오늘은 TAT-DQA에 이어서 TAT-LLM을 리뷰해보려고 한다. TAT-LLM은 TAT-QA와 같은 표와 텍스트를 모두 읽고 답하는 태스크를 LLM을 이용해서 구현한 모델이다.
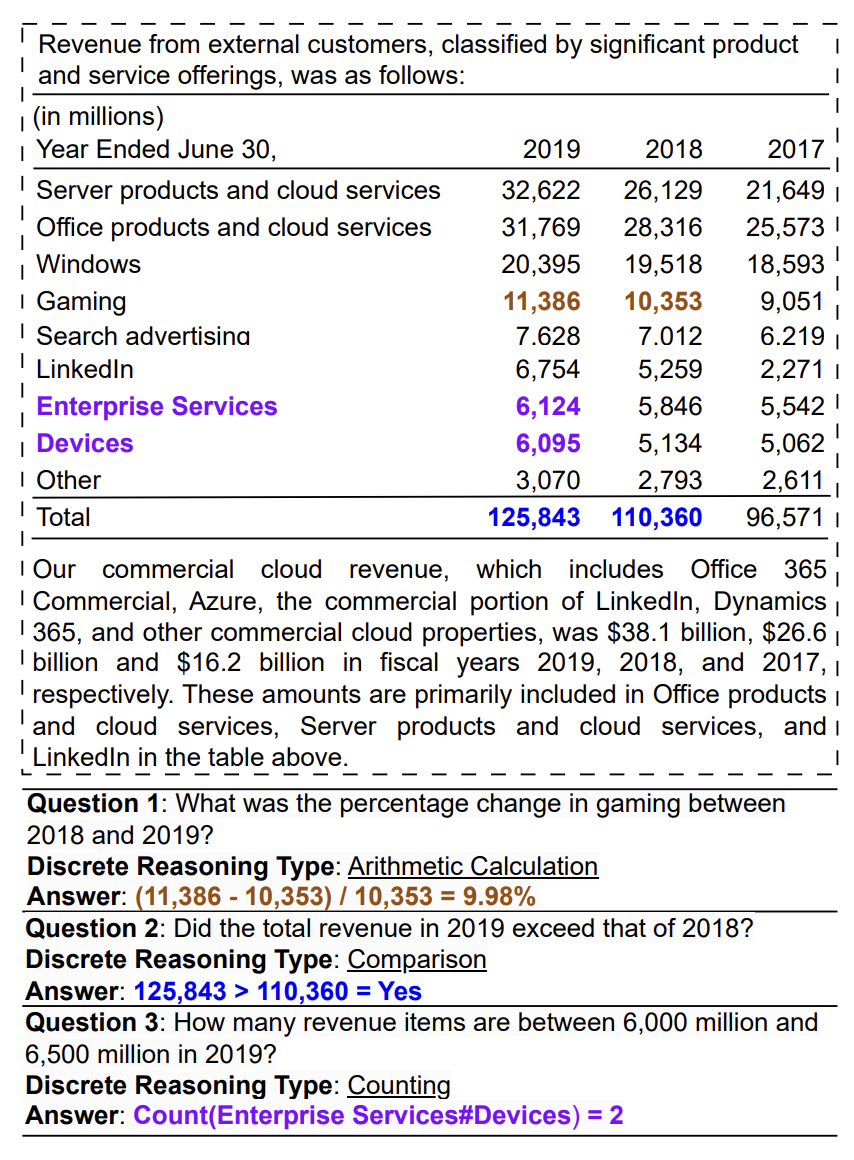
그림 1. TAT(Table-and-Text) 관련 태스크 예시
이번 논문에서는 표와 텍스트를 동시에 다루는 QA 벤치마크인 TAT-QA, TAT-DQA, FinQA를 대상으로 실험을 진행하였다.
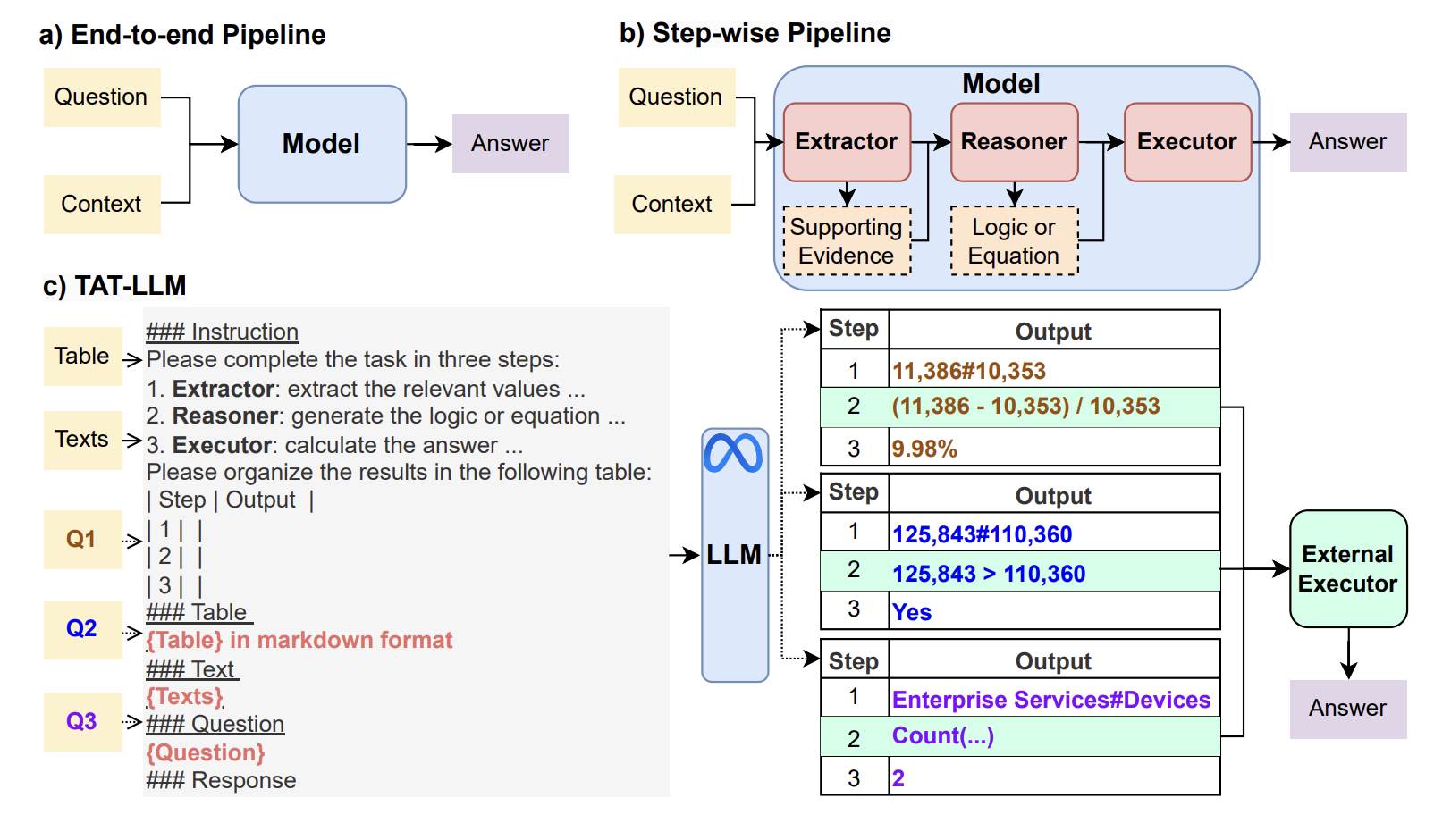
그림 2. TAT-LLM 모델 구조
위의 그림은 TAT-LLM의 전체적인 구조를 나타낸다. 해당 논문에서는 step-wise pipeline이란 방법을 적용했는데, Instruction 부분을 살펴보면 해당 방법의 내용을 살펴볼 수 있다. 우선 step-wise pipline에서는 답을 구하는 과정을 Extractor, Reasoner, Executor로 나누어서 실행하도록 하였다. Extractor는 Supporting Evidence를 생성하도록 하는 것인데 그림의 예와 같이 최종 정답을 도출하기 위해서 두 셀 125,843, 110,360의 값을 비교할 필요가 있다면 최종 정답 도출에 필요한 모든 셀들을 먼저 구하도록 하는 것이다. 두 번째 Reasoner 단계에서는 정답 도출을 위해 선택된 셀들을 이용해서 최종 정답 도출에 필요한 수식을 생성하도록 한다. 마지막으로 Executor 단계에서는 외부의 수식 실행기를 이용해서 수식의 연산을 실행하고, 계산 결과를 이용해서 최종 정답을 도출하도록 한다.
이 논문의 큰 특징은 LLM을 처음으로 TAT 태스크에 적용시켜서 성능을 구해보았다는 점, 그리고 step-wise pipeline을 통해서 순차적으로 답을 생성하도록 했다는 것이다. 학습에 사용된 모델은 긴 Context 처리가 가능한 LLama-2(4096)을 사용하였다. 저자는 LLama-2를 선택한 이유중 긴 컨텍스트 처리가 가능함을 강조했는데, FinQA는 표와 텍스트를 합하면 긴 컨텍스트 길이를 가지기 때문에 기존의 512 길이의 처리가 가능한 모델에서는 단락이나 표를 선별하는 모델이 필수적이었다. 하지만, LLama-2는 긴 입력을 바로 사용할 수 있기 때문에 이러한 과정 없이 바로 처리가 가능하였다. 파인튜닝은 LoRA를 통해서 진행되었다.
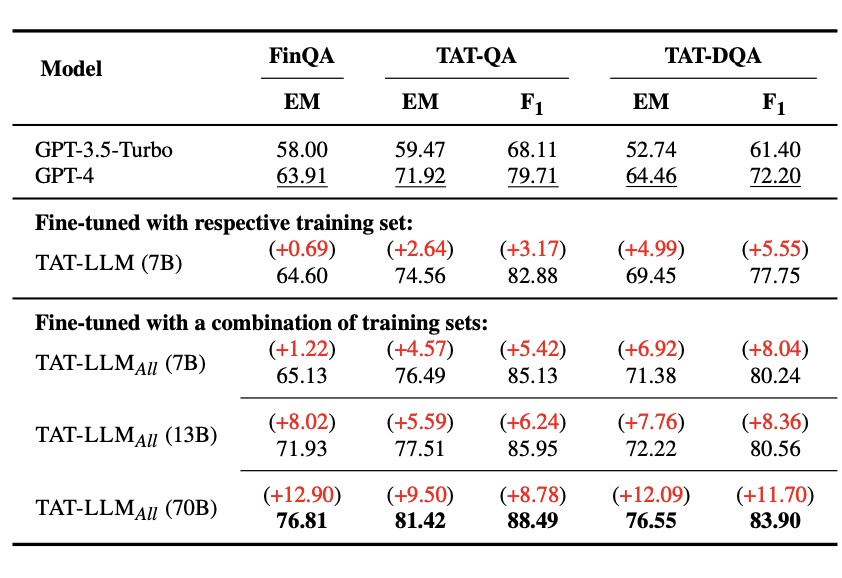
그림 3. TAT-LLM 실험 결과
위의 그림은 TAT-LLM의 성능을 나타낸다. step-wise pipeline을 이용해서 파인튜닝을 했을 때, 7B 크기에서도 GPT-4 보다 성능이 높게 측정되었다. 또한 3가지 데이터셋을 같이 학습에 적용했을 때, 소폭 성능이 상승하는 것을 확인할 수 있다.
추가로 간단하게 살펴볼 논문은 TableLLama이다.
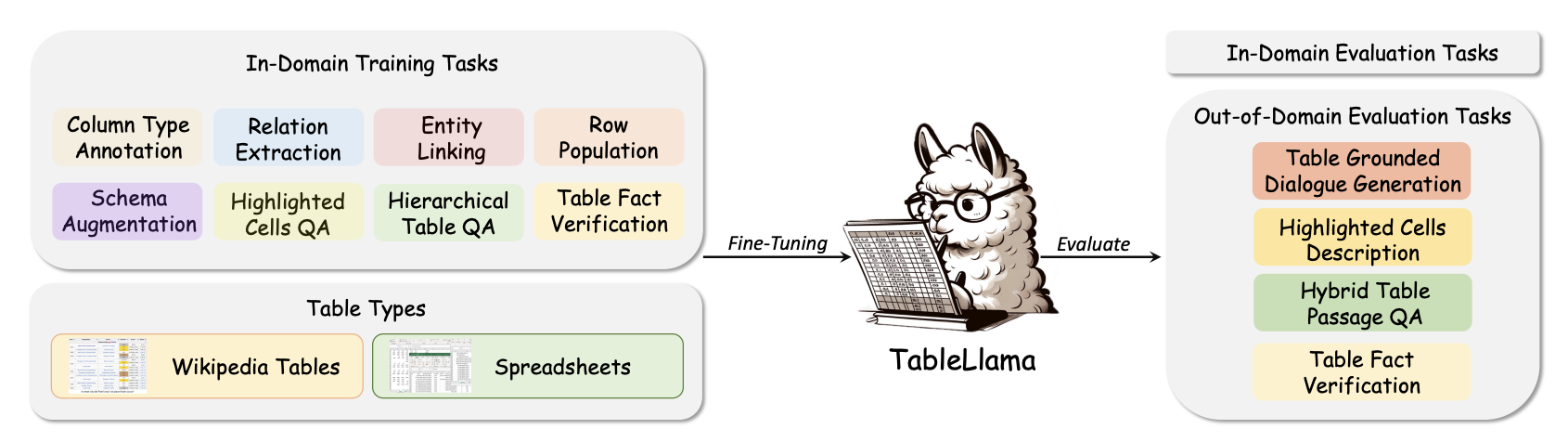
그림 4. 테이블 라마 구조
테이블 라마는 왼쪽의 8가지 태스크를 Table Instruction으로 학습하여 평가한 모델이다. 학습한 8개의 태스크는 Column Type Prediction, Row Population, Hierarchical Table QA의 3가지 종류로 구성되어 있다. 아래의 그림은 3가지 종류의 태스크와 Instruction 예제를 나타낸다.

그림 5. 3가지 종류의 태스크 예제
Column Type Prediction은 Column의 Semantic한 Type을 예측하는 태스크이다. 예를 들어 Player Column의 Type이 뭐야? 라고 질문을 하면 해당 Column의 엔티티들이 어떤 타입의 엔티티를 가지고 있는지 예측하는 것이다. Population 태스크는 의미 그대로 테이블을 덧붙이는 태스크인데, 주어진 테이블에 Row를 계속 덧붙여서 생성하는 것이다. 마지막으로 Hierarchical Table QA는 계층적 구조를 가지는 표 데이터에 QA 태스크를 수행하도록 하는 태스크이다.
테이블 라마는 이러한 Real World 표로 구성된 8개의 데이터셋(In-domain)으로 먼저 라마를 파인튜닝하고, 학습되지 않은 나머지 데이터(out-of-domain)에 평가를 하여 얼마나 일반화가 잘 되었는지 평가를 하였다.
파인튜닝은 TAT-LLM과 마찬가지로 LoRA로 하였는데, 긴 컨텍스트에 특화된 LongLoRA를 적용하였다. 학습을 위한 backbone 모델은 LLama-2(7b)를 이용하였다.
아래는 테이블 라마의 in-domain 태스크와 out-of-domain 태스크의 실험 결과이다.
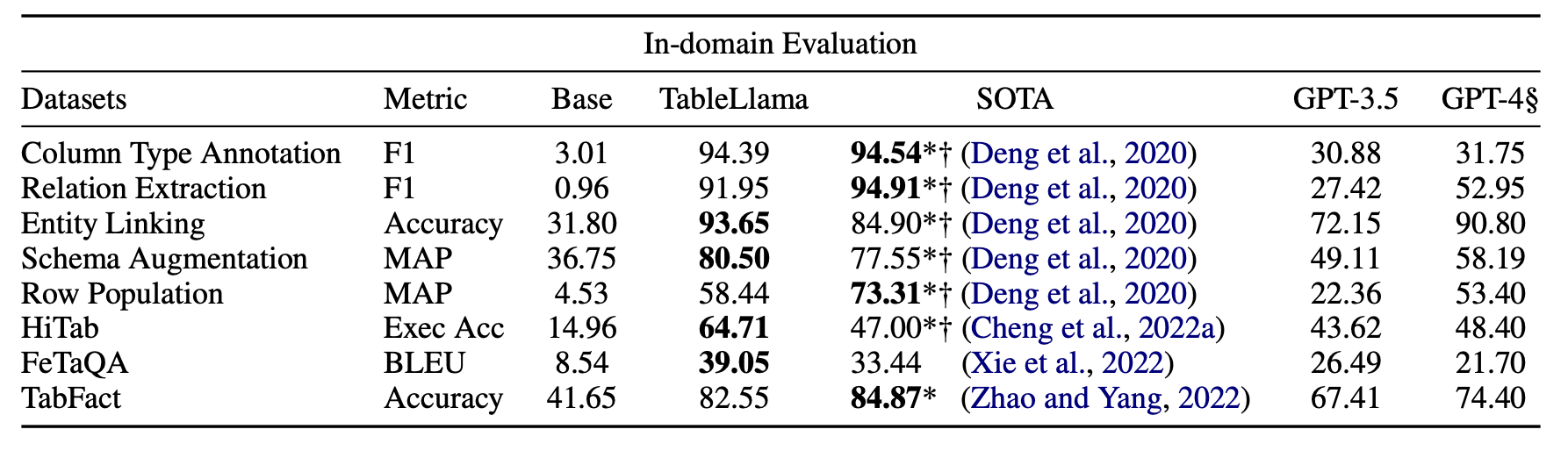
그림 6. In-Domain 태스크 실험 결과
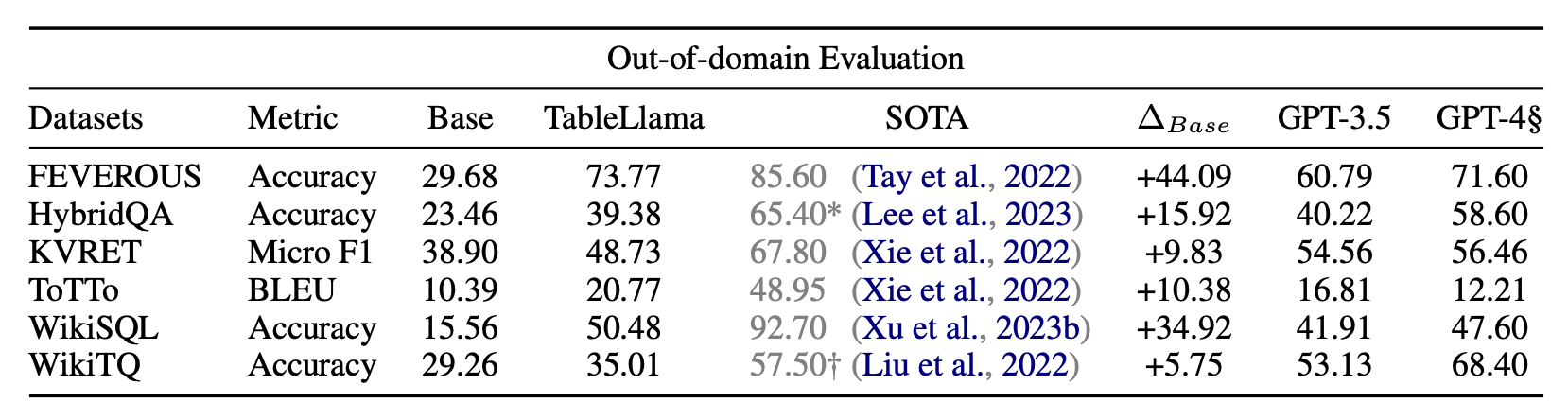
그림 7. Out-of-domain 태스크 실험 결과
In-domain 태스크에서는 TAT-LLM과 비슷하게 많은 태스크에서 SOTA의 성능을 보였으며, 대부분의 태스크에서 GPT-4 보다 높은 성능을 보였다. Out-of-domain 태스크를 살펴보면 SOTA와 비교해서는 대부분 훨씬 낮은 성능을 보였다. 여기서 WTQ나 WikiSQL은 계층적 구조의 표를 적용하지 않는 일반적인 TableQA 태스크라고 할 수 있는데, 특히 WTQ 태스크에서 매우 낮은 성능을 보였다. 하지만 개인적으로는 일반화의 관점에서는 해당 논문의 방법이 맞겠지만, WikiTQ와 같은 태스크는 Hi-Tab과 입력되는 표의 성질이나 출력되는 정답의 성질이 다를 수 있기 때문에 In-domain으로 학습한 성능도 추가로 제시하여 같이 비교할 수 있었으면 좋았을 것 같다.
표와 관련된 태스크에서는 LLama 모델을 바로 적용했을 때, 만족할만한 성능을 얻지 못하는 경우가 많았다. 하지만, 표 데이터에 파인튜닝을 하여 해당 태스크에 특화를 시켰을 때는 만족할만한 성능을 얻을 수 있었다. 하지만, 테이블 라마의 out-of-domain 태스크의 실험 결과에서 볼 수 있듯 ChatGPT와 같이 다양한 태스크에 대한 일반화 성능을 가지고 가면서 이러한 SOTA 성능을 달성하기에는 힘들었다.