이번 논문 리뷰에서는 구조화 된 테이블(Hierarchical Table)를 다루고 있는 표 질의응답 데이터셋 HiTab을 다뤄보려고 한다.
일반적으로 기존의 표 질의응답에서 사용되는 데이터셋은 단순한 2D 구조로 이루어져 있는 평면 구조의 테이블(flat table)을 주로 다루고 있다. 평면 테이블은 아래의 그림과 같이 단순하게 위에는 아래의 셀들을 나타내는 헤드, 그리고 헤드의 밑에는 해당 헤드에 대한 셀들이 있는 구조이다.
그렇다면 구조화된 테이블은 기존의 평면 테이블과 어떤 차이가 있을까? 아래의 그림이 HiTab 논문에서 나온 구조화된 테이블의 예시이다.
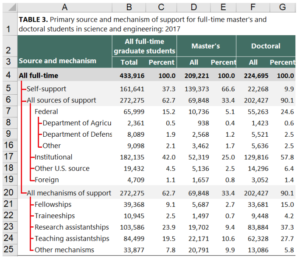
위의 그림에서 테이블의 헤더 밑에 존재하는 행들이 트리 데이터와 같이 구조화되어 있는 것을 확인할 수 있다. 예를 들어 Federal은 “All sources of support”라는 셀의 자식 행(Child Row)가 될 수 있고, “Department of Agriculture”를 포함한 3개의 셀의 부모 행(Parent Row)가 될 수 있다. 질의응답에서는 이러한 표의 구조적인 형태를 고려해서 답변을 해야하기 때문에 기존의 평면 테이블을 이용하는 질의응답 데이터셋에 비해서 훨씬 난이도가 높아질 수 있다.
평면 테이블은 위키피디아를 포함해서 다양한 문서에서 수집할 수 있는 반면 이러한 구조화된 표 데이터는 특정 도메인의 문서에서만 취급하는 경우가 대부분이다. 본 논문에서는 구조화된 테이블 데이터를 수집하기 위해서 Statistics Canaca(StatCan), National Science Forum(NSF), CDC, BLS, IMF 등과 같은 과학이나 금융과 같은 수치를 많이 다루는 전문 도메인 문서에서 테이블을 수집하였다.
HiTab은 기존의 다른 테이블 질의응답 데이터셋과 마찬가지로 수치추론(Numerical Reasoning)을 필요로 하는 질문들을 포함하고 있으며, 해당 질문의 정답 연산에 필요한 셀 정보를 태깅하기 위해서 Entity와 Quantity Alignment를 데이터셋 제작 과정에서 추가로 태깅하였다. 여기에는 max/sum/div/diff와 같은 연산자의 연산에 필요한 셀 정보, (=G23-G24)와 같은 계산식을 포함하고 있다.
본 논문에서는 HiTab의 baseline 모델을 구현하기 위해서 End-to-End 모델로 TAPAS를 이용하였으며, Logical Form을 이용하는 학습 방법으로는 MML(Maximize Marginal Likelihood)(관측된 프로그램의 Marginal Likelihood를 최대화), 강화학습(관측된 프로그램의 Reward를 최대화), MAPO(inside와 outside 버퍼의 프로그램으로부터 학습)의 3가지 학습 방법을 이용하는 Neural Symbolic Model을 baseline 모델로 이용하였다.
Neural Symbolic Model은 입력된 질문과 테이블로부터 정답을 생성하기 위한 Logical Form을 생성하고 생성된 Logical Form을 가지고 정답을 생성하는 모델이다. 본 논문에서는 생성되는 Logical Form이 구조화된 테이블의 구조를 반영하도록 하기 위해서 Region Selection이라는 특별한 함수를 추가하였다. 여기에는 “filter_tree h”와 “filter_level l”의 2가지 함수가 있다.
우선 filter_tree h는 헤더 셀에 해당하는 h의 sub-tree region을 전부 선택하는 함수이다. 아까 보여줬던 예시 그림에서 “Department of Agriculture”와 같은 Leaf 셀이 h인 경우에는 해당 셀의 column/row만을 선택하게 되며, “Federal”과 같이 leaf가 아닌 셀이 h인 경우 해당 셀의 sub-tree 구역까지 전부 선택되어 행 7부터 16까지 모두 선택되게 된다.
filter_level l은 입력된 tree에서 level l에 해당하는 sub-region을 모두 선택하는 함수이다.
본 논문에서는 이러한 2개의 함수를 Logical Form에 추가함으로써 다음과 같은 이점이 있다고 주장한다.
- 두 함수를 순차적으로 적용함으로써 구조적 인덱싱이 가능해진다.
- filter_level 함수를 통해서, 다른 타입의 계산(예를 들어 row 4-5)이 적용되는 region이 함께 선택되지 않는다.
- 이 함수들을 통해서 level-wise semantic을 포착할 수 있다.
본 논문에서는 Baseline 모델 실험을 위해서 Weak Supervision과 Partial Supervision의 두 가지 학습 방법을 제안하고 있다. Weak Supervision 학습 방법은 앞서 언급했던 MML, Reward, MAPO를 이용한 학습 방법으로 각 학습 기법에서 요구하는 수치(예를 들면 Margin이나 Reward 등)를 최대화하는 Logical Form을 생성하도록 모델을 학습한다. 이 학습 방법은 완벽하게 태깅된 학습 레이블 대신 생성된 Logical Form을 이용하여 Margin이나 Reward를 계산할 수 있는 Ground Truth만을 가지고도 학습이 가능하다. 다만, 학습의 초반 단계에서는 완벽하게 태깅된 데이터로 어느정도 학습을 하고, 이후 학습에서는 완전히 태깅된 레이블 없이 학습하는 방식으로 Warm-Start를 해야만하기 때문에 학습의 초반 단계를 위한 완벽하게 태깅된 Logical Form 데이터가 필요하다. 이에 랜덤하게 15,000개의 데이터를 선택하여 Logical Form을 태깅하였다.
TAPAS를 이용한 baseline 학습에서는 이러한 Logical Form을 이용하지 않기 때문에 굳이 Warm-Start의 학습을 위한 태깅을 필요로 하지 않는다.
Partial Supervision에서는 Weak Supervision과 같이 학습을 하되, 데이터에 태깅되어 있는 추가 정보들(Entity Links, Quantity Links, Calculations)를 최대한 가이드로 삼아서 학습을 하는 방법이다. 태깅된 추가 정보들을 잘 조합하면 정답을 위해서 선택되어야 하는 헤더, 구역(Region), 정답 계산에 필요한 연산을 알아낼 수 있다. Neural Symbolic Model 학습에서 잘못된 프로그램들을 걸러내기 위해서 사용되었는데, 간단하게 예를 들면 정답이 10이고, 4와 6인 셀을 더해서 정답 10을 생성하도록 하는 프로그램이 생성되어야 하지만 다른 구역의 셀을 가져와서 5와 5를 더해서 정답 10을 생성하는 잘못된 프로그램들을 걸러내는 용도로 이용하게 된다.