오늘 살펴볼 논문은 RAG Cahe라는 논문이다.
KV Cache는 토큰을 하나씩 생성하면서 이전 생성 단계에서 연산했던 Key와 Value를 Cache에 저장하여 중복 연산을 방지함으로써 실행 시간을 크게 개선할 수 있었다.
RAG Cache는 이러한 Cache 기법을 RAG(Retrieval Augmented Generation) 시스템의 관점에서 적용한 방법이다.
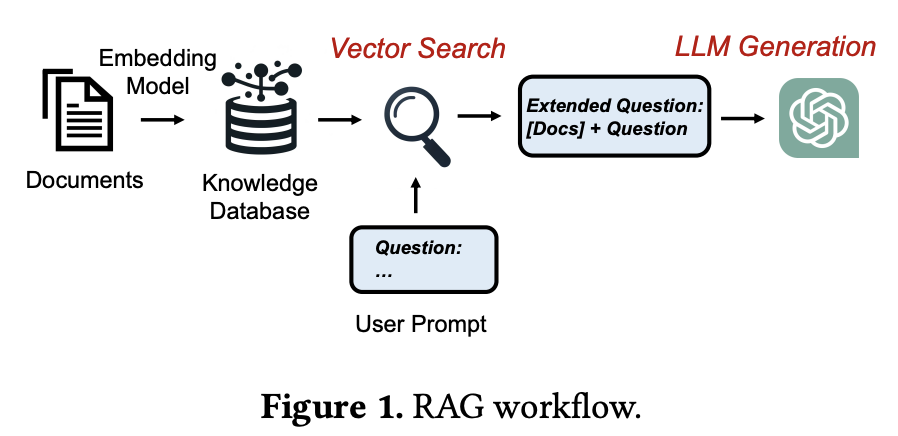
그림 1. RAG의 실행 과정
RAG에서는 Retrieval 과정을 거쳐서 Knowledge Database에서 답변에 도움이 될 문서들을 탐색하고, 탐색된 문서들을 프롬프트에 추가하여 답변을 생성한다.
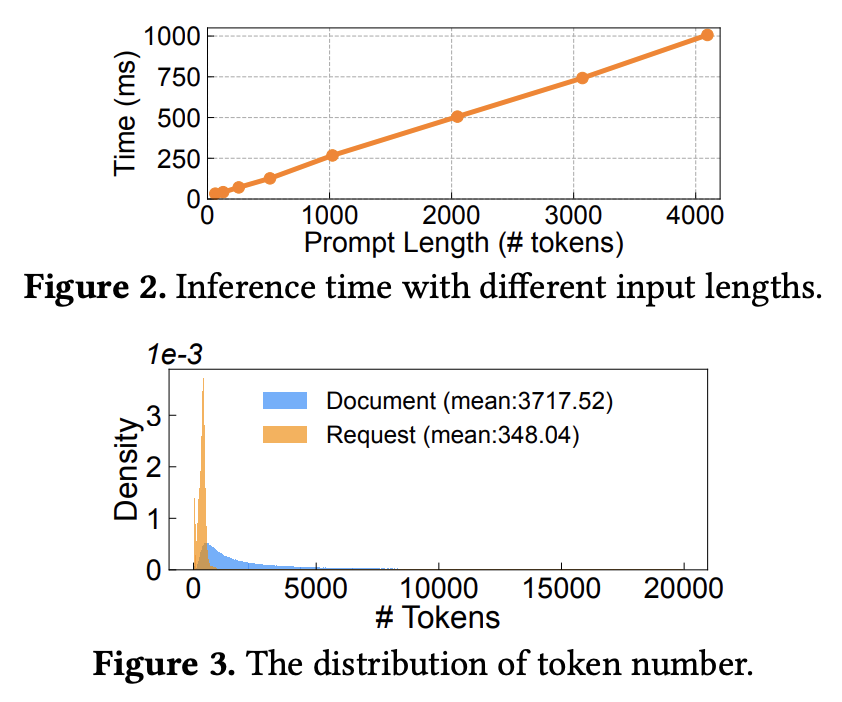
그림 2. 입력의 길이에 따른 Inference 시간 및 사용자 요청의 토큰 길이와 탐색된 문서의 토큰 길이 분포 비교
만약 사용자의 질문의 토큰 길이가 100이라고 가정하고, 탐색된 문서의 토큰 길이가 1000이라고 가정한다면 프롬프트를 처리하는 Prefill 연산에서는 컨택스트 문서들을 처리하는데에 대부분의 컴퓨팅 시간이 사용될 것이다. 하지만 이러한 컨택스트의 연산을 한번 할 때 저장해두고, 재사용할 수 있다면 엄청나게 많은 실행 시간을 절약할 수 있지 않을까? RAG Cache는 이러한 아이디에서 시작하였다.
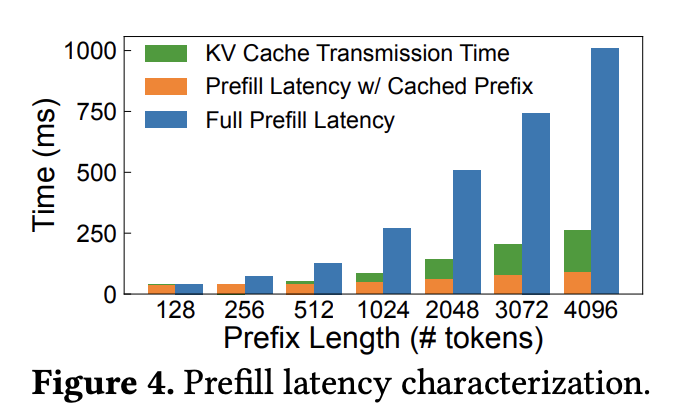
그림 3. 모든 연산을 처음부터 수행하는 것과 Cache에 저장된 값들을 전송하여 수행하는 것의 처리 시간 비교
그렇다면 한 가지 의문이 들 수 있는 것은 모델의 크기가 커짐에 따라 저장해야 하는 States의 크기도 매우 커지게 되고, 수십 기가바이트의 데이터를 실시간으로 올렸다 내렸다 한다면 그것만으로 오버헤드가 발생하지 않을까? 라고 생각할 수 있다. 위의 그림은 처음부터 연산을 하는 Recomputation에서의 연산 시간과 Cache를 적용했을 때 메모리 전송 시간과 나머지 처리 시간을 합한 것의 비교를 보여준다. Cache를 이용하면 실시간으로 수십 기가바이트의 데이터를 전송해야함에도 처음부터 연산을 다시 수행하는 것 보다는 훨씬 빠르게 수행되는 것을 확인할 수 있다.
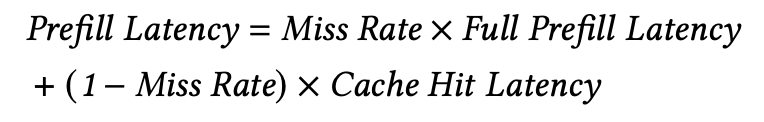
Prefill 연산에 필요한 Latency는 Hit Rate가 크고, Miss Rate가 작아야만 훨씬 줄어들 수 있다. 예를 들면, Cache에 적용이 필요한 Prefix States가 매번 없어서 매번 다시 연산을 수행해야 한다면 속도가 개선되기는 커녕 오히려 RAG Cache를 구현하면서 추가된 기능들 때문에 괜히 속도가 더 느려질 것이다. 그렇기에 자주 사용되고 꼭 필요한 도큐먼트의 States를 Cache에 최대한 상주시키는 것이 RAG Cache의 효과를 최대화하는데에 핵심적인 부분이라고 할 수 있다.
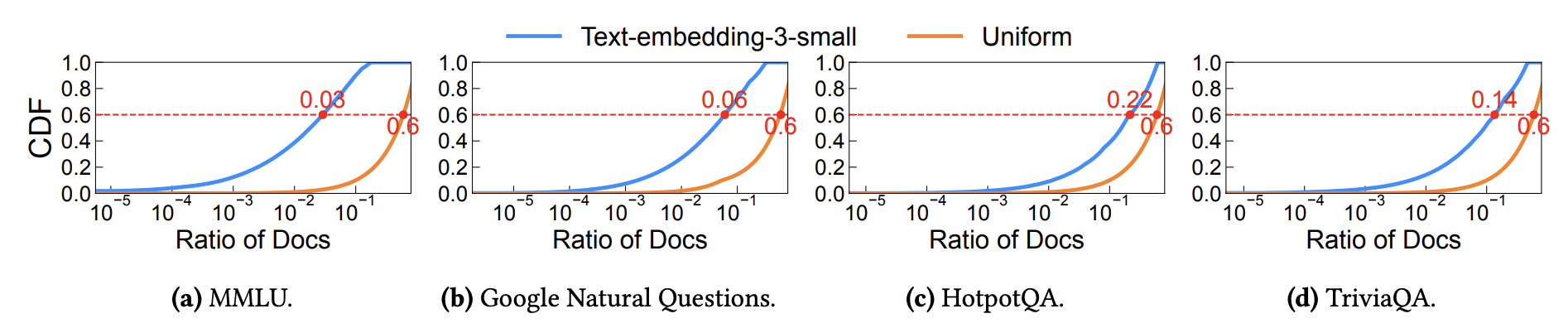
그림 3. 적용된 데이터셋별 CDF 측정 결과
그렇다면 RAG Cache를 통해서 어느정도의 성능 개선을 기대할 수 있는걸까? 정말 RAG Cache를 잘 구현해두었더라도 각 요청이 매번 다른 컨텍스트를 필요로 하면 효용이 거의 없는게 되는게 아닐까? RAG에서 임베딩 벡터를 이용해서 Retrieval을 해보면 어느정도 자주 등장하는 문서들이 다른 질문에서도 자주 유사도가 높은 문서로 계속 등장하는 것을 볼 수 있다. 그래서 해당 논문에서는 이러한 부분을 테스트 해보기 위해서, 4가지의 OpenDomain Questions Answering 데이터셋을 이용해서 CDF를 측정해보았다. MMLU를 살펴보면 0.03 CDF에서 Ratio of Docs가 0.6인 것을 확인할 수 있는데, 가장 많이 호출되는 3%의 문서는 약 60%의 질문에서 호출되고 있는 것을 확인할 수 있다. 이는 RAG Cache가 잘 구현된다면 연산량을 많이 아낄 수 있음을 보여준다.
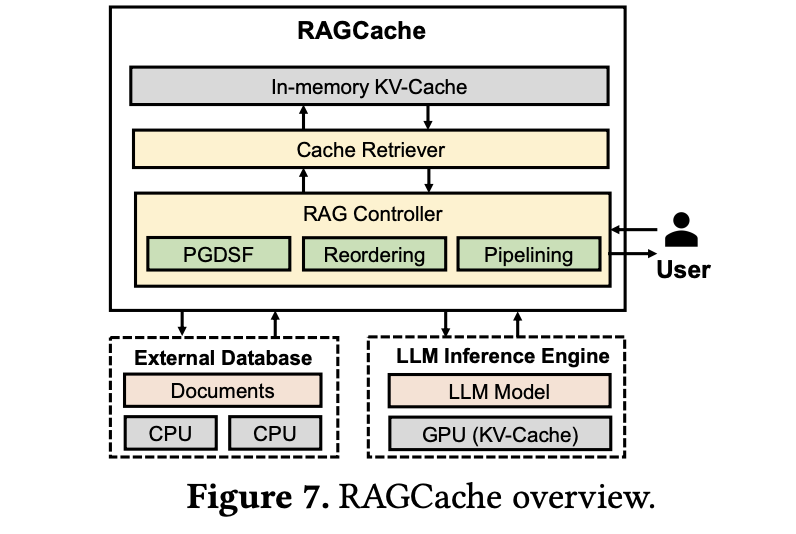
그림 4. RAG Cache 전체적인 구조
RAG Cache가 어떻게 구현되었는지 하나씩 살펴보자.
Cache에서는 Replacement 기법이 제일 핵심적이라고 할 수 있다. Cache 메모리에 자주 사용되는 프로세스가 오래 상주하고 있어야만 메인 메모리를 거치지 않고 Cache에서 빠르게 엑세스하여 이득을 볼 수 있기 때문이다.
해당 논문에서는 Prefix-aware Greedy-Dual-Size-Frequency (PGDSF) replacement policy가 적용되었다. 만약 D1, D2, D3의 3개의 추출된 문서들이 있다고 가정해보자. 이때, D1 => D3 순으로 입력된 컨택스트가 하나, D2 => D3 순으로 입력된 컨택스트가 하나 있다고 해보자. D3가 두번 반복해서 사용되었지만, D3는 앞에 입력된 내용이 달라짐에 따라서 똑같은 D3이더라도 내용이 달라지기 때문에 Cache를 적용할 수 없다. 하지만 D1 => D2, D1 => D3라면 어떨까? D1이 앞에서 반복해서 사용되고 있기 때문에 D1을 Cache에 저장해서 재사용하는 것이 가능하다. PGDSF는 이러한 입력의 순서에 따라서 Cache를 재사용할 수 있는것이 달라지는 것을 반영한 Replacement 방법이다.
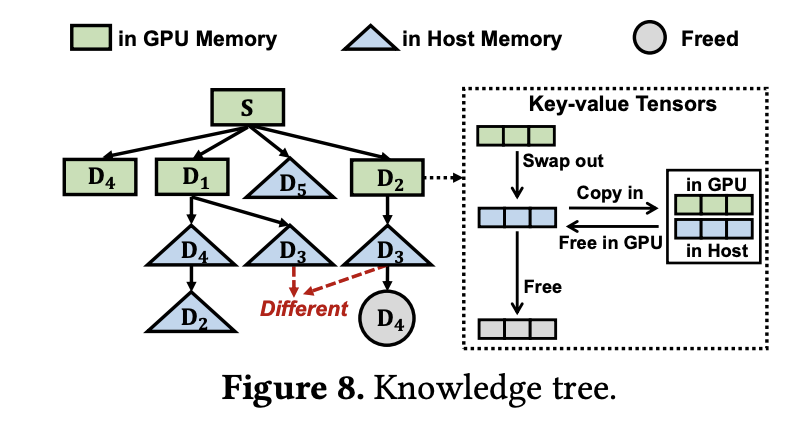
그림 5. Knowledge Tree의 구조
위의 그림에서 트리의 루트 노드인 S는 공통적으로 계속 사용되는 시스템 프롬프트의 States를 나타낸다. 순서상 Parent 위치에 있는 자주 호출될 확률이 높은 Cache들은 전송속도가 훨씬 빠른 VRAM 메모리에 Cache를 저장하는 것을 볼 수 있고, 비교적 우선순위가 낮은 노드들은 RAM 메모리에 Cache가 저장되는 것을 확인할 수 있다. 그렇다면 이러한 우선 순위는 어떤 기준으로 결정되는걸까?
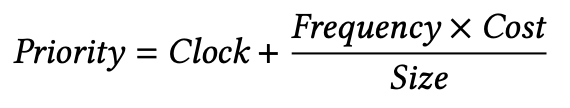
위의 수식은 Cache의 우선 순위를 계산하는 방법을 나타낸다. Clock은 해당 Cache가 최근에 호출된 시간을 나타내며, 더 최근에 호출이 되었을수록 높은 우선순위를 가진다. Frequency는 얼마나 자주 호출되는지를 나타내는 호출 빈도이며, Size는 토큰의 개수이다. Cost는 토큰당 얼만큼의 연산 시간이 드는지를 나타내는데 관련 수식은 아래와 같다.
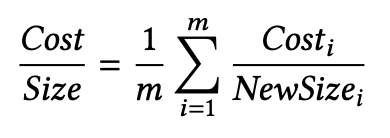
Eviction 되는 토큰은 위의 수식의 Priority가 가장 낮은 Cache를 우선적으로 쳐내는데, GPU Memory에 상주하는 Cache가 꽉차서 교체를 해야될 때는 GPU 메모리에 상주하는 Leaf Node 중 가장 우선순위가 낮은 Node를 메인 메모리로 옮기고 새로운 노드를 VRAM에 추가한다. 그리고 메인 메모리에서도 가장 우선 순위가 낮은 Leaf 노드를 탈락시키고 새로운 노드를 채워넣는 방식으로 설계된다.
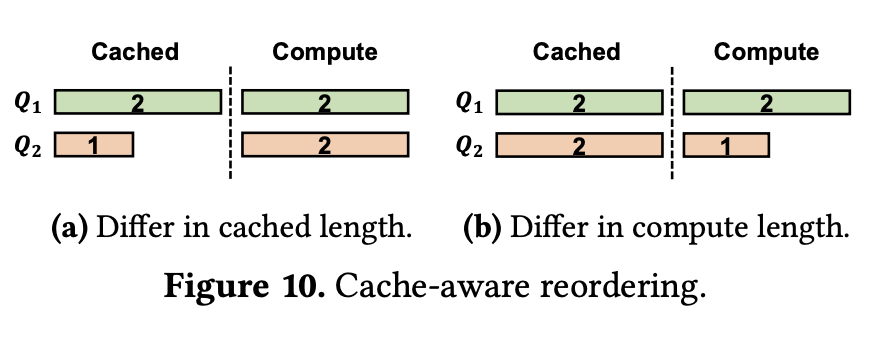
그림 6. Cache-Aware Reordering 방법 예시
다음은 Cache-Aware Reordering 방식이다. 이 부분은 입력들이 여러 개가 동시에 입력되었을 때 Cache를 적용하기에 가장 유리한 방식으로 입력의 실행 순서를 바꾸는 방법이다.
위의 그림에서 왼쪽은 이미 Cache에 저장된 States의 토큰 길이가 하나는 2이고 하나는 1이고, 새롭게 컴퓨팅 해야되는 토큰의 길이가 각각 2인 상황이다. Q1을 먼저 실행하면 2의 States를 꺼내와서 쓰고, 2를 연산한 다음에 Cache에 저정하려고 하는데 공간이 꽉 찼을 때 1을 Cache에서 Eviction하고 채워넣었다고 해보자. 1은 Cache에서 탈락되었기 때문에 새로 연산을 하고 뒤 따라오는 2의 길이 입력도 연산을 하면 총 5의 길이만큼 Compute가 수행된 것이다. 그렇다면 Q2를 먼저 실행하고 Q1을 실행하면 어떨까? 1을 Cache에서 꺼내 쓰고 2를 연산한 다음에 2를 저장하기 위해서 저장되어 있는 Q1의 Cache를 Eviction하고 저정한다. 그러면 Q1의 Cache에 있던 2의 입력을 다시 Compute하고 뒤따라오는 2를 Compute하면 총 6의 연산을 수행해야 하므로 순서만 바뀌었을 뿐인데 연산량이 증가하였다.
오른쪽은 저장할 수 있는 Cache의 용량이 총 5일 때를 가정 했을 때이다. Q2를 먼저 실행하면 길이 1의 입력을 Compute하고 Eviction 없이 Cache에 저장할 수 있다. 하지만 Q1이 먼저 실행되면 Q2의 길이 2짜리 Cache를 Eviction 해야하기 때문에 2의 연산이 추가로 적용된다.
이처럼 Cache-Aware Reordering은 컴퓨팅해야하는 길이가 같을 때는 캐싱된 입력의 길이가 긴 입력을 우선적으로, 캐싱된 입력의 길이가 같을 때는 컴퓨팅 해야하는 입력의 길이가 짧은 것을 우선으로 실행하도록 순서를 조정하는 방법이다.
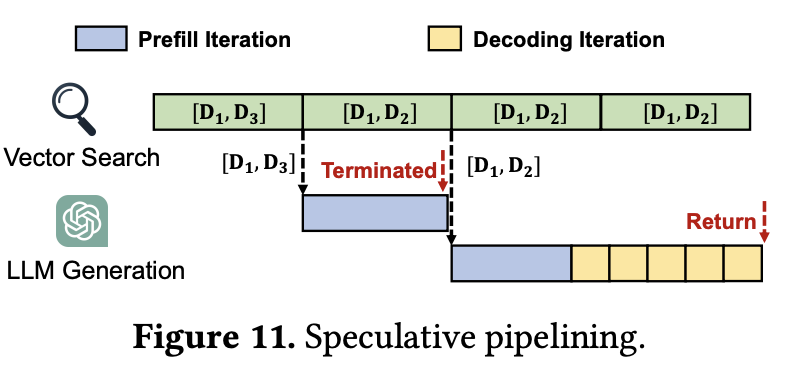
그림 7. Speculative pipelining 구조
위의 그림은 Speculative pipelining 방법을 나타낸다. 해당 방법은 Retrieval 과정에 필요한 시간이 많이 길어질 때, Generation을 위한 대기 시간이 길어지면서 생기는 병목 현상을 최소화하기 위한 방법이다. 벡터 DB를 이용한 Retrieval 과정은 일반적으로 IVF나 HNSW와 같은 알고리즘을 통해서 이루어진다. 이때, 벡터 탐색을 한번에 처리하게 하지 않고 작은 타임 슬라이드로 나누어서 단계별로 진행하도록 하면 벡터 탐색의 중간 결과를 얻을 수 있다. 최종 단계의 결괏값이 정확하겠지만 때로는 중간 값에서 구해진 결과랑 최종 결괏값이 일치할 수도 있다. 이에 Speculative Pipelining은 중간 결과가 나오면 미리 Generation을 수행하고 있다가 최종 결괏값과 수행하고 있던 입력이 일치하면 계속해서 진행하고, 만약 다른 최종 결괏값이 나오면 달라진 입력으로 다시 생성 과정을 수행하도록 하는 것이다.
오늘은 Cache 기능을 이용해서 검색된 컨택스트 문서의 프롬프트를 반복해서 인코딩하는 것을 방지하고, 이미 연산된 States를 Cache에서 불러와서 재사용하는 RAG Cache를 살펴보았다. 본 글에서는 대략적인 RAG Cache의 구조나 적용된 방법을 얕게 정리해두었고, 원본 논문에는 구현을 위한 다양한 방법과 정보들이 상세하게 적혀 있기 때문에 더 관심이 가는 분들은 원본 논문을 살펴보는 것을 강력하게 추천한다.
안녕하세요. RAGCache를 읽고있는 학생입니다.
아무리 생각해도 Cache-aware reordering 부분이 이해가 가지 않습니다.
Figure 10 (a)에서 논문에서는 계산할 때 캐시 용량이 부족해서 Q_2를 지운다고 했는데(블로그에는 저장할때라고 되어있네요) 계산할 때 지운다고 받아들이나 저장할 때 지운다고 받아들이나 Q_2를 계산할 때는 어쨌든 5라는 크기가 필요한데 아무리 생각해봐도 개념이 안섭니다.. 혹시 답을 알고 계시나요 ㅠㅠ
안녕하세요, 댓글이 거의 잘 안달리는 편이라서 확인을 할 생각을 잘 못해서 답변이 늦었습니다 ㅠㅠ
논문에서 캐시 용량이 4라고 가정을 하고 Figure 10(a)를 설명하고 있습니다.
Q1을 우선적으로 연산하는 경우(길이가 긴 캐시 요청을 우선 처리), 캐시에서 Q1을 꺼내쓰고, Q1의 Compute를 연산하면서 Q2의 캐시 부분을 비우게 됩니다.
그러면 Q1(캐시 활용) + Q1(Compute) + Q2(Cache에서 탈락하여 Compute) + Q2(Compute) = 0 + 2 + 1 + 2
반대로 Q2를 먼저 연산한다고 가정하면
Q2(캐시 활용) + Q2(Compute) + Q1(Cache에서 탈락하여 Compute) + Q1(Compute) = 0 + 2 + 2 + 2의 연산이 처리됩니다.
이에 figure 10(a)에서는 캐시에 저장되어 있는 항목의 연산량이 다르고, 추가로 컴퓨팅해야하는 연산량이 같을 때는 Cache에서 연산량이 높은 항목을 우선적으로 처리하도록 Reordering 하는것이 유리하다는 부분을 이야기하고 있는 것 같습니다.