최근 합성 데이터 기술 스타트업들이 빠르게 성장하고 있으며, 합성 데이터의 시장이 37조까지 성장하고 있다고 한다.
그렇다면 합성 데이터는 어떤 데이터일까?
테슬라에서는 자율 주행 자동차를 학습시키기 위해서 수 많은 데이터를 필요로 하고 있지만 모두 수집하고 태깅하기에는 너무나 많은 비용과 시간을 필요로 한다.
이에 테슬라에서는 사고 사례를 중심으로 합성 데이터를 만들어서 학습을 시키고 있다. 이러한 합성 데이터는 AI 모델을 학습시키기 위한 가상의 데이터를 말한다. 합성 데이터에는 실제 데이터의 특징을 반영해서 수 없이 많은 데이터를 빠르게 생성하는 것이 가능하다. AI 모델을 학습시킬 때 많은 데이터를 사용할 수록 모델의 성능이 증가하지만, 수 많은 데이터를 수집하고 태깅하는데에는 많은 비용이 들기 때문에 이러한 기술이 많은 관심을 받고 있다.
그렇다면 표 질의응답 분야에서는 어떨까? 이전에 소개했던 “Intermediate-pretraining” 논문에서도 이러한 합성 데이터(Synthetic Data)를 자동으로 만들어서 학습 데이터로 사용하는 방법을 제안했었다.
이와 마찬가지로 오늘 소개할 논문인 GRaPPa는 표 질의응답을 위해서 합성 데이터를 만들어서 사전학습에 적용하는 방법을 소개하고 있다.
GraPPa에서는 SCFG(Syncronous Context-free Grammar) 방법을 통해서 합성 데이터를 만드는 방법을 제안하였다. Context-free Grammar는 컴파일러에서 기계어를 번역하기 위한 문법 규칙으로, 언어를 생성하거나 분석하는데에 사용되는 일련의 규칙이다. 아래는 Context-free Grammar를 이용해서 구문을 생성하는 예제이다.
- S → NP VP
- NP → D N
- VP → V NP
- D → ‘a’ | ‘the’
- N → ‘cat’ | ‘dog’
- V → ‘chases’
다음과 같은 규칙이 있다고 가정했을 때, 문장 S로 시작해서 생성될 수 있는 구문의 예시로는
규칙1: S => NP VP, NP VP
규칙2: NP => D N, D N VP
규칙3: VP => V NP, D N V NP
규칙4: D => the, the N V NP
규칙5: N => cat, the cat V NP
규칙6: V=> chases, the cat chases NP
규칙2: NP => D N, the cat chases D N
규칙4: D => the, the cat chases the N
규칙5: N => dog, the cat chases the dog
과 같은 구문을 생성할 수 있다.
이에 GraPPa에서도 어떤 구문의 의미나 규칙(예를 들면 어떤 대소 비교와 같은)을 담고 있는 Statement를 생성하기 위한 규칙을 만들고, 다음과 같은 규칙에 따라서 자동으로 데이터를 생성해서 사전을 위한 합성 데이터를 만든다고 볼 수 있다.
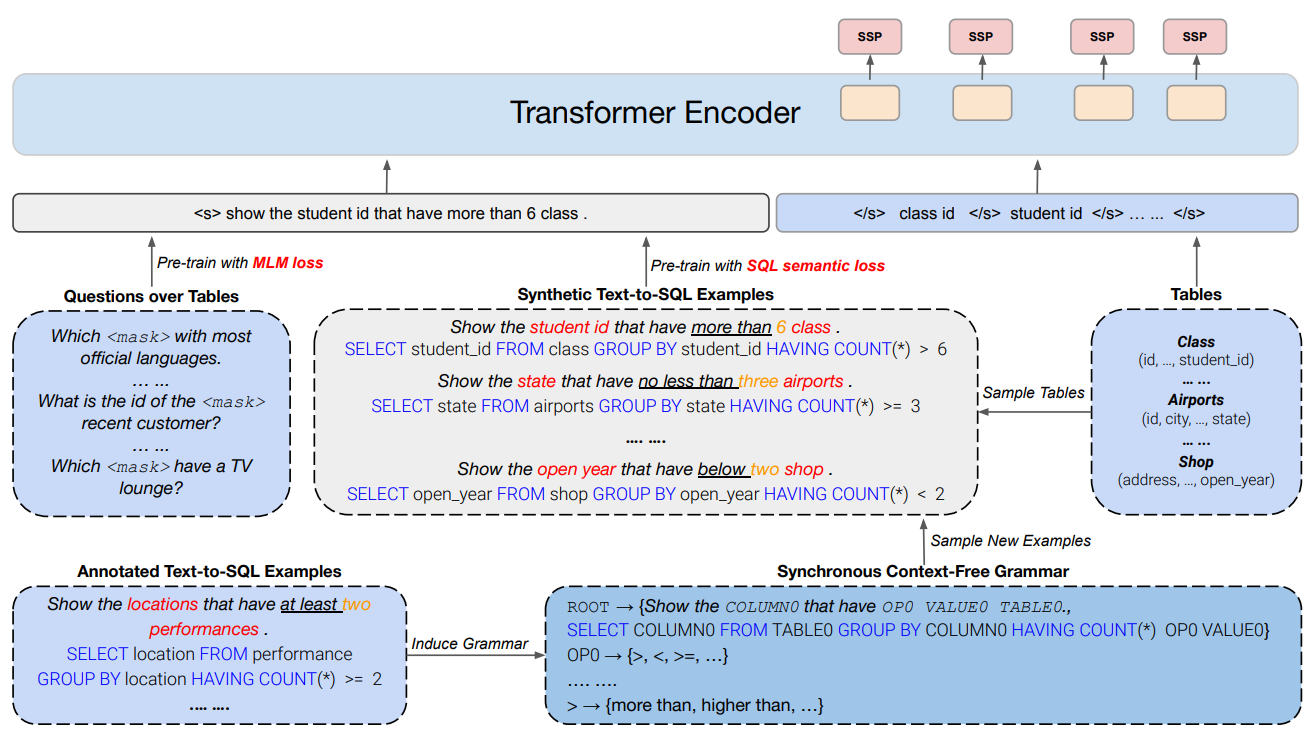
위의 그림은 GraPPa의 전체적인 사전학습 방법을 나타내고 있다.
“Show the locations that have at least two performances”와 같은 질문과 “SELECT location …”과 같은 해당 질문을 나타내는 Text-to-SQL 데이터가 있을 때, 특정 Column의 데이터를 가져오게끔 하는 column mention인 ‘Location’, 표에서 어떤 값을 언급하는 Table Mention ‘performances’, 특정 값을 나타내는 Value인 ‘two’, SQL의 Logic phrase를 나타내는 ‘at least’와 같은 값들을 같은 그룹에 존재하는 다른 값으로 교체해줌으로써 GraPPa는 새로운 합성 데이터를 생성할 수 있다.
먼저 태깅되어 있는 Text-to-SQL 데이터가 있다고 가정해보자. 완성된 SQL 식과 이에 대응하는 자연어 쿼리가 쌍으로 존재한다. 여기서 각 Value들의 역할에 따라서 특수한 토큰으로 치환을 하게 되는데, 예를 들어 “NL:locations, SQL:location”은 column 0을 가리키는 단어이기 때문에 column0으로 교체를 하게 된다. at least와 같은 단어는 연산할 종류를 나타내기 때문에 op0으로 치환이 된다. 이런식으로 Synchronous Context-Free Grammar(SCFG)에 입력될 Form을 생성하게 되고, Column, op, value, table을 적절한 값으로 샘플링을 해주게 되면 많은 새로운 데이터를 Augmentation 할 수 있으며, 태깅되었던 SQL 데이터를 기반으로 SCFG의 Form을 만들었기 때문에 샘플된 쿼리는 SQL을 실행하면 실행된 결과를 확인할 수 있기 때문에 Augmentation 된 데이터를 더 유용하게 활용할 수 있다.
GraPPa에서 사용하는 사전학습 Objective는 TAPAS에서 사용했던 가장 기본적인 방법인 MaskLM과 이 논문에서 제안한 방법인 SSP(SQL Semantic Prediction)의 2가지를 이용하였다.
MaskLM은 입력된 토큰들을 랜덤하게 [Mask] 토큰으로 치환하고 원본 토큰을 예측하는 BERT에서 사용했던 기본적인 사전학습 방법이다. 이후 다른 논문들에서도 MaskLM은 기본 역할을 하는 사전학습 Objectives로 같이 사용하는 연구들이 많았다. 이 논문에서도 해당 Objective를 합성 데이터(Synthetic Data)에 너무 Overfitting 되지 않도록 하는 역할로 사용을 했다고 하였다.
SSP는 MaskLM의 보조 역할을 하는 사전학습 방법으로 사용을 했다. 이 Objective는 Column 표현을 학습하기 위해서 채택한 방법인데, 인공적으로 생성된 합성 질문과 실제 테이블의 Column들 간의 관계를 정의하고 각 Column들이 어떤 관계를 가지는지를 예측하도록 하는 태스크이다. 위의 그림을 이용해서 자세히 설명하면 각 Column에 해당하는 </s> 토큰의 표현 벡터를 입력으로 해서 해당 Column이 질문과 어떤 관계에 해당하는지를 예측하도록 하는 태스크이다. 분류 해야하는 클래스의 갯수는 254개라고 하며, 논문에는 정확하게 표현이 되어 있지 않아서 254개의 클래스가 각각 어떤 의미를 가지는지 정확하게 알 수는 없지만, 추측을 해보면 “Show the student id more than 6 class”라는 질문이 만들어졌을 때 “student”라는 클래스는 뭔가 Select를 해야하는 Column에 해당하므로 그에 맞는 클래스가 부여가 될 것이고, class는 대소 비교를 하는데에 사용하는 Column으로 그에 맞는 클래스가 부여가 될 것으로 생각된다.
정리를 하자면, 이 논문에서는 컴파일러에서 사용했던 방법인 Context-free Grammar를 이용해서 인공적으로 자연어 쿼리를 생성하고 이를 이용해서 사전학습 데이터를 구축하고 사전학습에 활용하여 좋은 성능을 보이는 Table Pre-trained Language Model을 구축했다. 기존의 SQL 쿼리들을 분석해서 자주 쓰이는 SQL 유형들을 정리하고 각 SQL 구문은 어떤 자연어 구문과 연결되어야 하는지를 정의하는 템플릿을 생성하고 Context-free Grammar를 통해서 SQL 쿼리에 대응하는 인공적으로 생성된 자연어 쿼리를 생성하였다.
사전학습 방법은 기존의 TAPAS에서 사용했던 방법인 MaskLM 방법을 표 데이터에 적용하는 방법과 Column 표현 벡터를 입력받고 각 Column 벡터가 쿼리와 어떤 관계를 가지는지를 예측하는 SSP Objective를 추가하였다.
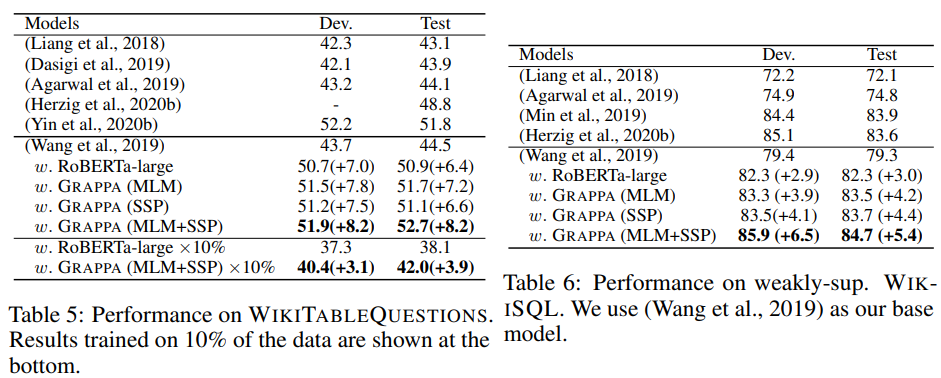
그림. Spider 데이터 외에 다른 Table Parsing 데이터에서의 성능
Spider 데이터를 분석하여 만든 템플릿을 기반으로 인공적인 데이터를 생성하였지만, WikSQL, WikiTQ와 같이 다른 데이터셋에서도 사전학습의 효과가 있었기 때문에 특정 데이터를 기반으로 인공적인 데이터를 만들었음에도 일반화가 잘 되었다고 한다.
표 데이터에 관한 적절한 Statement나 태깅된 쿼리 데이터는 영어 데이터에서도 많이 존재하지 않아서 사전학습에 필요한 적절한 데이터를 대량으로 얻는 것이 힘들 수 있다. 하지만 표는 자연어에 비해서 구조화되어 있는 데이터이므로 인공적인 쿼리를 생성하기에 훨씬 유리하다. 그렇기에 이전 Intermediate-Pretraining 연구와 같이 인공적으로 생성한 데이터를 사전학습에 이용하는 연구들이 많이 등장하고 있으며, 이 연구도 그 중 하나라고 볼 수 있다.
What is meant by GraPPa in the context of tabular data processing and how is the SCFG method used to generate synthetic data?
Regard IT Telkom
GraPPa is used to generate representation vectors that better reflect the structural information of rows and columns through pre-training with synthesized data.
SCFGs are used to process synthetic data, setting up the appropriate syntax and rules and generating synthetic data that conforms to those rules.