오늘 살펴볼 논문은 “Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling”이다.
논문의 전체적인 내용을 요약하면 다음과 같다.
좀 더 강력한 언어모델로부터 생성한 고품질의 합성 데이터(Synthetic Data)를 이용하여 학습하는 전략은 대중적으로 사용되고 있는 방법이다. 해당 논문에서는 이러한 전략이 정말로 compute-optimal한지 살펴보기 위해서 FLOPS를 한정시켜놓고 다양한 실험을 진행한다. 이를 위해 데이터를 합성할 때, 강력하지만 비싼 모델과 약하지만 싼 모델 간의 Trade-off를 살펴본다. 생성된 데이터는 Coverage, diversity, false and positive rate의 3가지 관점으로 평가한다. 모델의 파인튜닝은 Knowledge Distillation, Self-improvement, weak-to-strong improvement 등 다양한 방법을 적용한다.
사전학습 모델은 다양한 추론 태스크에서 좋은 성능을 보여왔다. 하지만 이러한 성공적인 성능을 내기 위해서는 엄청난 양의 (Problem, Solution) Pair의 데이터셋에 학습하는 과정이 필요하다. 이러한 데이터를 사람을 이용해서 모으는 것은 매우 많은 시간과 돈이 든다. 최근 연구에서는 이러한 데이터를 LM 자체를 이용해서 생성하는 방법을 적용하여 좋은 성과를 거두었다.
주로 LM을 통해서 여러 개의 Solution을 샘플링하고 필터링을 적용하는 방법으로 데이터를 생성한다. 당연하게도 엄청 큰 매개변수를 가지는 Strong 모델로 부터 데이터를 샘플링 했을 때, 더 좋은 성능을 보였다. 하지만 이는 자원, 시간, 비용이 매우 많이 드는 작업이며, 많은 데이터를 생성하기에는 결국 한계가 존재한다.
해당 논문에서는 이러한 방법의 대체 방법으로 한정된 예산 내에서 적절하게 데이터를 샘플링하기 위해서, 대부분의 연구가 SE모델을 이용한 것과 다르게, WC(Weaker but Cheaper) 모델로 데이터를 샘플링하고 학습을 해보았다. SE 모델과 WC 모델의 결과를 비교하기 위해 논문에서는 3가지 지표를 기반으로 평가하였다.
Coverage: Problem을 해결한 Unique 문제의 개수
Diversity: 각 문제마다 Unique한 솔루션을 얼마나 생성하였는지
FPR(False Positive Rate): 맞는 정답에 도달하였지만, 올바르지 못한 Solution을 제시한 비율
해당 실험에서 WC 모델이 같은 시간 내에서 더 많은 솔루션들을 샘플링할 수 있기 때문에 Diversity 측면에서 더 좋은 결과를 보였고, SE 모델이 FPR에서는 더 나은 성능을 보였다.
다음으로 WC와 SE로 부터 샘플링된 모델을 Knowledge Distillation, Self-Improvement, Weak-to-Strong Improvement의 방법을 통해서 파인튜닝한다. Knowledge-Distillation은 Larger, Stronger 모델을 이용해서 더 작은 Student 모델을 학습하는 방법이고, Self-Imrprovement는 모델 자체가 생성한 샘플들을 이용해서 학습한다.
다음은 한정된 예산의 FLOPS에서 샘플링할 데이터의 수를 구하는 수식이다.
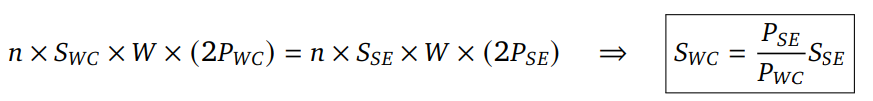
S_wc와 S_se는 각 모델에서 질문당 생성할 데이터의 개수이다. P는 각 모델이 토큰을 추론하기 위해 필요한 FLOP의 수이다. 만약 토큰을 추론하기 위한 FLOP의 수가 2배 차이가 난다면 WC 모델에서는 질문당 2배 더 많은 솔루션을 샘플링할 수 있다.
해당 논문에서 모델의 학습을 위한 셋업은 다음 3가지로 분류할 수 있다.
Student-LM finetuning
일반적으로 파인튜닝 학습은 SE 모델로 부터 생성된 고퀄리티의 감독학습 데이터를 이용하여 Student LMdmf 학습시킨다. 하지만 해당 논문에서는 WC 모델을 이용해서 SE 모델을 대체할 수 있는지를 실험하는 것을 목표로 하고 있기 때문에 SE 모델이나 WC와는 아예 다른 Student LM을 세팅하여 두 가지 모델에 모두 Distillation을 적용한다.
WC-LM finetuning
이전 연구들에 의하면 SE 모델을 이용해서 Distillation을 적용하는 것이, WC 모델을 이용해서 Self-improvement를 적용하는 것보다 더 나은 성능을 보였다. WC 모델을 이용하여 self-generated 된 하지만 이러한 셋업은 데이터 샘플링을 위해 많은 예산(FLOPS)를 필요로 한다. 이번 연구에서는 고정된 FLOPS 내에서 SE 모델로 WC 모델을 Distillation 했을 때의 성능과 WC모델을 이용해서 self-improvement를 적용했을 때의 성능을 비교한다.
SE-LM finetuning
일반적으로 이러한 학습 방법은 Student 모델이 스스로 생성한 데이터로 학습하거나(Self-Improvement), 더 큰 모델이 생성한 데이터로 Student 모델을 학습(Distillation)하는 것이 일반적이다. 하지만 해당 논문에서는 고정된 FLOPS 내에서 더 작은 모델인 WC 모델로 생성한 데이터로 SE 모델을 학습하는 Weak-to-Strong 학습 방법을 추가로 적용해보았다. 그리고 이 방법을 SE 모델에서 생성한 데이터로 SE 모델을 학습하는 Self-Improvement 방법의 성능과 비교한다.

Data Generation
모델을 파인튜닝 시키기 위한 Synthetic Data를 생성할 WC와 SE 모델은 각각 Gemma-2의 9b, 27b 모델을 적용하였다. 각 Synthetic 데이터는 MATH 데이터에 4-shot, GSM-8K 데이터에 8-shot 프롬프트를 적용해서 생성하도록 하였다. 9b 모델은 27b 모델보다 대략적으로 약 3배의 FLOPS 차이를 가지기 때문에, 각 데이터마다 대략적으로 3배의 데이터를 생성할 수 있다. 실험은 Low-Budget 세팅과 High-Budget 세팅의 2가지로 나누어서 진행하였는데, Low-Budget에서는 9b, 27b 모델에서 각각 데이터당 3개, 1개의 데이터를 합성하도록 하였고, High-Budget에서는 각각 30개, 10개의 데이터를 합성하도록 하였다.
Model Finetuning
모델 Finetuning을 위한 Student-LM 모델로는 Gemma-7B 모델을 활용하였다.
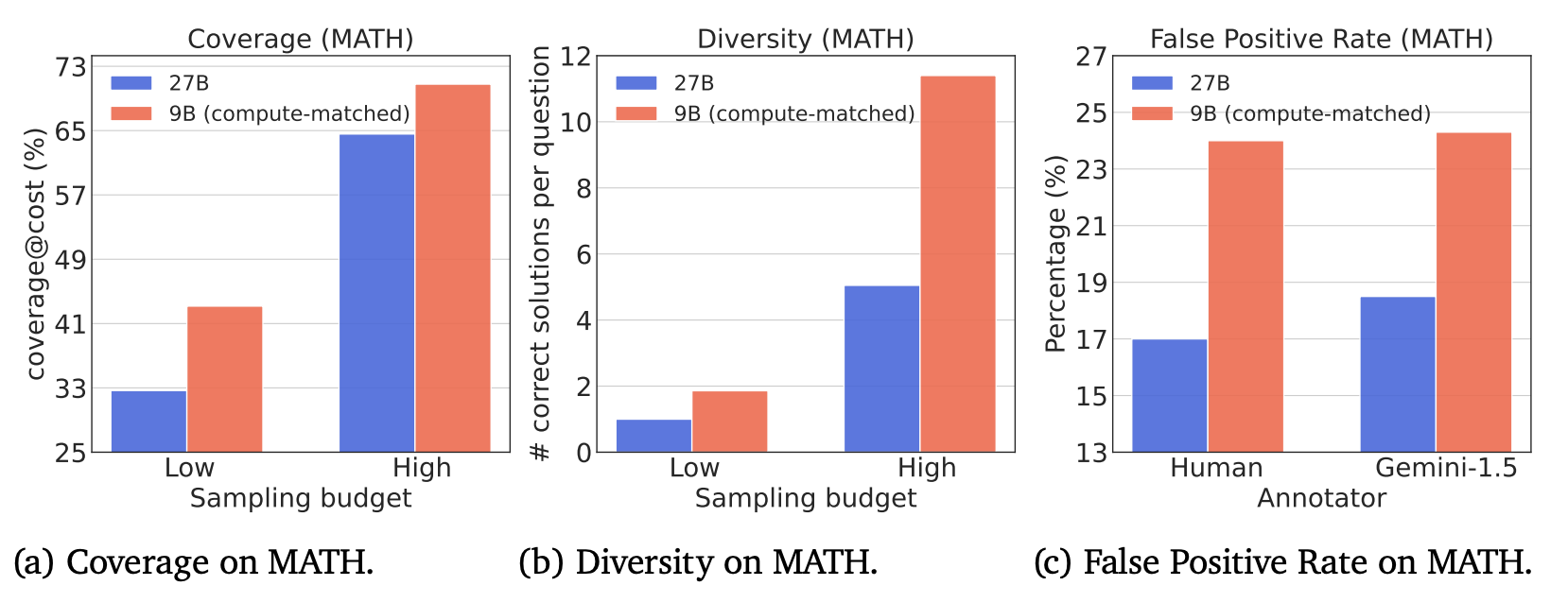
그림 1. 합성된 데이터의 퀄리티 평가
위의 그림은 WC와 SE 모델에서 생성된 합성 데이터의 3가지 지표에서의 평가 결과를 나타낸다. WC와 SE 모델에서 생성된 데이터 간의 퀄리티 차이를 대략적으로 비교할 수 있다. Coverage와 Diversity에서는 샘플당 더 많은 데이터를 생성할 수 있는 9b의 성능이 더 좋게 측정되었지만, 아무래도 답변 퀄리티가 떨어질 수 밖에 없기 때문에 FPR은 27b 모델이 더 낮게 측정되어 더 좋은 성능을 보인 것을 확인할 수 있다.
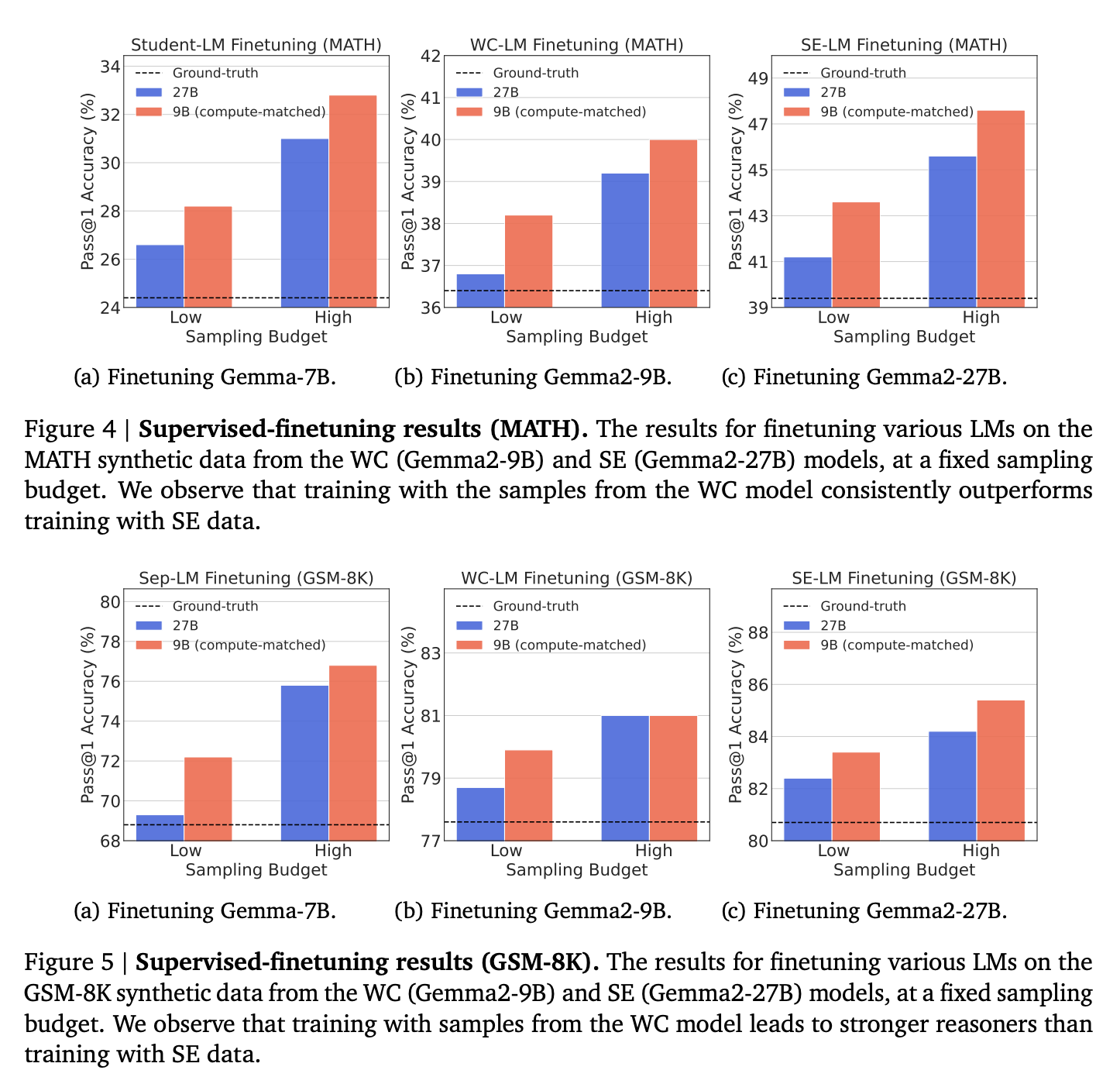
위의 결과를 살펴보면, 일반적으로 더 큰 모델(SE)을 이용해서 고품질의 데이터를 합성해서 Distillation을 하는 방법을 대부분 적용해왔지만, FLOPS를 고정시켜놓고 두 방법을 비교했을 때는 오히려 WC 모델에서 합성된 데이터로 학습했을 때의 성능이 더 높은 것을 확인할 수 있다. 다만 GSM-8K에서는 두 데이터로 학습된 모델 간의 성능 차이가 더 작아진 것을 확인할 수 있는데, 이는 비교적 난이도가 더 높은 태스크에서는 FPR이 더 낮은 모델의 데이터가 좀 더 효과적인 것을 확인할 수 있다.
심지어 더 낮은 크기의 모델인 9b의 모델에서 합성된 데이터로 27B 모델을 학습했을 때도, Self-Improvement를 적용한 모델보다 더 높은 정확도를 보이는 것을 확인할 수 있다.
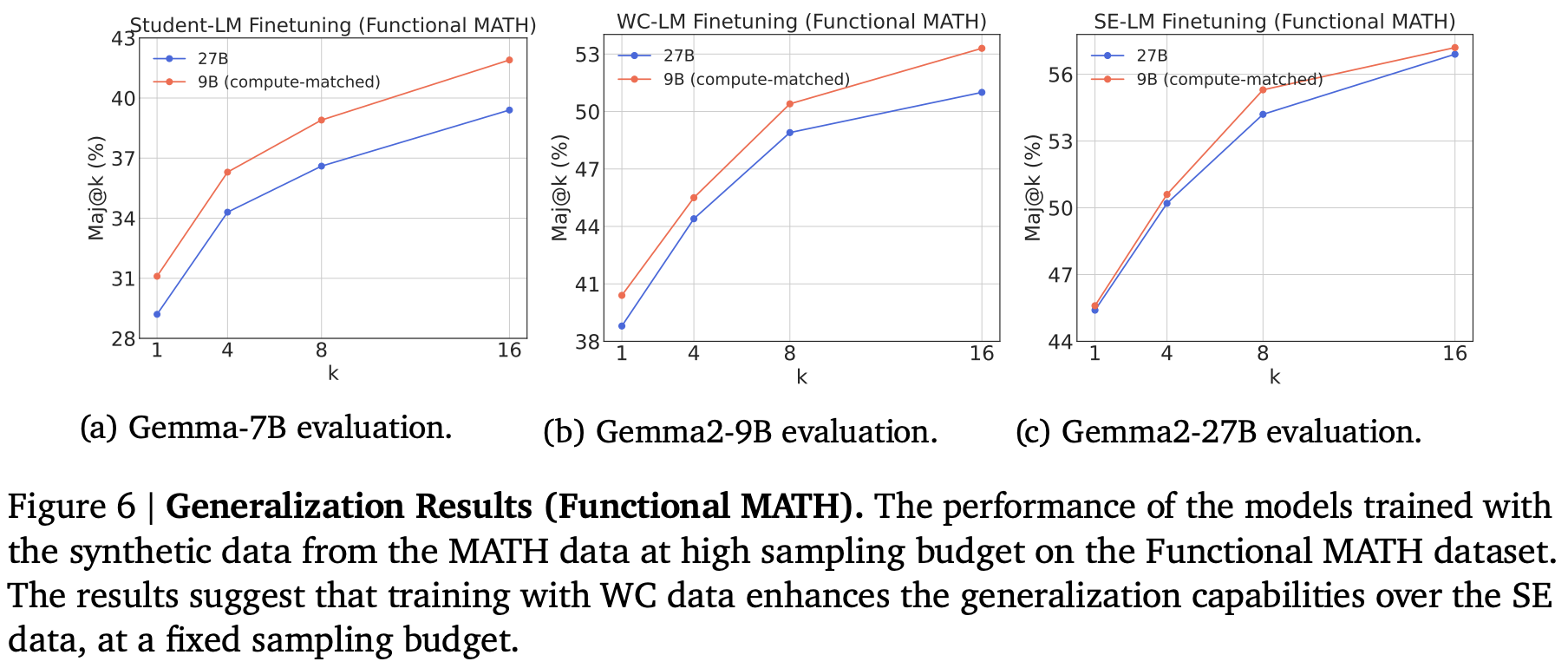
위의 그림은 WC와 SE 모델로 데이터를 합성했을 때의 모델 일반화 성능을 비교하기 위한 실험 결과이다. MATH 데이터셋을 이용하여 합성된 데이터셋을 학습에 적용하고, Functional MATH 데이터셋에서 평가하였다. 한정된 예산에서 WC 모델을 데이터 합성에 적용했을 때, 모델의 일반화 성능에서도 더 좋은 결과를 보이는 것을 확인할 수 있다.
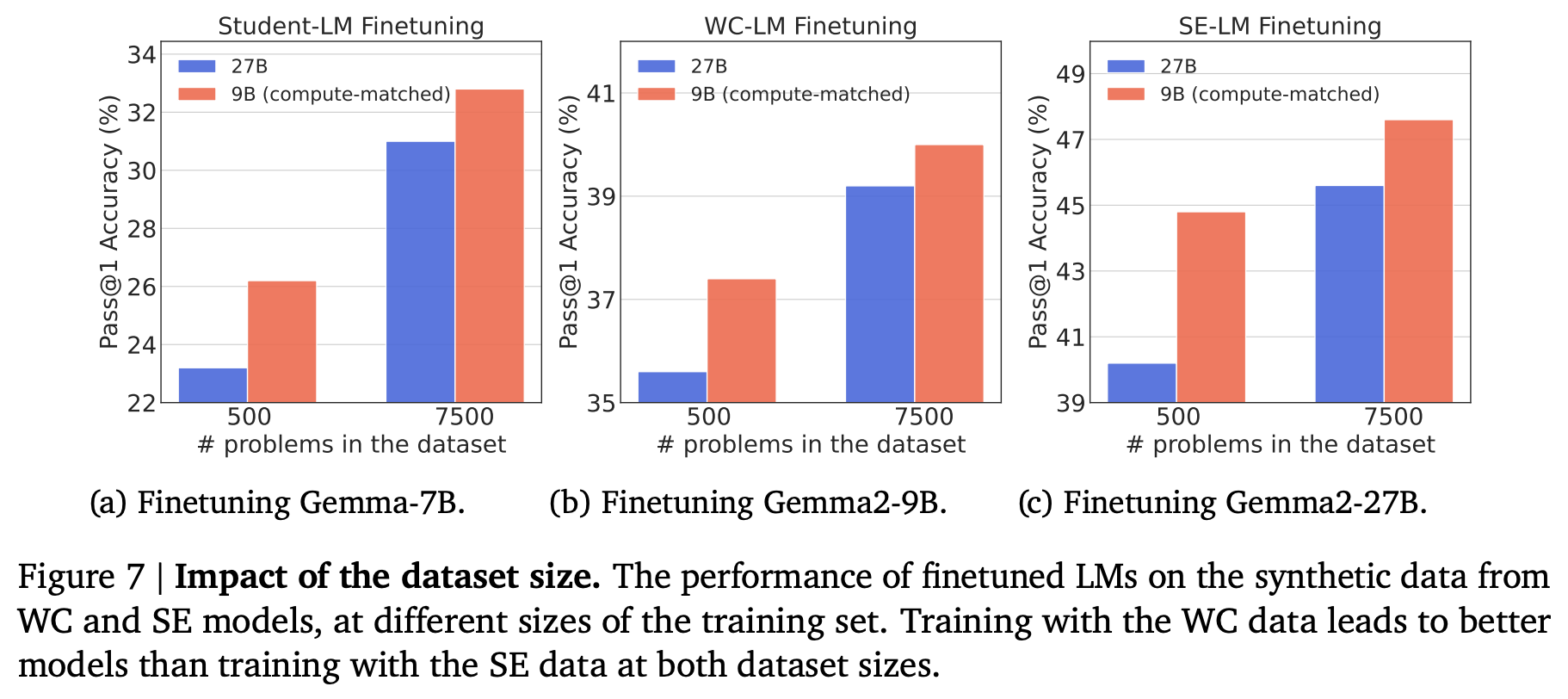
위의 그림은 학습에 적용되는 데이터셋의 크기를 달리 했을 때의 성능 차이를 보여준다. 일반적으로 더 적은 수의 데이터를 학습에 사용할 때 훨씬 더 큰 성능 차이를 보이는 것을 확인할 수 있다.
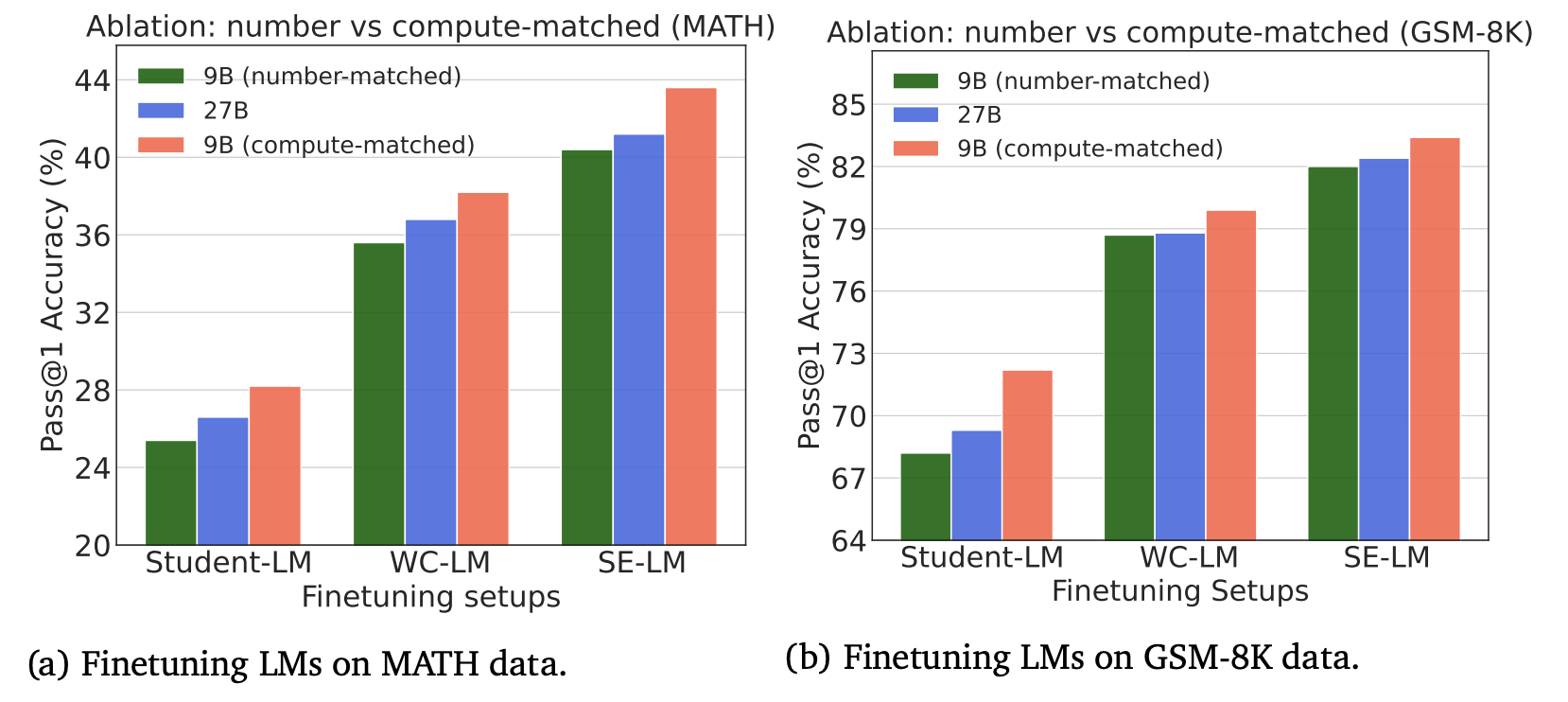
대부분의 이전 연구들이 SE 모델을 이용해서 데이터를 합성하는 방식을 더 선호했던 이유는 WC 모델과 SE 모델의 컴퓨팅 차이를 고려하지 않고 같은 개수의 데이터를 합성하여 학습에 적용하였기 때문일 것 이다. 실제로 컴퓨팅 차이를 고려하지 않고 똑같은 수의 데이터를 생성하였을 때, SE 모델에서 더 나은 성능을 보이는지 확인하기 위해 다음과 같이 SE 모델과 같은 수의 데이터를 WC 모델을 이용해서 생성하도록 하고 학습한 모델의 결과를 추가하였다.
해당 논문의 실험 결과를 통해 High Coverage, High Diversity를 가지는 WC 모델의 데이터셋이 학습된 모델의 성능에 더 긍정적인 영향을 미치는 것을 확인할 수 있었다. 그렇다면 High Coverage와 High Diversity는 구체적으로 어떻게 성능에 영향을 주는걸까? 아래의 그림은 해당 물음에 답하기 위해 Ablation을 진행한 결과이다.
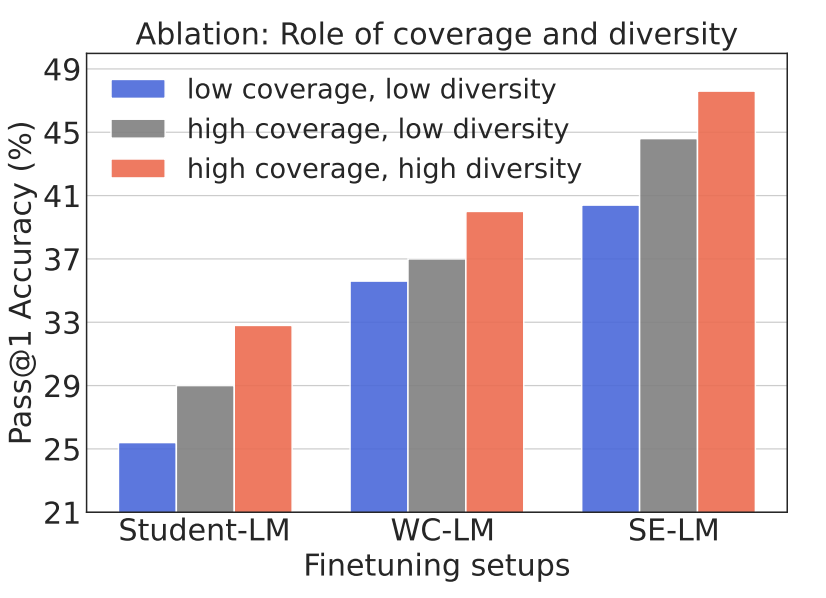
High Coverage, High diversity 데이터셋은 데이터당 30개의 데이터를 샘플링하여 만든 데이터셋이다. High Coverage, Low Diversity 데이터셋은 데이터당 하나의 맞는 데이터셋만을 선택하여 만든 데이터셋이다. Low Coverage, Low Diversity는 한 데이터당 하나의 데이터만을 샘플링하여 만든 데이터셋이다.
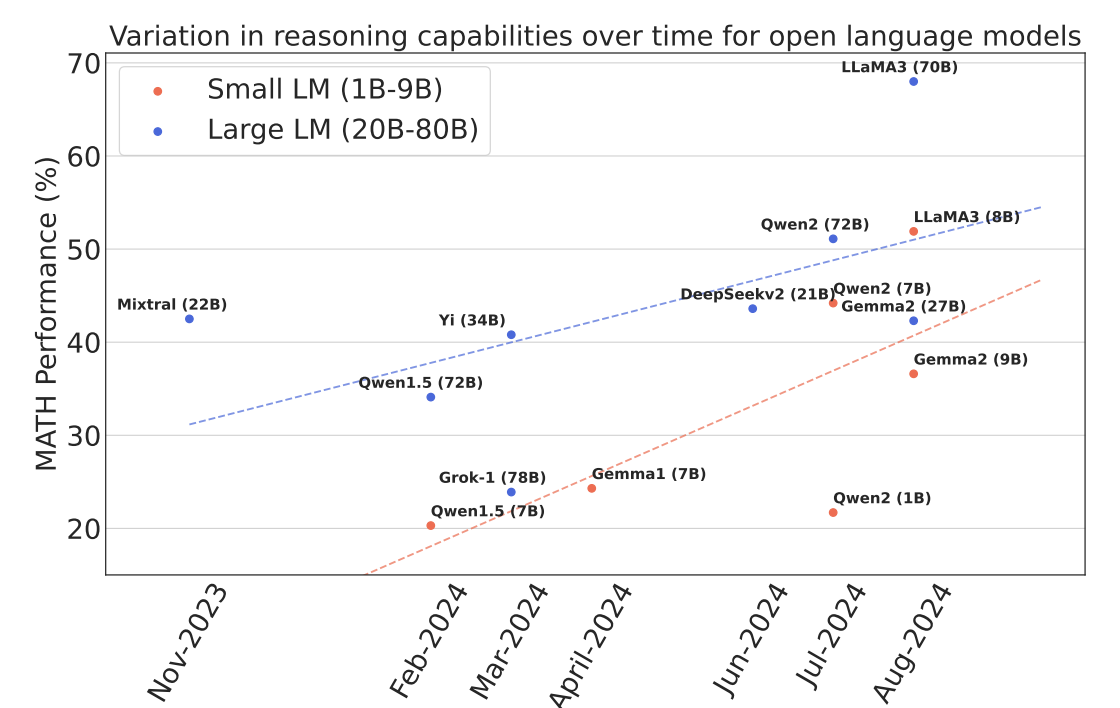
다음은 모델의 공개된 시간에 따른 MATH 데이터에서의 성능 변화가 시간대별로 어떻게 변화하고 있는지를 모델의 크기를 두 그룹으로 나누어서 비교한 결과이다. 비록 절대적인 성능은 Lage LM 그룹이 더 높지만, 성능이 증가하는 속도는 Small LM 그룹이 더 빠르다. 이는 앞으로도 WC 모델을 이용한 데이터 합성 방법이 더 Compute-Optimal하게 갈 것이라는 것을 간접적으로 보여준다.
이번 논문에서는 컴퓨팅 예산을 완전히 고정시켜놓았을 때, SE(더 강력하고 비싼 모델), WC(더 약하지만, 싼 모델)을 이용해서 데이터를 합성하도록 했을 때 학습된 모델의 성능이 어떻게 차이가 나는지를 비교하는 실험을 진행했다. 일반적으로 모델을 이용해서 데이터를 합성하여 학습에 적용할 때는 너무도 당연하게도 더 큰 모델에서 합성된 데이터를 더 작은 모델을 이용해서 학습시키려고 하는게 일반적이다. 하지만 이번 논문에서는 그러한 틀을 깨고, 같은 컴퓨팅 자원이 있다고 했을 때는 차라리 더 싼 모델을 이용해서 더 많은 데이터를 샘플링하여 데이터를 합성하는 것이 오히려 더 Compute-Optimal 하다는 것을 실험을 통해서 보여주었다. 특히, 오히려 더 작은 모델에서 합성된 데이터로 더 큰 모델을 학습하는 Weak-to-Strong 방식으로 데이터를 학습했을 때도 더 Compute-Optimal한 WC 모델을 이용한 학습 방법이 더 좋은 결과를 보였다.
큰 모델을 도저히 돌릴 환경이 안되거나, 합성할 수 있는 데이터셋의 수가 적을 때는 차라리 더 큰 모델을 돌릴려고 다른 방법을 찾아보기 보다는 WC 모델을 이용하는 것도 하나의 방법이 될 수 있을 것 같다.