오늘 살펴볼 논문은 Nvidia에서 발표한 “LLM Pruning and Distillation in Practice: The Minitron Approach”이다. 해당 논문은 Nvidia에서 Minitron의 Pruning과 Distillation을 적용한 과정과 실질적인 결과들을 기록한 논문이다. 해당 논문에서는 LLama 3.1 모델과 Mistral NeMO 모델을 압축시킨 결과들을 정리하였다.
LLM은 LLama 3,1에서 8B, 70B, 405B를 출시한 것과 같이 사용하려는 목적과 스케일에 따라서 각기 다른 모델들을 사용하고 있다. 하지만, 이러한 Billon 단위의 모델들은 Scratch 부터 학습시킨다면 어마무시한 비용이 들게 된다. 만약 사용하려는 목적에 맞는 모델의 크기가 출시되어 있지 않다면(가령, 20B와 같이) 해당 크기의 모델을 Scratch 부터 학습시키기 보다는 이미 공개된 더 큰 모델을 압축시켜서 사용하는 것도 하나의 방법일 수 있다.
해당 논문에서는 LLama와 Mistral NeMO를 성공적으로 압축시켰는데, Nvidia에서 공개한 또 다른 논문인 “Compact Language Models via Pruning and Knowledge Distillation”의 방법을 주로 활용하였다.
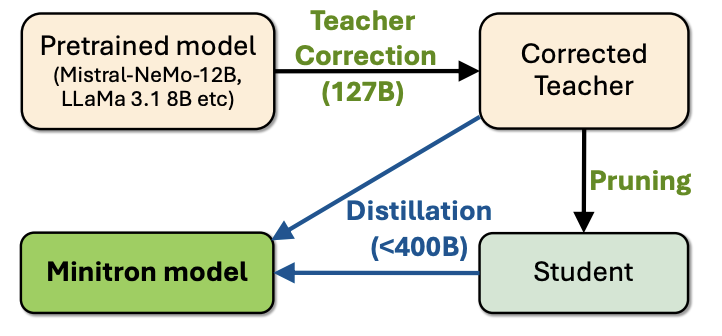
그림 1. Minitron 모델 Pruning 과정
또 다른 논문의 방법에서 한가지 핵심적인 차이를 두었는데, 그것은 Corrected Teacher를 만드는 Teacher Correction 과정이다. 이 과정은 Pruning 하려는 파운데이션 모델에 사용된 원본 학습셋들에 모두 접근이 어렵거나 불가능한 점을 고려하여 Teacher 모델을 자신들의 데이터에 추가로 파인튜닝하여 사용하는 것이다.
우선 Teacher Correction 과정을 자세히 보기에 앞아서 이전 논문(“Compact Language Models via Pruning and Knowledge Distillation”)에서 사용된 방법들을 살펴보겠다.
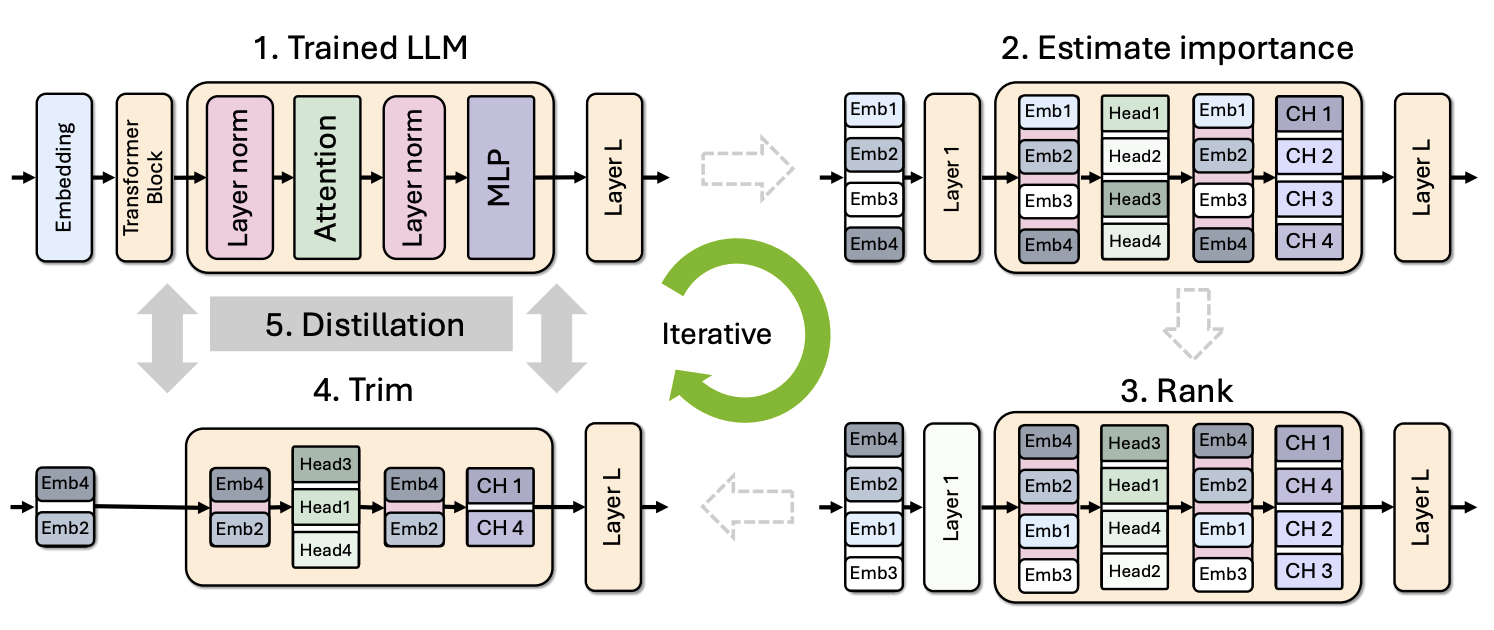
그림 2. LLM 모델의 Pruning 과정
위의 그림은 일반적인 모델의 Distillation 및 Pruning 과정을 나타낸다. Estimate Importance 방법을 통해서 중요도가 높은 레이어, 어텐션 헤드, 임베딩, 뉴런 등을 결정하고 Rank를 매기고 Trim을 하는 과정을 반복하는 방식으로 이루어진다. Weight Magnitude를 통해 중요도를 추정하는 등의 잘 알려진 방법은 LLM에서는 별로 효과적이지 않았는데, 대신 Calibration Dataset에 대한 gradient/Taylor, consine similarity, perplexity을 활용하는 방법들이 LLM에서 좋은 효과를 보였다. LLM은 너무나 비싼 메모리와 컴퓨팅 파워를 요구하기에, 이러한 비싼 과정들을 피해서 효율적으로 Pruning 하는 것이 중요한 목표인데, 해당 논문에서는 “Activation-based”의 중요도 추정 방법을 통해서 이를 구현하였다. 해당 방법에서는 Gradient를 계산하는 Backward의 과정없이 Forward의 과정으로만 구현할 수 있었다. 또한, 해당 방법에는 1024개의 매우 작은 Calibration Sample만이 사용되었다.
Pruning 과정은 Width(어텐션 헤드, 뉴런, 임베딩)과 Depth(Layer)의 과정으로 나뉜다.
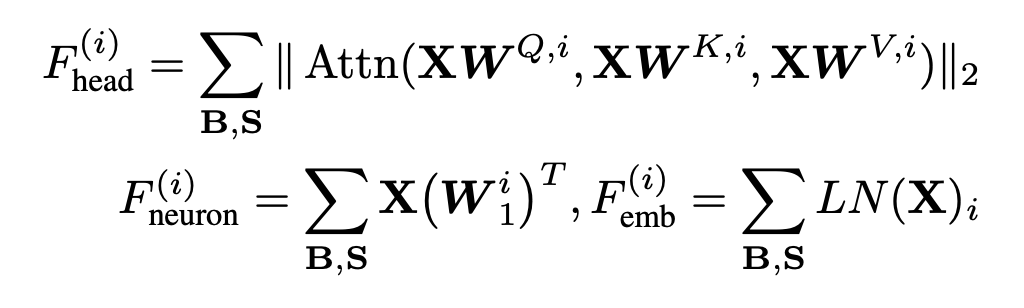
어텐션 헤드는 Attention 레이어의 출력 값의 절댓값 크기의 합, 뉴런에서는 MLP 레이어의 합, 임베딩에서는 Layer Normalization의 합을 통해서 중요도를 계산한다. 이렇게 계산된 각 헤드나 뉴런의 중요도에 따라서 Prune할 헤드나 Neuron을 결정한다.
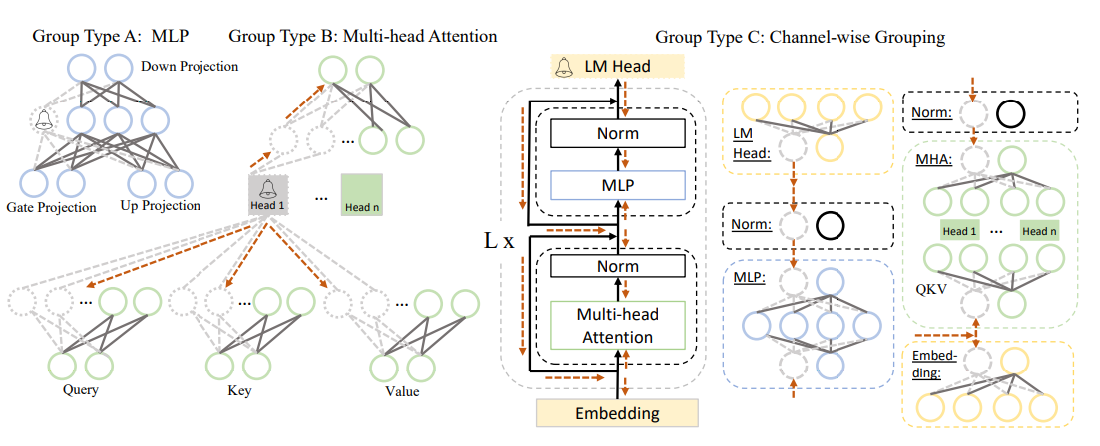
그림 3. LLM Pruner(LLM-Pruner: On the Structural Pruning of Large Language Models )의 Pruning 방법
위의 그림은 LLM Pruner라는 이전 연구의 논문의 Pruning을 설명하는 그림이다. 어떤 Neuron이나 Head를 Pruning할 때 해당 Element와 연결되어 있는 모든 파라미터를 그룹으로 묶어서 Pruning을 한다.
다음으로 Layer의 중요도를 구하는 방법에는 Perplexity를 이용하는 방법과 Block Importance를 계산하는방법이 있다.
우선 Perplexity를 구하는 방법은, 특정 Layer를 Pruning 한 뒤에 Calibration Data에서의 Perplexity를 계산하여 Pruning 되었을 때 Perplexity의 차이를 통해서 중요도를 파악할 수 있다.
BI는 레이어의 입력과 출력 간의 Cosine 유사도를 계산하는 방법이다.
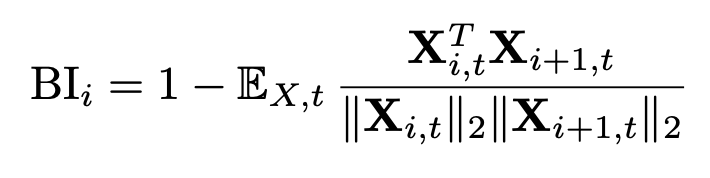
Perplexity를 이용한 방법은 모든 레이어에 대해서 하나씩 Pruning을 해가며 Perplexity를 계산해야 하지만, BI를 이용한 방법은 단 한번의 Forward 과정만으로 모든 레이어에 대한 중요도를 구할 수 있기 때문에 속도가 훨씬 빠르다.
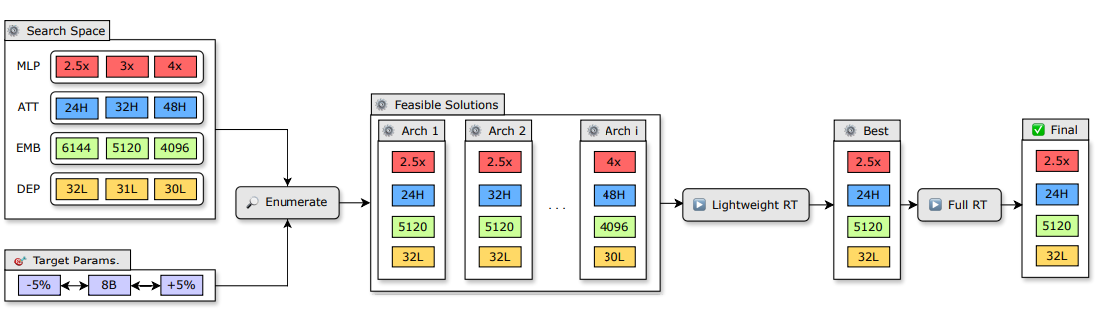
그림 4. LLM의 적절한 Architecture를 찾는 알고리즘
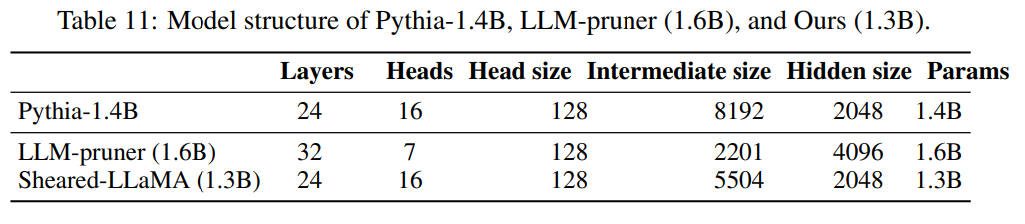
그림 5. Targeted Structured Pruning을 한 Shered-LLaMa와 LLM-Pruner의 모델 Configration 비교
LLM-Pruner에서는 Prune Mask를 학습시키면서 모델의 학습 결과에 따른 Pruning을 하였지만, 이후 Sheared-LLaMA에서는 각 영역별로 Pruning 해야하는 크기를 정해놓고 Pruning 하도록 하는 Targeted Structured Pruning 방법을 사용했다. 위의 그림을 살펴보면 LLM-pruner는 Intermediate Size가 Hidden Size보다 작게(일반적으로 잘 적용하지 않는 구조) 생성된 것을 확인할 수 있다. 그렇다면, Targeted Structured Pruning을 할 때, 어떻게 최적화된 Configuration을 찾을 수 있을까? Configuration을 찾을 때 Search Space가 너무 넓기 때문에 Genetic Algorithm이나, Bayesian Optimization을 이용해서 적절한 Architecture를 찾게 된다. 하지만, 해당 논문에서는 이미 검증된 LLM들의 Configuration을 가져와서 Target으로 하는 파라미터의 크기에 맞게 조합하는 방식으로 Search Space를 줄였다. 이렇게 선택된 후보들은 Lightweight Re-training을 거쳐서 최종 선택되는데, 이 때 Lightweight RT는 LoRA를 통해서 적은 메모리로 빠르게 수행된다.
Pruning이 끝난 모델들은 Retraining 과정을 거쳐서 Pruning 된 상태에서 기존 Source 모델의 성능과 지식을 최대한 그대로 유지할 수 있도록 하는 추가적인 학습 과정을 거치게 된다. RT에서는 모델의 Output prabability 분포가 비슷해지도록 학습시키는 Knowledge Distillation 방법이 적용되었다.
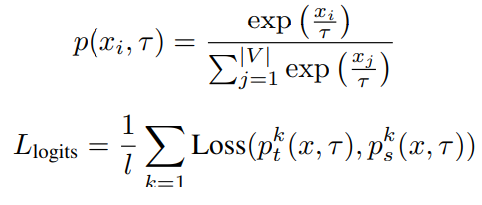
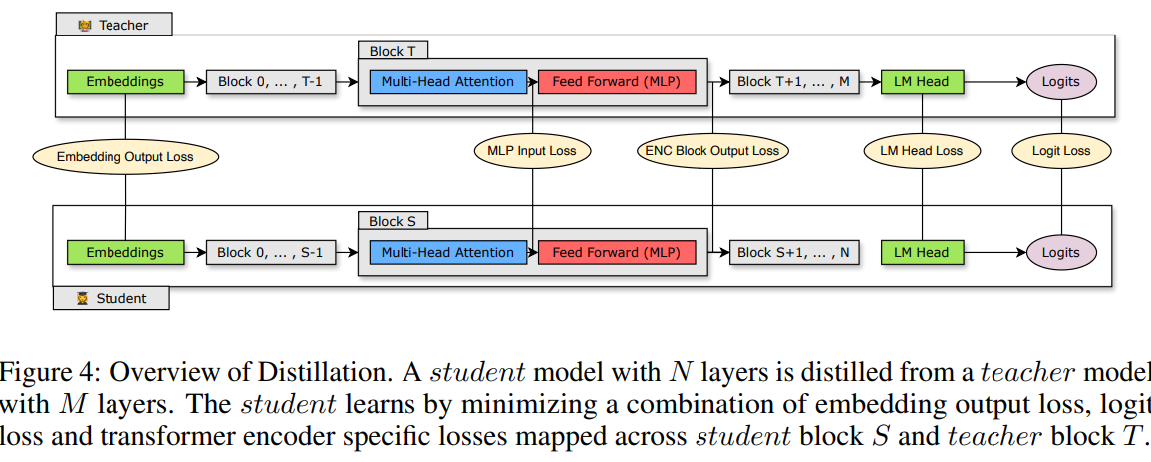
KD Loss로 학습되는 intermediate states는 다양한 조합으로 만들어질 수 있는데 위의 그림은 해당 논문에서 적용한 intermediate states 조합을 나타낸다. Pruning 된 모델과 원본 Source 모델간의 Hidden Size와 같은 크기 차이는 공유된 Linear Transformation 레이어를 거쳐서 Student 모델을 Upscale하여 해결하였다.
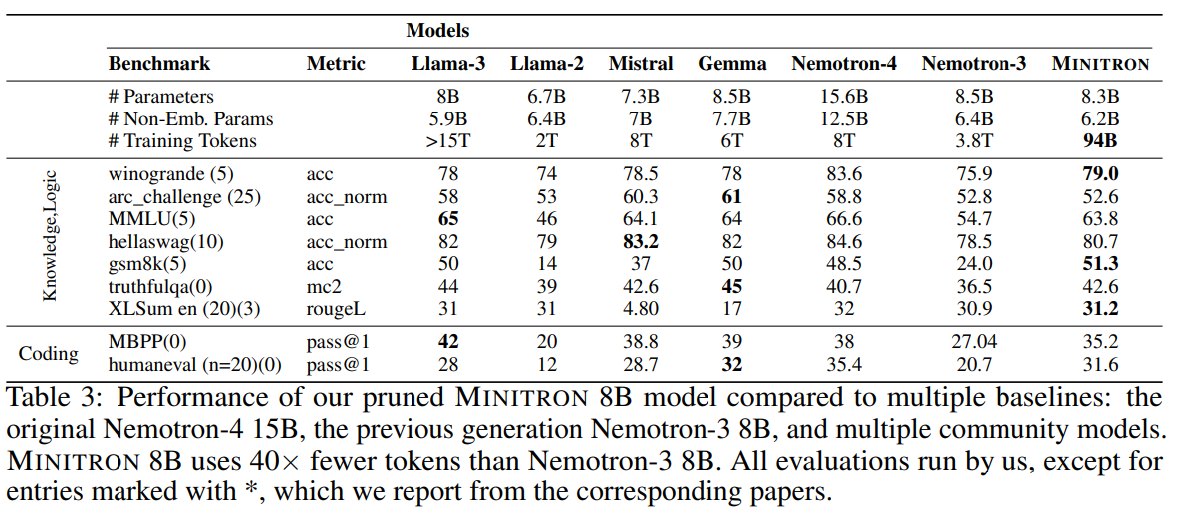
위의 표는 Pruning 된 Minitron과 다른 최신 모델들과의 비교 결과를 나타낸다. (Nemotron-4는 Original Model) 특히, 비슷한 크기의 Scratch부터 학습된 Nemotron-3 보다 더큰 모델인 Nemotron-4를 Pruning한 Minitron의 성능이 더 잘 나오는 것을 확인할 수 있다.
이번 글에서는 Nvidia에서 Nemotron을 Pruning하여 만든 Minitron을 어떻게 Pruning을 하였는지 살펴보았다. LLM을 서비스하는데에는 모델의 과도한 메모리와 컴퓨팅 파워 요구량 때문에 천문학적인 유지 비용을 필요로 한다. 그에 따라서 모델의 양자화 등 많은 방법론들이 개발되고 있는데, 더 큰 모델을 Pruning 하여 사용하는 것도 가까운 미래에는 매우 대중적인 방법으로 자리잡을 것 같다는 생각이 든다.
How is the Teacher Correction method different from previous approaches in the Pruning model process, and what are its benefits?
Regard IT Telkom
Generally, teacher model was pretrained on train dataset which is different with distillation dataset.
Because of this problem, teacher model provides sub-optimal guidance.
In most of cases, it is impossible to access original train dataset of foundation model. So, in teacher correction process, they perform a lightweight fine-tuning of the teacher model to adapt to the new distillation dataset.
Previous studies have not considered the challenges posed by differences in the distribution of these datasets.