오늘 살펴볼 논문은 두나무에서 발표한 ” MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation”이다.
해당 논문은 한동안 BIRD-SQL 태스크에서 1위를 기록했던 모델을 소개하고 있다. 아래의 그림은 MCS-SQL의 전체적인 구조를 나타낸다.
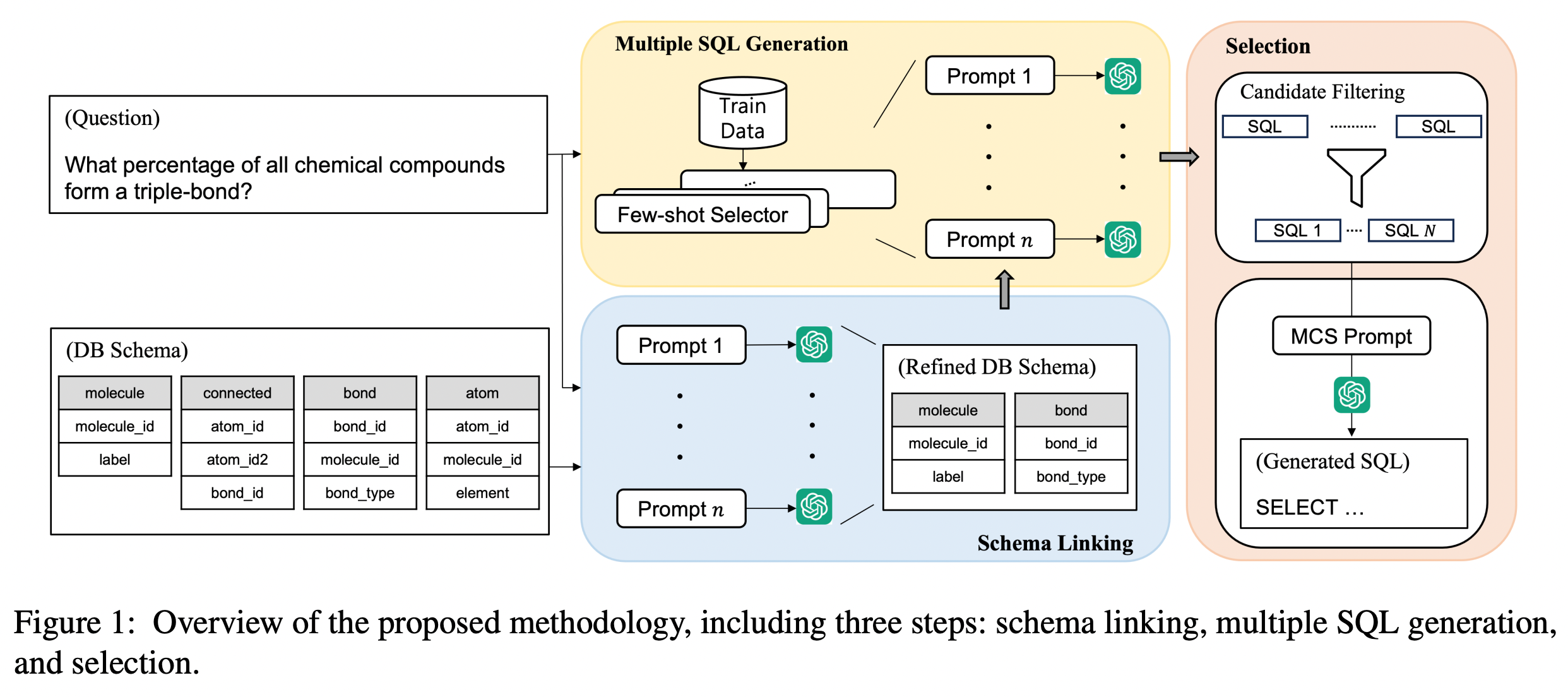
그림 1. MCS-SQL 모델 구조
위의 그림을 살펴보면 모델의 실행 스텝은 총 3가지로 이루어져 있다.
- Schema Linking: 질문과 관계가 없는 Table과 Column를 제거한다
- multiple SQL generation: 다양한 SQL 후보들을 생성한다(이때 다양한 프롬프트를 사용)
- 후보들 중에서 가장 정확하다고 예측되는 SQL 쿼리를 선택한다
Schema Linking
Schema Linking 단계는 DB에 포함된 질문과 관련있는 Table들과 Column들을 구분하는 단계이다. 이 부분은 다시 관련 있는 Table을 구분하는 단계와 관련있는 Column을 구분하는 단계로 나뉜다.
Table Linking은 DB의 Schema와 질문을 LLM에 입력하고 관련있는 Table들의 리스트를 출력하도록 하는 단계이다.


그림 2. Table Schema Linking 프롬프트 예시
위의 그림은 Table Linking을 위한 프롬프트 예제를 나타낸다. 모델의 강건성(Robustness)를 높이기 위해서 해당 논문에서는 여러 개의 프롬프트를 사용하였다. 예를 들어 Lost in the middle 논문에서는 같은 데이터라도 입력되는 데이터가 중간 순서에 오는 데이터는 LLM이 참고를 잘 하지않는다고 하였다. 이처럼 입력되는 스키마 정보들 역시 입력되는 순서에 따라서 성능이 달라질 수 있기 때문에 이러한 순서를 달리하여 여러 개의 프롬프트를 실행시켜 결과를 얻는다. 그리고 여러개의 프롬프트에서 얻은 결과 리스트는 Union 연산을 적용하는 방법으로 취합하여 최종 결과를 얻는다.
Column Linking
이전 Table Linking 과정에서 추출했던 관련있는 Table들의 질문과 관련있는 Column을 추출하는 과정이다. 이 때, 추출된 Table 마다 중복된 Column들이 존재할 수 있는데 이러한 중복 방지를 위해서 관련있는 Column을 추출할 때는 [Table_name][Column_name] 형식으로 추출하도록 하였다.
이전 단계에서와 마찬가지로 데이터가 입력되는 순서에 의한 성능 변화를 최소화하기 위해서 입력되는 데이터의 순서를 Shuffle해서 여러 개의 프롬프트를 실행하고 취합하는 방법을 적용하였다.
Multiple SQL Generation
이전에 했던 다양한 연구들에 의하면 Text-to-SQL 태스크를 실행할 때, 입력되는 프롬프트의 few-shot 예제에 어떤 데이터를 넣는지에 따라서도 성능이 크게 달라질 수 있다. 그리고 마찬가지로 데이터들이 입력되는 순서에 따라서도 성능이 달라질 수 있다.
해당 논문에서는 적절한 예제들을 고르기 위한 방법으로 2가지의 다른 방법들을 적용하였다.
- Question-Similarity를 이용한 방법으로 학습 데이터셋에서 질문과 가장 가까운 유사도를 가지는 top-K 데이터셋을 선택하는 방법이다. 이때 유사도를 계산하기 위해서 임베딩 방법을 사용한다.
- 마스킹된 질문의 유사도를 기반으로 한 방법으로 DB Shema와 관련된 특정 토큰들을 마스킹한다. 아래는 Masking 되는 예시를 나타낸다. 이러한 방법으로 Table-Specific한 내용들을 걸러내고 정말 비슷한 구조를 가지는 질문을 가지는 예시 데이터들을 찾게 된다.

그림 3. Masking Question의 프롬프트에 포함된 예제
SQL Generation


그림 4. SQL Generation 프롬프트 예제
이제 프롬프트에 채워넣을 few-shot 예제들을 구했으니 SQL을 생성하면 된다. 이때 입력의 순서나 few-shot으로 입력되는 예제들을 달리 하여 여러 개의 프롬프트를 이용해서 여러 응답들을 구하게 된다.
그러면 만들어진 여러 답변 후보들 중에 최종 정답은 어떻게 고르는 것일까?
우선 같은 실행 결과를 내는 SQL을 생성한 질문들을 한 그룹으로 묶는다. 그리고 각 그룹에서 가장 빠른 쿼리만이 남도록 한다. 자세히 설명하자면, 모든 질문 후보들은 DB에서 실행되고 Syntax 에러를 내는 질문들은 후보에서 제외된다. 그 다음 각 후보 그룹에서 가장 빠른 DB 실행속도를 내는 질문들만 남고 나머지는 탈락시킨다.
그리고 각 그룹마다 남은 SQL 쿼리들을 아래의 프롬프트에 입력하여 최종 한가지 SQL을 선택하도록 한다.

그림 5. 최종 SQL을 선택하기 위한 프롬프트
이때, reasoning step을 추가하여 LLM이 해당 SQL을 고른 이유를 함께 생성하도록 유도한다.
아래는 MCS-SQL의 실행 결과이다.
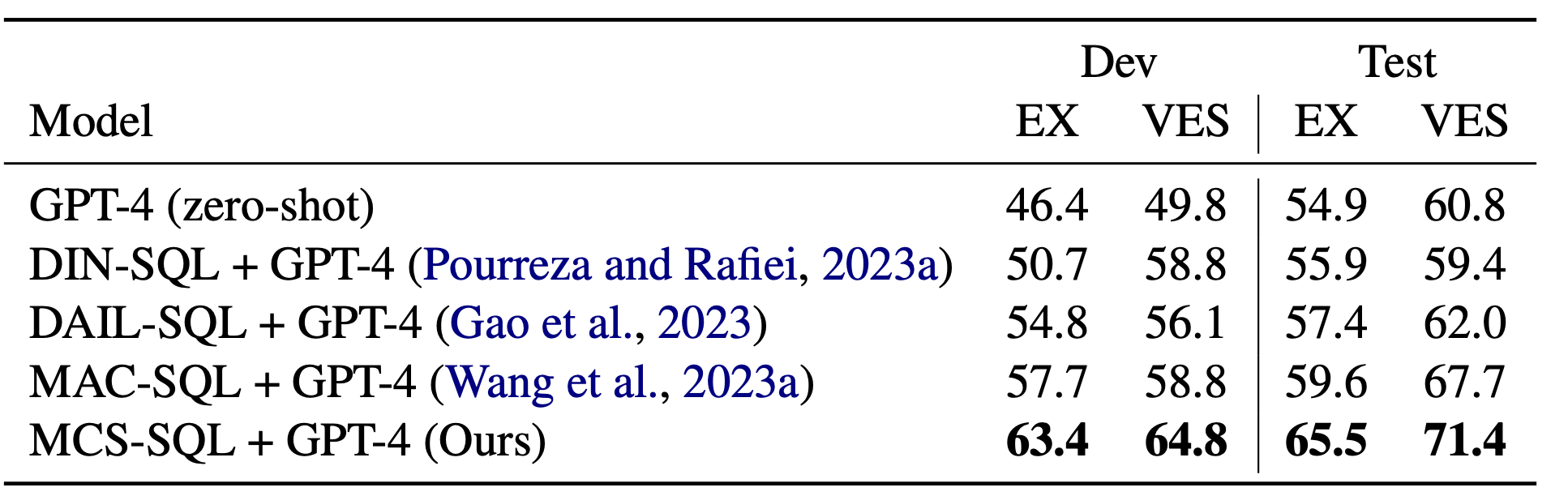
그림 6. MCS-SQL 모델 실행 결과
이번 글에서는 BIRD 벤치마크에서 한동안 1등을 기록했던 MCS-SQL 모델을 살펴보았다. 해당 논문의 방법은 프롬프트에 입력되는 데이터의 순서에 따라 결과가 달라지는 것을 고려하여 여러 개의 프롬프트를 만들고 해당 결과들을 조합하면서 진행하는 방법을 주로 적용하였다. 또한, 적절한 few-shot 예제를 선택할 때는 임베딩의 유사도를 기반으로 유사한 질문의 예제들을 추출하였는데, 이 때 스키마와 관련된 토큰들을 마스킹처리하고 오로지 순수한 질문의 기능적 유사도를 기반으로 예제를 뽑았던 부분도 인상적인 부분이었다.