이번 글에서는 “Understanding tables with intermediate pre-training “을 리뷰해보려고 한다.
이번 논문에서는 “Table Entailment”라는 태스크가 중심으로 다루어지고 있는데, 이 태스크는 설명하기 전에 Text Entailment를 먼저 설명하겠다. Text Entailment는 자연어추론(Natural Language Processing Inference)라고도 불리는데 입력된 두 텍스트 간의 관계를 예측하는 태스크이다. 관계는 보통 Entailment, Refuted, Neutral로 이루어져 있다. 아래는 위키피디아 Text Entailment 문서에서 가져온 예제이다.
- text: If you help the needy, God will reward you.
- hypothesis: Giving money to a poor man has good consequences.
- text: If you help the needy, God will reward you.
- hypothesis: Giving money to a poor man has no consequences.
- text: If you help the needy, God will reward you.
- hypothesis: Giving money to a poor man will make you a better person.
위에서부터 순서대로 Entail, Refuted, Neutral의 관계를 가지고 있는 예제들이다.
Table Entailment는 테이블 데이터와 가설이 존재할 때, 가설의 내용이 해당 테이블의 내용과 어떤 관계인지를 예측하는 태스크라고 볼 수 있다. 이 태스크의 가장 대표적인 데이터셋으로는 TabFact가 있다. 이 태스크에 대한 예제로는 아래와 같다.
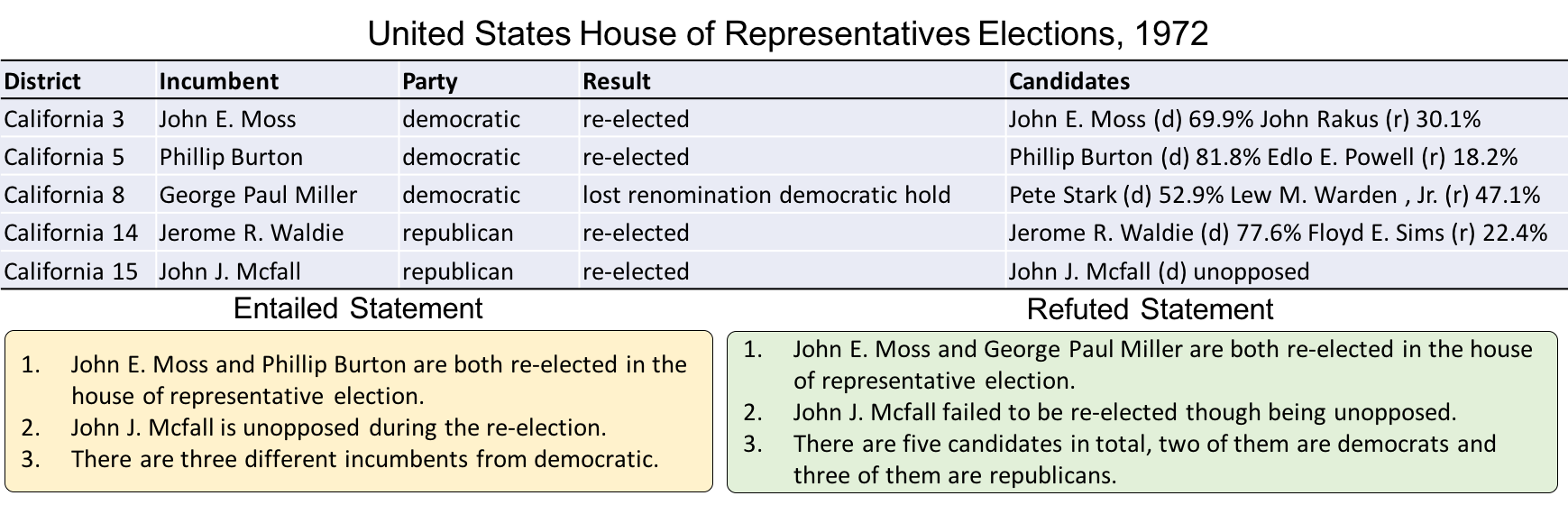
Entailed Statement의 예제를 살펴보면 John.E와 Philip Burton은 re-elected 되어서 표의 내용과 비교하여 Entail한 것을 확인할 수 있다. 반대로 Refuted Statement의 경우, John E와 Paul Miller가 re-elected 되었다고 하고 있지만 표에서는 Paul Miller는 loss renomination이라고 나오기 때문에 표에 나와있는 사실과 다른 것을 확인할 수 있다.
이러한 Table Entailment 데이터는 Hypothesis에 있는 사실들을 표에 있는 내용들과 비교하고 추론하기 때문에 사전학습된 표 언어모형의 추론 능력을 평가하는 등의 용도로 활용될 수 있다.
하지만 본 논문에서는 이러한 태스크를 사전학습된 언어모형을 평가하는데에 사용하는 것 뿐만 아니라 표를 위한 언어모형을 사전학습하는데에 사용하는 것을 제안하였다.
Semantic Parsing과 같은 표 질의응답 태스크를 살펴보면, 표를 잘 이해하는 것 뿐만 아니라 표와 같이 입력된 텍스트와 표 데이터를 보고 추론하는 능력이 필요하다. 본 논문에서는 Table-Entailment의 기존 데이터셋이 존재하지만, 사전학습을 위해서는 더 방대한 양의 Table Entailment 말뭉치가 필요하기 때문에 위키피디아 데이터를 이용해서 자동으로 Table Entailment 데이터를 생성하는 방법을 다루고 있다. 또한 이전 글에서 다루었던 TAPAS를 사전학습했던 방법인 MaskLM으로 먼저 사전학습을 하고 중간 단계 사전학습(Intermediate Pre-training) 방법으로 이 태스크를 적용했을 때 많은 Table Parsing 벤치마크에서 State-of-Art 성능을 기록했다.
그렇다면 이 논문에서는 어떤 방법으로 자동으로 데이터를 생성했는지 먼저 살펴보겠다. 이 논문에서는 크게 2가지의 방법으로 데이터를 생성했는데 첫 번째는 Counterfactual Statement를 생성하는 방법이고, 두 번째는 Synthetic Statement를 생성하는 방법이다. 아래의 예시 이미지를 보며 하나씩 살펴보겠다.
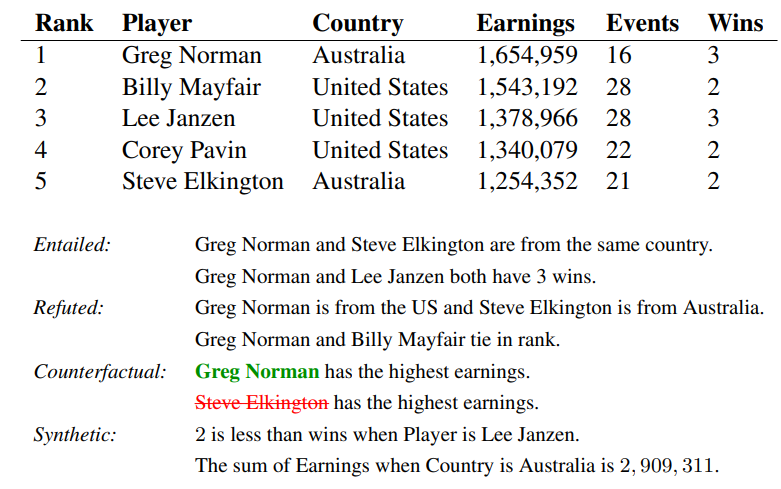
우선 Entailed 관계의 문장들을 자동으로 가져오기 위해서 위키피디아에서 표가 존재하는 문서들을 탐색하고 Entailed 관계일 수 있는 표와 문장들을 가져온다. 그리고 가져온 표와 문장이 Entailed한 관계인지 아닌지 판단하기 위해서 여러가지 Heuristic한 방법들을 적용하게 되는데, 문장에서 가리키고 있는 위키피디아 링크와 같은 링크를 표의 어떤 셀에서 가리키고 있는 것과 같은 경우이다.
표와 문장에서 같은 값이나 엔티티를 가지고 있는 경우 해당 엔티티나 값을 ‘focus mention’으로 지정하게 된다. 이 focus mention은 같은 Column 내에 존재하는 셀들은 replacement mentions가 된다. focus mention과 replacement mentions를 교체함으로써 해당 Statement가 False가 된다는 보장은 없지만 교체를 하여 Counterfactual한 Statement를 생성하게 된다. Focus mention과 같은 Row에 존재하는 셀들은 Supporting Mention이 되는데(E.g. Australia) 이러한 엔티티들도 교체해줌으로써 False Statement가 될 확률을 높일 수 있다. 그렇기에 Supporting Mention 후보들을 발견하면 다른 값을 가지도록 제한한다.
Statement에서 Replacement를 하다보면 문법적으로 틀린 문장이 나올 수 있으며, 이는 모델이 Statement를 Negative로 판별하게 되는 의도치않은 특징이 될 수 있다. 이에 이 논문에서는 Entity(개체명, 날짜, Cardinal 숫자, Ordinal 숫자)를 주로 교체하였으며, 같은 타입의 엔티티끼리만 교체를 수행하도록 하였다.
이러한 방법을 통해서 약 410만 개의 Counterfactual Pair를 확보하였다.
다음 방법은 Synthetic Generation을 하는 것이다. 이러한 방법론은 다른 표를 위한 사전학습 방법에서도 활용이 되는데(GraPPa), 표의 내용은 제한적이고 구조화되어 있기 때문에 이러한 표의 내용을 표현하는 Statement를 만드는 것은 자연어 문단으로 하는 것과 비교하여 비교적 기계적이고 규칙적인 방법이라고 볼 수 있다. 이에 본 논문에서는 간단하게 만들어진 SQL과 비슷한 표현들을 Context-free Grammar를 이용해서 생성하는 방법을 통해서 추가적인 Statement Pair를 생성하는데에 이용하였다.


Synthetic Statement는 위와 같은 Context-free Grammar 규칙으로 생성된다.
이번 논문에서는 TabFact와 같은 Table Entailment를 태스크를 이용해서 표 언어모형의 추가적인 사전학습을 하는 방법을 제안한 논문을 다루어보았다. 본 논문에서는 위키피디아에서 추출한 Statement를 임의로 False Statement가 되도록 엔티티들을 같은 Column 내에 존재하는 다른 엔티티들과 교체해주는 방법으로 Counterfactual한 Pair를 자동으로 만들어서 많은 데이터를 확보할 수 있었다. 추가적으로 Context-free Grammar를 이용하여 인공적인 Counterfactual한 Statement들을 만들어서 Synthetic Statement를 추가적으로 자동으로 생성하는 방법을 이용하였다.
이렇게 생성된 데이터들을 이용한 Table-Entailment 기반 사전학습 방법은 기존 TAPAS에서 제안했던 MaskLM 사전학습에 이어서 Intermediate 사전학습 방법으로 추가 사전학습에 적용했을 때, 언어모형의 표와 텍스트간의 이해 능력을 향상시켜서 다양한 Table Parsing 벤치마크에서 SOTA를 기록했다.
TAPAS 논문을 처음 읽었을 때는 과연 Table의 일부 토큰을 날리고 복원하는 것은 표의 구조적인 정보를 더 잘 이해하게 하는 것은 도움이 되겠지만 표의 각 Column에서 값을 비교하거나 하는 대소비교, 순서비교와 같은 추론 능력을 향상시킬 수 있을까 의문이 들었던 적이 있다. 이 논문에서 제안하는 추가적인 사전학습 방법은 이러한 의문의 해소에 도움을 주었던 것 같다.