오늘 살펴볼 논문은 “RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval”이다.
해당 논문은 매우 긴 컨텍스트에서 LLM을 실행할 때 필요한 Latency를 최소화하기 위한 Attention 방법이다.
KV Cache를 통해서 어텐션을 계산할 때, 새로운 토큰이 생성되면 생성된 토큰의 Query와 나머지 토큰들의 Key간에 어텐션을 구하기 위해서 벡터를 내적하게 된다.
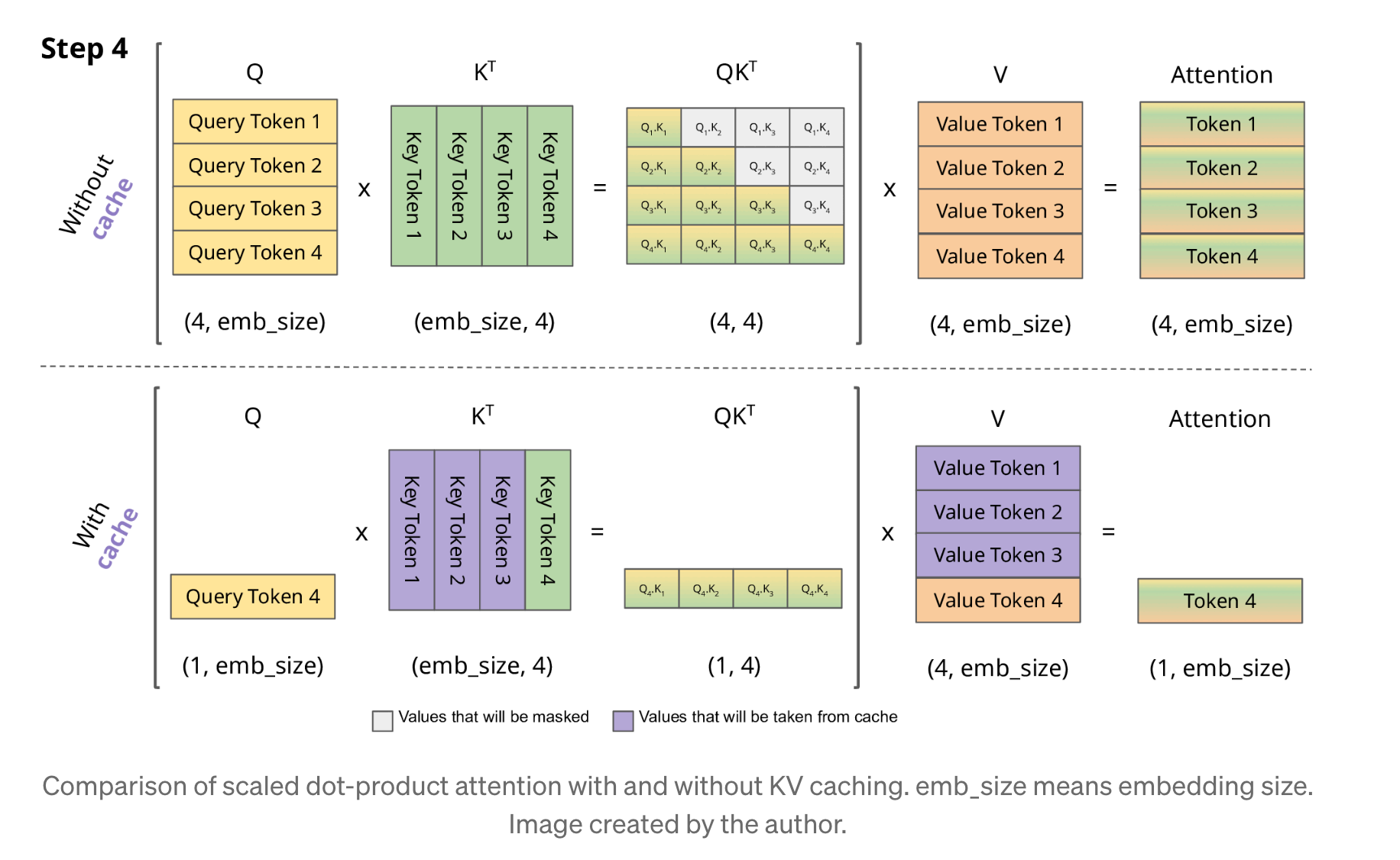
그림 1. KV Cache 적용 예시
만약에 입력 컨텍스트 토큰의 길이가 10만, 20만과 같이 매우 길다면 엄청나게 많은 메모리와 처리 시간이 필요할 것이다.
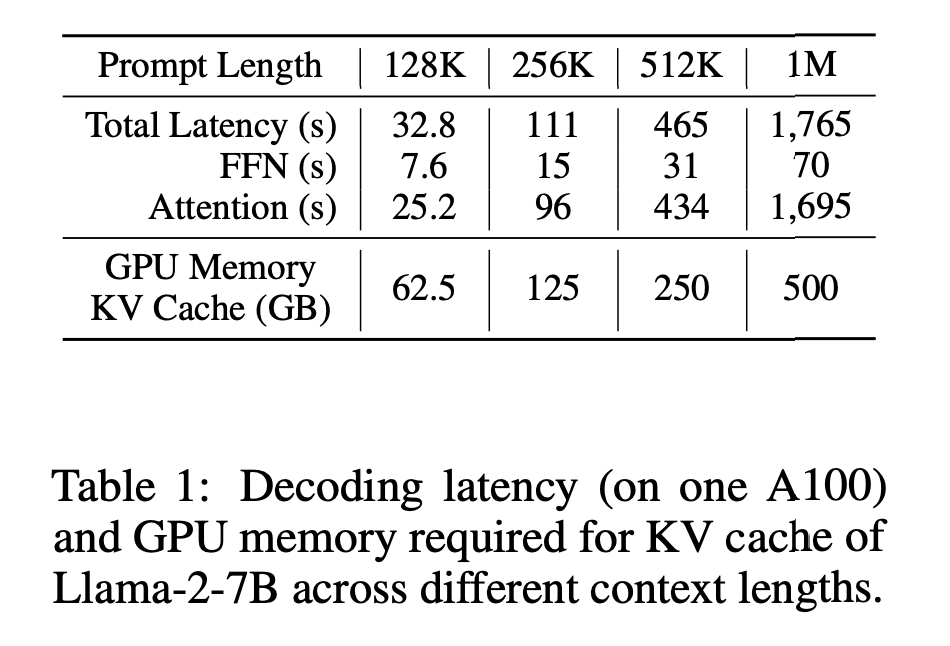
그림 2. A100에서 컨테스트 길이에 따른 필요한 메모리 및 연산 시간
위의 그림은 A100 GPU에서 LLamma 모델을 실행시켰을 때 필요한 메모리와 Latency를 보여준다. FFN에 필요한 연산은 프롬프트 길이가 2배로 증가할 때 마다 똑같이 2배로 증가하지만, Attention에 필요한 연산 시간은 4배씩 증가하면서 기하급수적으로 증가하는 것을 확인할 수 있다.
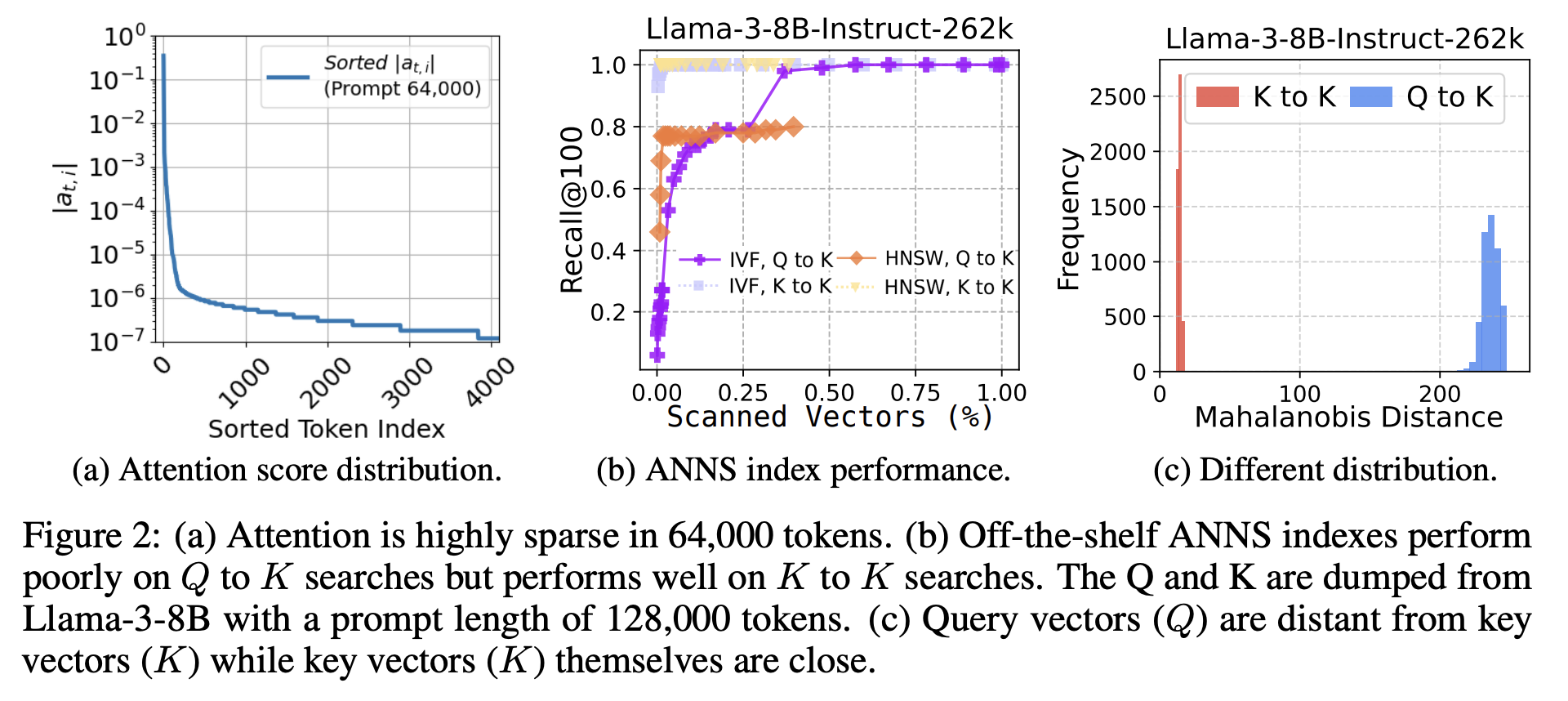
그림 3. Retrieval Attention을 위한 사전 실험 결과
위의 그림은 해당 논문에서 제안하는 Retrieval Attention의 구현 가능성을 살펴보기 위한 다양한 사전 실험을 진행한 결과이다. 첫 번째 그림은 Attention Score 분포를 구했을 때, 얼마나 Sparsity한지를 나타내는 것이다. 예를 들어 컨텍스트 길이가 3만 토큰이라고 한다면, Attention Score로 활성화되는 토큰이 1~2천개씩 될 것 같지만 Attention Score는 매우 Sparsity하기 때문에 실제로 활성화 되는 토큰의 수는 그리 많지 않다는 것이다. Retrieval Attetnion은 바로 해당 현상으로부터 출발한 방법이라고 볼 수 있다.
- 어차피 Attention Score는 Sparse하기 때문에 Query 토큰과 Key 토큰간의 어텐션을 구할 때, 모든 Key 토큰과 연산할 필요 없이 가장 가까운 K개의 토큰만 선별해서 Attention을 구해도 큰 차이가 없을 것이다.
- ANNS index 기법을 이용하면 모든 컨텍스트 토큰과 일일히 비교를 할 필요없이 K개의 가장 가까운 토큰을 추정하여 뽑아낼 수 있을 것이다.
하지만 2번의 가정에서 가장 문제되는 부분이 있는데, 그건 바로Query의 분포와 Key의 분포 간의 차이에서 생기는 OOD(Out-of-Distribution) 문제이다. 위의 그림에서 (b)를 살펴보면 같은 분포를 가지는 K to K 연산을 통해서 ANNS index를 실행하면 2~3%의 매우 적은 수의 토큰만 스캔하더라도 Recall 1.0에 가까운 성능을 낼 수 있다. 하지만 Q to K와 같이 서로 분포가 다른 벡터를 ANNS index를 적용하여 K개의 가까운 토큰을 찾으려고 하는 경우, Recall이 1.0에 가까워지려면 거의 30%가 넘는 토큰을 모두 스캔해야 한다.
위의 그림에서 (c)는 Q to Q와 Q to K의 분포 차이가 얼마나 심한지를 비교하는 그림이다.
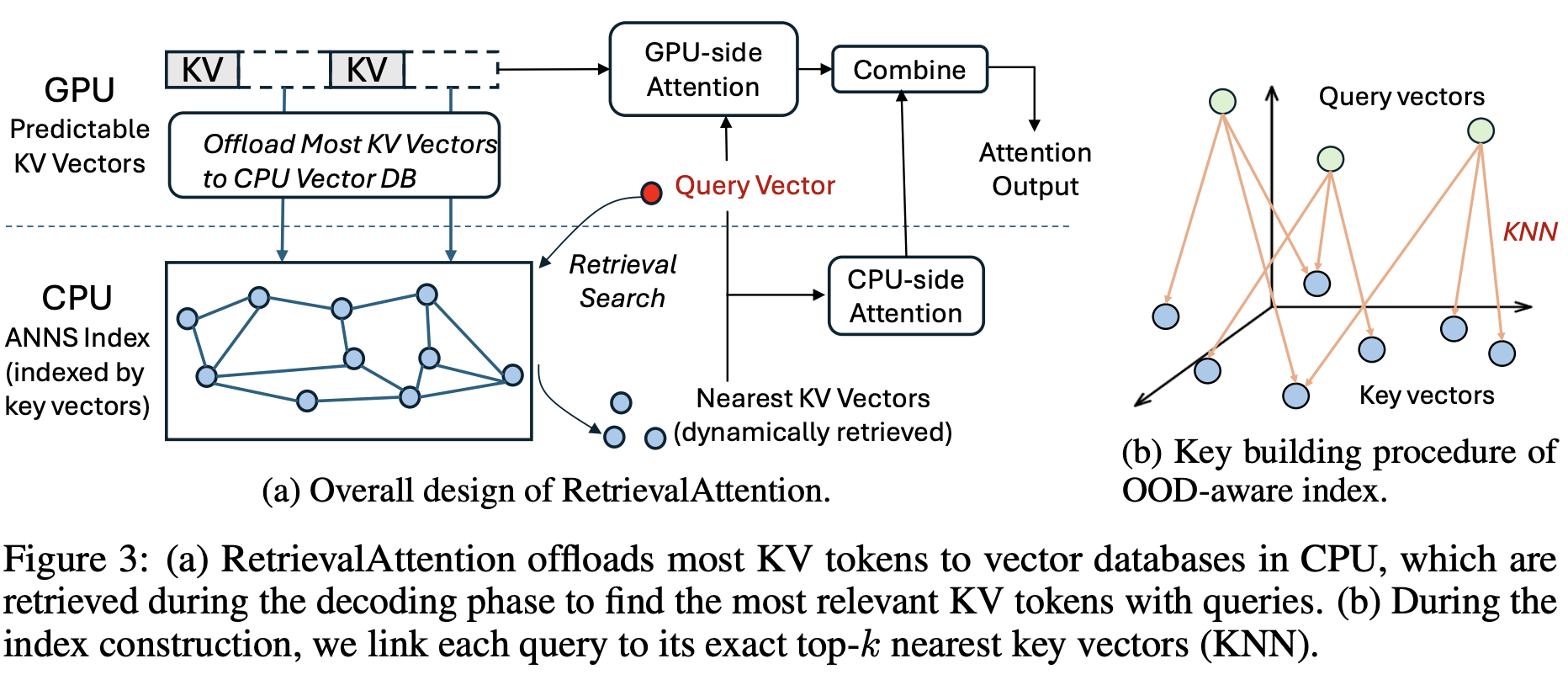
그림 4. Retrieval Attention 방법의 구조
그렇다면 이러한 문제를 어떻게 해결해야할까? 위의 그림은 이러한 문제를 해결하고 가장 가까운 K개의 Key를 선별해서 Attention을 적용하기 위한 Retrieval Attention의 전체적인 구조 및 방법을 나타낸다.
우선 KV 벡터들은 ANNS Index를 실행하기 위해서 GPU 메모리에서 CPU 메모리로 Offload 한다. Query와 Key 벡터 간의 Nearest Vector를 찾고 CPU-side Attetnion을 계산해서 해당 결과를 다시 GPU에서 결합하게 된다.
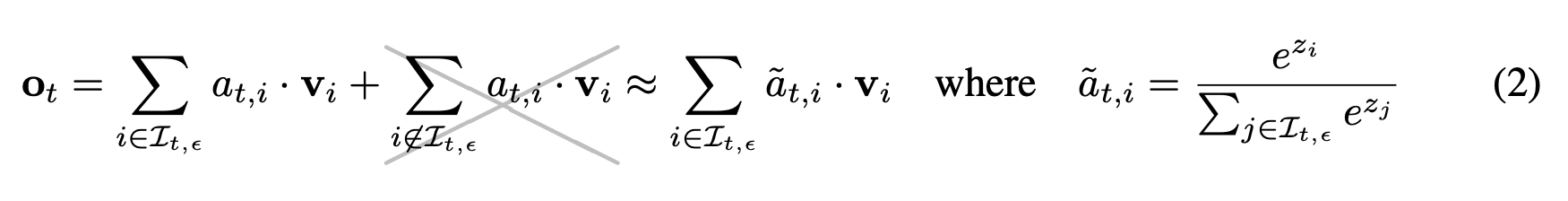
그림 5. Retrieval Attetnion의 수식
위의 수식을 보면 전체 벡터를 대상으로 Attetnion을 적용해서 Vector를 곱하여 최종 결과를 내는 것이 아닌, Retrieval 단계에서 선택된 Nearest KV Vector의 토큰들을 대상으로 어텐션을 계산하고 Vector를 곱하여 최종 값을 얻게 된다.
그렇다면 OOD 문제는 어떻게 해결했을까? 먼저 계산되는 Prefill 단계에서 Full Attention을 실행해보면 Key의 어떤 벡터와 Query의 어떤 벡터가 서로 연결되는지 알 수 있다. 그림 4에서 (b)를 살펴보면 다음과 같이 서로 연결되는 Key와 Query를 연결시켜서 분포의 차이를 구하고 이를 반영하여 OOD 문제를 보정하여 ANNS index를 수행하게 된다. ANNS index 방법은 ”
RoarGraph: A Projected Bipartite Graph for Efficient Cross-Modal Approximate Nearest Neighbor Search“에서 제안된 Cross-Modal ANNS index 방법을 사용하였다.
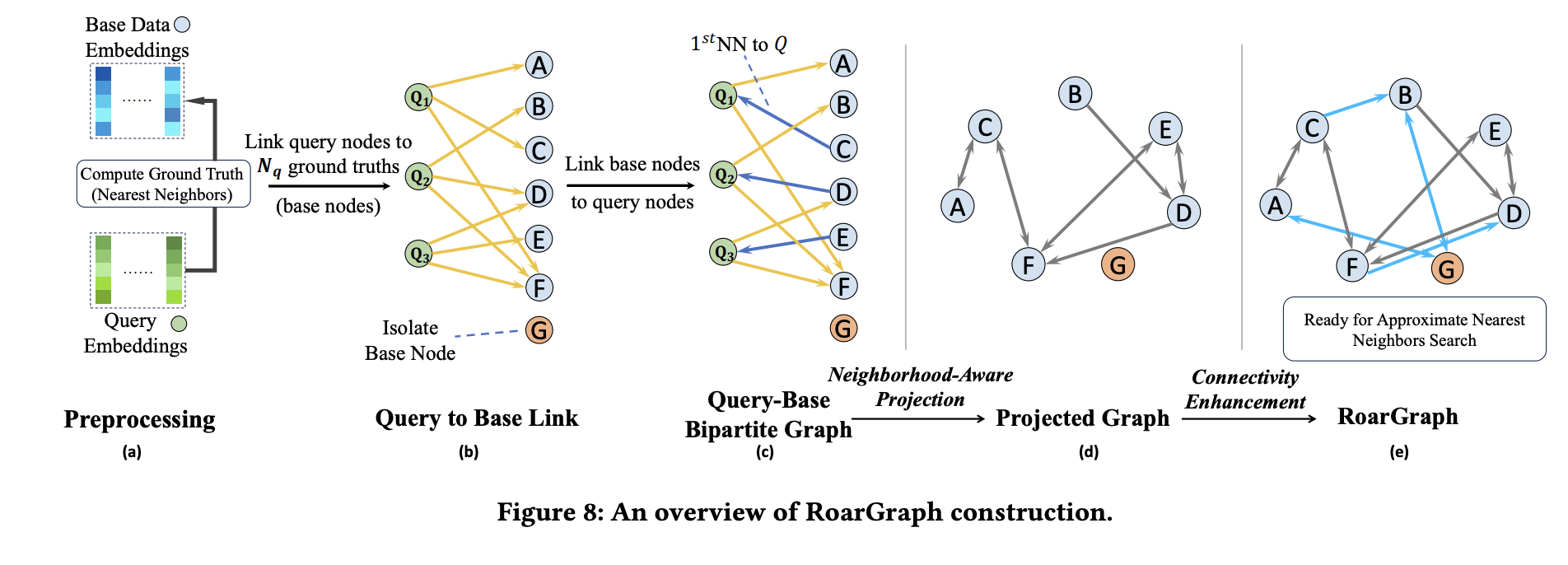
그림 6. Cross-M0dal ANNS index 방법의 구조
위의 그림은 해당 논문의 ANNS index 방법을 나타내는데, 먼저 Query to Base Link를 통해서 서로 연결되는 노드들을 구한다. 그리고 해당 노드들의 분포 차이를 Projection 하도록 하여 분포의 차이를 보정하고 ANNS index를 수행하는 방식이다.
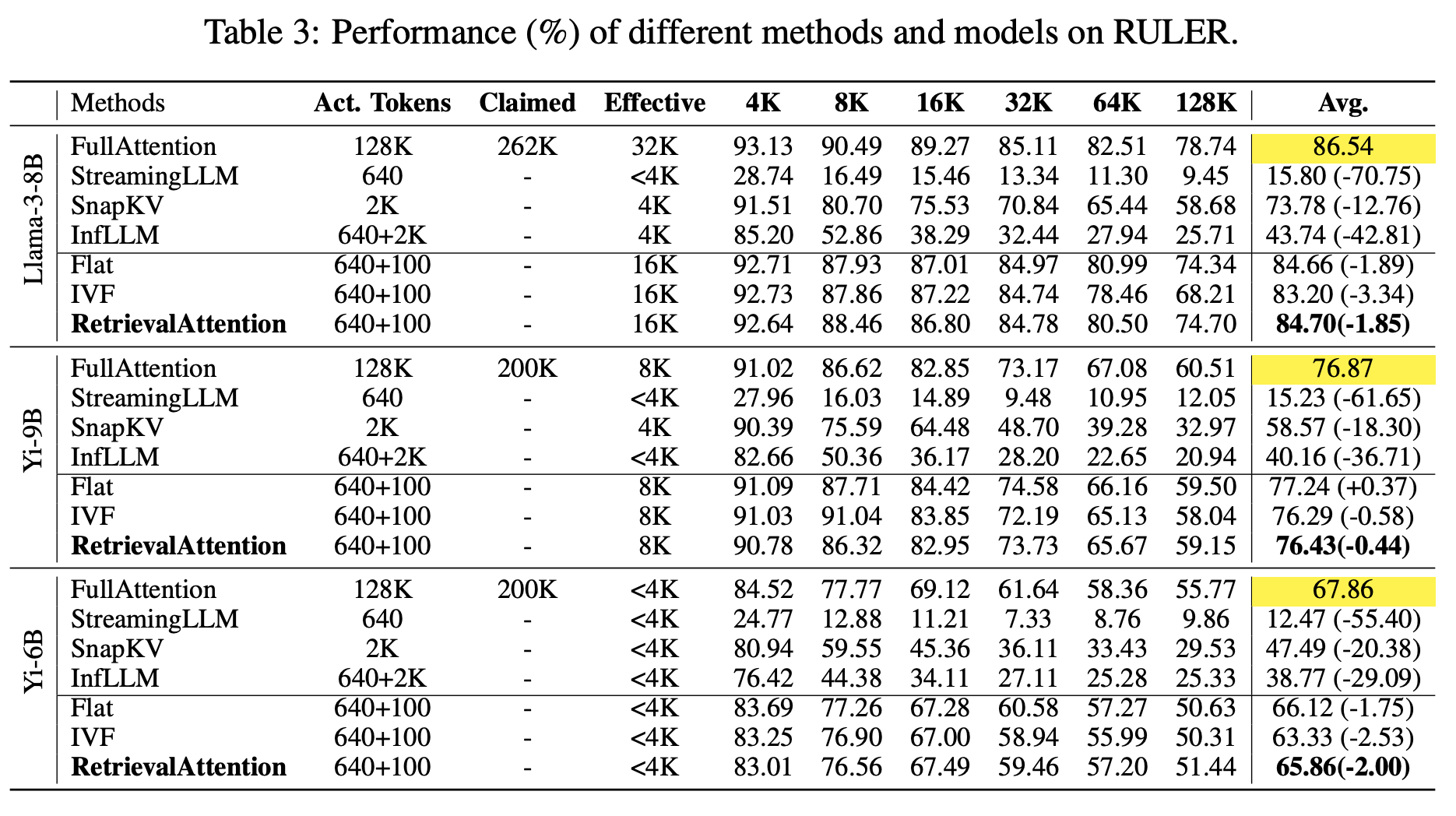
그림 7. Retrieva Attention 방법의 성능 비교
위의 그림은 제안된 어텐션 방법과 다른 방법들의 성능 비교를 나타낸 것이다. 확실히 Long Context를 위한 다른 모델들과 비교하여 성능 감소가 훨씬 작은 것을 확인할 수 있다. 태스크에 따라 조금씩 다르긴 하지만 1~2% 정도의 성능 감소만 발생하는 것을 볼 수 있다. 128K의 긴 컨텍스트에서는 확실히 성능 감소의 폭이 조금 더 커지긴 하지만, 컨텍스트가 2배씩 증가할 때 마다 Latency가 4배씩 커지는 것을 생각하면, 조금의 성능 감소를 감수하면 훨씬 더 효율적이고 빠르게 LLM Inference를 수행할 수 있다.