오늘 소개할 논문은 이전 논문이지만 TAPAS를 다루려고 한다.
앞으로 테이블을 다루는 언어모형에 관한 글을 순차적으로 다룰 예정인데, 그 시작으로 TAPAS를 먼저 리뷰해보려고 한다.

위의 그림은 표 질의응답의 예시를 나타낸다.
“나는 [MASK] 갔다.” => “나는 집으로 갔다.”와 같은 MaskLM을 이용한 언어모형의 사전학습 방법은 많은 NLP태스크에서 SOTA를 기록했었으며, 이를 통해서 언어의 다양한 지식이 학습된다는 것이 다양한 논문을 통해서 증명되었다.
하지만 이렇게 학습된 언어 모델은 구조화되지 않는 자연어(unstructured natural text) 데이터를 기반으로 사전학습되었기 때문에 언어모형이 테이블의 구조적인 정보를 포착하는 것은 힘들 수 있다.
본 논문에서는 표의 구조적인 정보를 포착하기 위한 방법으로 표에 특화된 특수 임베딩을 추가하는 것, 그리고 표 데이터를 이용한 사전학습 방법을 통해서 이를 해결하고자 하였다.
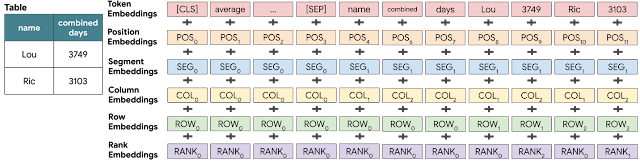
위의 이미지는 TAPAS의 임베딩 레이어의 구조를 나타낸다. Token, Position, Segment 임베딩의 경우 기존의 BERT에서 사용되었던 임베딩이며, COL, ROW, RANK는 TAPAS에서 표의 구조적 정보를 인코딩하기 위해서 추가한 임베딩이다. Column과 Row 임베딩은 입력된 토큰이 표에서 몇 번째 행 또는 열인지를 나타내는 표에서의 행&열 위치에 관한 Position 임베딩으로 생각할 수 있다. Rank 임베딩은 3749, 3103과 같이 대소 비교가 가능한 열들에 한해서 Row-wise하게 순위를 매기고 해당 순위를 Position 임베딩처럼 추가한 것이다. 이외에도 논문에서는 한가지 특수 임베딩을 설명하고 있는데 그것은 “Previous Answer” 임베딩이다. 이 임베딩은 0 혹은 1의 ID 값을 가지게 되는데 1이면 해당 토큰이 이전 Episode에서 정답 토큰이었음을 나타내고, 0이면 그렇지 않은 토큰을 나타낸다. 해당 토큰은 SQA와 같은 대화형(Conversational) 표 질의응답 데이터셋을 위해서 사용되며, 나머지 WikiTQ, WikiSQL과 같은 벤치마크에서는 사용되지 않는 특수 임베딩이다.
위키피디아 Infobox
TAPAS에서는 표의 사전학습을 위해서 위키피디아에서 약 6.2백만 개의 표 데이터, 2.9 백만 개의 Infobox 데이터를 크롤링하여 사전학습 데이터로 사용하였다. 언어모형이 최종 적용되는 End-Task에서는 표만 등장하는 것이 아니라 질문과 같은 텍스트 데이터가 등장하게 된다. 사전학습 과정에서는 이를 대신하는 역할로 문서의 제목, 문서의 정의, 표에서 가까이 나타나는 문서 세그먼트 등을 사전학습의 입력으로 함께 이용하였다. 사전학습 방법은 BERT 모델과 동일하게 일부 토큰을 마스킹하고 마스킹된 토큰을 복원하는 MaskLM을 이용하였으며, 전체 단어를 한꺼번에 마스킹하는 Whole-Word Masking과 비슷한 방법으로 Whole-Cell Masking을 이용하였다.
다음은 End-Task에 적용되는 Fine-tuning 방법을 살펴보겠다.
정답 셀의 위치를 알 수 있는 경우, 그렇지 않는 경우에 비해서 더 간단하게 학습이 가능하다. 아래는 정답 셀의 위치를 알 수 있을 때 Column Selection과 Cell Selection을 하기 위한 수식이다.
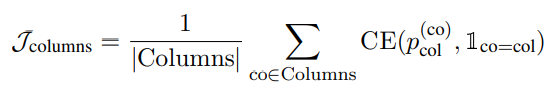
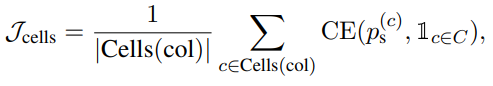
Column Selection과 Cell Selection 모두 Binary Cross Entropy를 통해서 정답이 있는 Column 혹은 Cell의 위치를 예측하도록 학습된다.
문제는 WTQ와 같은 데이터셋에서는 Ground Truth 정답은 제공이 되지만 어떤 셀들과 연산을 통해서 해당 Ground Truth를 계산할 수 있는지에 대한 정보는 제공되지 않는다. 이에 TAPAS에서는 Regression Loss를 이용하여 Weak Supervision 학습을 하였다.
WTQ와 같은 데이터셋에서도 Ground Truth와 셀 텍스트들을 비교해보면 정답 셀의 위치를 판별할 수 있는 케이스들이 있는데, 해당 데이터들은 위에서 언급했던 방법으로 학습한다.
그렇지 않는 데이터의 경우, 정답 Scalar를 예측하고 해당 값과 Ground Truth를 비교하여 Regression Loss를 최소화하는 방향으로 학습된다.
예측 Scalar 값을 만드는 방법은 아래의 식과 같다.
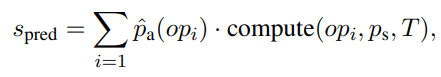
Pa(op_i)는 average, diff, sum, count와 같은 연산 방법중에 op_i가 정답 연산에 필요할 예측 확률을 나타낸다. compute는 정답 셀로 예측된 셀들과 예측 연산을 통해서 예측 값을 생성하는 과정을 나타낸다. 이 과정을 예를 들어서 표현하면 아래와 같다.
ground truth: 15
선택된 셀들의 값: 7, 8
avg: 0.2 diff: 0.2 sum:0.5 count:0.1
avg = 7.5
diff = 1
sum = 15
count = 2
pred = 7.5 * 0.2 + 1 * 0.2 + 15 * 0.5 + 2 * 0.1 = 1.5 + 0.1 + 7.5 + 0.2 = 9.3
그러면 pred로 계산된 값 9.3과 실제 ground truth 15 간의 regression loss를 계산해서 이를 Minimize하는 방향으로 모델을 업데이트하게 된다.
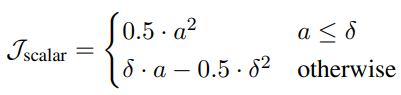
TAPAS에서는 Regression Loss로 Huber Loss를 이용하였다. 해당 Loss를 사용한 이유는 Squared Loss(abs(Pred – Groud_Truth)) 를 이용하는 것 보다 안정적인 학습이 가능하다고 한다.
- 요약
이번 글에서는 BERT를 표에 맞게 개량하고, 표 데이터에 사전학습하여 표 데이터에 특화시킨 사전학습 언어모형인 TAPAS를 살펴보았다.
본 논문에서 핵심적인 내용은 표에 맞는 언어모형을 구축하기 위해서는 표 데이터에 대한 추가적인 개량과 사전학습이 필요하다. 이에 표를 위한 특수 임베딩과 표 데이터를 이용한 추가 사전학습 과정을 추가하였다.
본 논문에서는 Semantic Parsing 과정에서 Logical Form을 생성할 필요없는 End-to-End 모델을 지향하고 있으며, 이러한 Weak Supervision 학습을 가능하게 하기 위해서 Scalar 형식의 정답에 대해서는 Regression 방법을 이용해서 학습을 하였다.