에 들어갈 원본 토큰을 예측하는 방법으로 사전학습을 하였다. MLM이 적용되는 입력 단위에 따라서 “Token, Cell, Column” 레벨로 나눌 수 있다. 대부분의 TaLM에서는 Token-level MLM을 적용하였는데, TaPas, MATE, TableFormer 등에서 적용하였다. 사전학습 방법은 BERT에서와 같이 약 15%의 토큰을 랜덤하게 마스킹하고 마스킹된 원본 토큰을 예측하도록 하였다. 마스킹하는 비율은 연구마다 조금씩 다르게 적용되기도 하였는데 TURL에서는 20%, TUTA에서는 30%의 마스킹 비율을 적용해서 사전학습 태스크를 조금 더 Challenging하게 만들었다. TaBERT에서는 다른 연구들과 다르게 NL 텍스트 토큰에만 MLM을 적용하기도 하였으며, GraPPa와 TURL은 NL 텍스트 토큰와 Header 토큰에만 MLM을 적용하였다.
Cell-level 태스크에서는 가장 대표적으로 Masking and recovery 방법이 적용되었는데, TUTA에서는 whole-cell Masking 방법을 적용하여 셀 단위로 마스킹이 되도록 하였다. TaBERT에서는 Cell Value Recovery를 적용하였는데, Masking 된 셀 텍스트를 예측하되 여러 토큰으로 이루어진 셀 텍스트를 예측하도록 하기 위해서 SpanBERT에서 적용된 사전학습 방식을 적용하였다.
TaBERT에서는 마스킹된 Column 텍스트를 예측하는 Masked Column Prediction Objective를 같이 적용하여 Column-level Objective도 함께 먹용하였다.
Task-Specific Objectives
MLM과 같이 사전학습을 위해 만들어진 Denoising 태스크뿐만 아니라 어떠한 태스크를 수행하면서 모델을 사전학습하는 Task-Specific Objectives도 다양한 TaLM에서 적용되었다.
- GraPPa에서는 NL 텍스트와 Column 헤더를 입력받고 입력된 각 Column들이 SQL 쿼리에서 나타나는지 그리고 어떤 Openration을 적용해야하는지를 예측하는 태스크를 사전학습에 적용하였다.
- StruG는 text-to-SQL 변환을 하는 여러가지 grounding 태스크들을 사전학습 Objectives로 적용하였다.
- TaPEX는 Neural SQL 실행기로써, SQL 쿼리와 DB(테이블) 데이터를 입력받고 SQL의 실행 결과를 예측하는 태스크를 사전학습하였다.
- GAP은 테이블 데이터에 대해서 복잡한 SQL을 생성하도록 하는 태스크를 적용하였다.
외에도 “Understanding tables with intermediate …” 연구는 입력된 테이블과 NL 텍스트가 Entail, Neural, Conterfactural 중에 어떤 관계인지를 예측하는 Table Fact Verication 태스크를 MLM 태스크 이후에 Intermediate 사전학습 태스크로 적용하였다.
TURL은 엔티티 연결 태스크를 사전학습 태스크로 적용하였으며, 이 외에도 테이블 타입 분류 및 테이블 검색(TUTA), 스프레드 시트의 수식을 활용한 Numerical Reasoning(ForTap) 등의 태스크가 사전학습 Objectives로 적용되었다.
테이블 데이터는 구조적인 형태를 가지기 때문에 자연어 텍스트 데이터와 비교하여 비교적 인공적인 데이터를 생성하는 것이 용이하다. 이러한 특성에 더하여 표를 이용한 학습 구축이나 사전학습 데이터 수집은 자연어 텍스트에 비해서 더 까다롭기 때문에 많은 연구에서 인공적으로 합성한 사전학습 및 학습 데이터를 구축하는 연구를 진행하였다.
GraPPa는 Synchronous Context Free Grammar를 이용해서 인공적인 NL-SQL 쌍을 생성하고 사전학습 태스크에 이용하였다. Intermediate Pretraining 연구에서는 위키피디아의 엔티티 링크 정보를 활용해서 자동으로 Table Fact Verfication 데이터를 생성하거나 혹은 Context-free Grammar를 이용해서 아예 인공적인 Verification 학습 데이터를 생성해서 사전학습에 적용하였다. TaPEx에서도 사전학습을 위한 SQL 쿼리 생성을 위해서 WIKITQ의 학습셋에서 랜덤하게 데이터를 선택하고 SQL 템플릿을 만들고 이를 이용하여 SQL 쿼리를 자동으로 생성하였다.
Downsteam Tasks
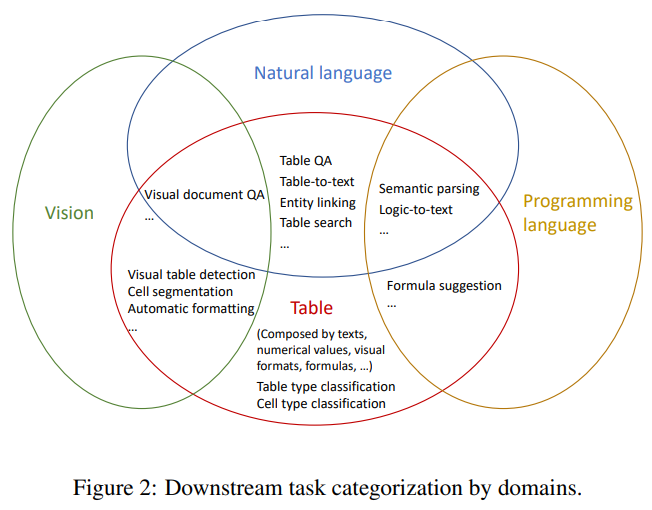
위의 그림과 같이 Table Understanding 태스크에는 비전, 자연어, 프로그래밍 언어, 테이블의 다양한 도메인의 태스크들이 교차되어있다. 예를 들어 대부분의 Table-QA에서는 테이블 데이터와 자연어 쿼리를 입력받고 이에 대한 답을 해야하므로 테이블과 자연어 텍스트의 교차 태스크라고 볼 수 있다. 테이블과 자연어 쿼리를 입력받고 해당 쿼리의 답을 얻기 위한 SQL 쿼리를 생성하는 것은 프로그래밍 언어까지 3가지 도메인이 결합된 태스크라고 볼 수 있다.
이번 글에서는 TaLM을 깊게 Survey한 논문을 살펴보았다. 현재깢지의 TaLM에서 적용된 데이터, 사전학습 태스크, 방법론, 구조 등을 비교하면서 살펴볼 수 있었으며 큰 흐름을 한번에 읽어볼 수 있었던 논문이다.