이번 논문에서는 Dense Table Retrieval에 관한 3가지 논문을 연결해서 같이 리뷰를 해보려고 한다.
“Open Domain Question Answering over Tables via Dense Retrieval ”
“Bridge the Gap between Language models and Tabular Understanding”
“Enhancing Open-Domain Table Question Answering via Syntax- and Structure-aware Dense Retrieval ”
우선 Dense Retrieval에 대해서 간단하게 설명을 하면 BERT와 같은 사전학습 언어모형을 인코더로 사용하는 일종의 검색 태스크라고 볼 수 있다. 우리가 어떤 질문을 입력하고 답이 포함되어 있는 문서 더미가 있다고 가정했을 때, 인코더 모델에 “질문 + 문서”를 쌍으로 입력을 하면 질문이 바뀔 때 마다 문서 더미에 있는 문서의 개수 만큼의 입력을 매번 처리해야 한다. 그렇게 되면 문서 백 만개가 있다고 가정하면 질문이 바뀔 때 마다 백만 개의 문서에 해당하는 입력을 처리해야 하기 때문에 너무나 오랜 처리 시간이 걸리게 된다.
Dense Retrieval는 이러한 문제를 해결하기 위해서 문서와 질문을 별개로 각각 입력을 하여 질문을 표현하는 대표 벡터를 생성하고, 문서를 생성하는 대표 벡터를 생성한다. 그리고 모델을 학습할 때 서로 관련이 있는 Postivie한 데이터가 같이 입력되면 두 벡터가 Cosine Similarity가 가까워지게 학습을 하고, Negative한 데이터의 벡터끼리는 서로 멀어지게 학습을 한다. 이렇게 되면 몇 백만 개의 문서를 처리해야 하더라도 인코더로 미리 문서 벡터들을 만들어두고 Locality Sensitive Hashing와 같은 기법을 적용하여 빠르게 고속으로 비슷한 모양을 가지는 벡터를 탐색하여 마치 검색하는 것과 같이 실시간으로 구현 가능한 속도로 원하는 문서를 찾는 모델을 구현할 수 있다.
Table Dense Retrieval는 이러한 태스크를 Table 데이터에 적용해서 테이블을 검색하는 모델을 구현한 연구들이며, 해당 분야의 논문 3가지를 시간순으로 정리해보려고 한다.
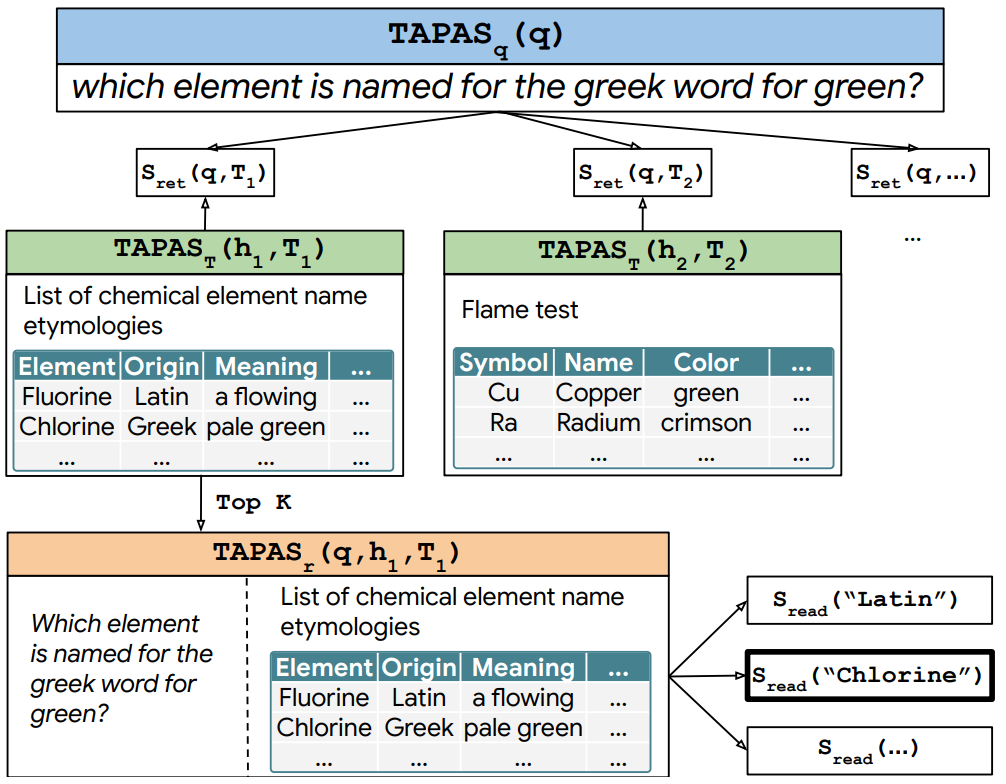
그림. Table Dense Retrieval를 이용한 Open-Domain Table QA 태스크 구조
첫번째 논문은 “Open Domain Question Answering over Tables via Dense Retrieval “이다. 이 논문은 Table Dense Retrieval을 실험한 시작 논문이라고 볼 수 있다. 본 논문은 “Dense Passage Retrieval for Open-Domain Question Answering”에서 제안했던 방법론에 TAPAS를 적용한 실험에 관한 내용을 서술하였다.
“[CLS] 테이블”, “[CLS] 질문”의 데이터를 입력하고 [CLS] 토큰의 표현 벡터를 비교하여 가장 유사한 벡터를 가지는 테이블이 검색되는 방식이다.
![]()
이전 논문과 같이 두 벡터 간의 Dot Product를 이용해서 Similiarity를 계산했다.
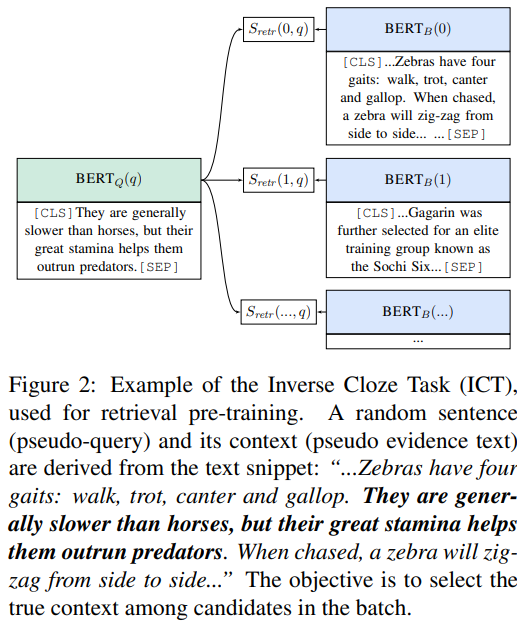
그림. Inverse Cloze Task 설명
Retireval 태스크에서 성능을 높이기 위해서 사전학습된 TAPAS 모델에 Inverse Cloze Task(ICT)를 이용하는 사전학습 방법을 추가했다. ICT 사전학습 방법은 “Latent Retrieval for Weakly Supervised Open Domain Question Answering”에서 제안된 방법이다. 이 방법의 기반이 되는 Standard Cloze Task에서는 어떤 Context에서 Masked-out 된 문장을 예측하였는데, ICT에서는 반대로 적용하여 어떤 문장이 주어지면 그걸 기반으로 Context를 예측하는 방법이다. 예를 들어 어떤 Context가 “A 부분. B 부분”이라고 할 때 A 부분이 주어지면 B 부분에 해당하는 Context를 예측하는 태스크이다. 이와 유사하게 본 논문에서는 어떤 텍스트 Span들 S에 가깝게 나타나는 테이블 T를 가지고 ICT 태스크를 구성하였다.
방법론에 관한 부분은 기존의 방법에 인코더를 TAPAS로 변경한 부분만 존재하기 때문에 이 글에서는 크게 설명할 부분이 없지만 집고 넘어가야할 부분은 데이터셋 관련 부분이다. Table Question Answering에서는 Open-Domain 관련 데이터셋이 존재하지 않는데 NQ(Natural Questions)라는 텍스트 문서를 기반으로 하는 Question Answering 데이터셋을 변형하여 만든 NQ-Tables 데이터셋을 학습 및 평가에 이용하였다.
다음으로 Hard Negatives 방법을 적용했는데, 가장 먼저 학습된 Initial 모델을 통해서 추출하도록 한 유사한 테이블 후보 C를 학습에 이용하는 방법이다. 이 후보 테이블 안에서 정답을 포함하고 있는 후보들을 제거하고 남은 후보 테이블들 중에서 가장 높은 유사도를 가지는 테이블을 Hard Negative 데이터로 활용하였다. 이렇게 되면 기존 학습셋에는 “Query, Positive Table”의 Pair를 이용하였는데 Hard Negative 데이터가 추가되어 “Query, Positive Table, Hard Negative Table”의 데이터가 학습에 이용된다.
NQ는 구글 검색에 사용된 약 32만 개의 질의를 기반으로 만든 데이터셋인데, 위키피디아 문서에서 이 질문의 답에 해당하는 Span을 태깅한 데이터셋이다. 이 데이터셋에서 사용된 대부분의 질문들은 텍스트 단락에만 정답이 존재하지만 간혹 질문에 대한 정답이 표 데이터에도 존재하는 질의들을 발견할 수 있었으며, 이러한 질문들 1.2만개를 테이블 데이터에 다시 태깅하여 표를 위한 질의응답 셋으로 만든 데이터셋이 NQ-Tables 데이터셋이다.
요약하자면 이 논문은 기존의 Text 데이터에서 진행되었던 Dense Retrieval 연구를 Table에 맞게 적용한 연구라고 볼 수 있다. 또한 텍스트에 맞게 설계된 NQ 데이터셋을 테이블에 맞게 개량한 NQ-Tables 데이터셋을 공개한 것도 의미가 크다고 생각한다.
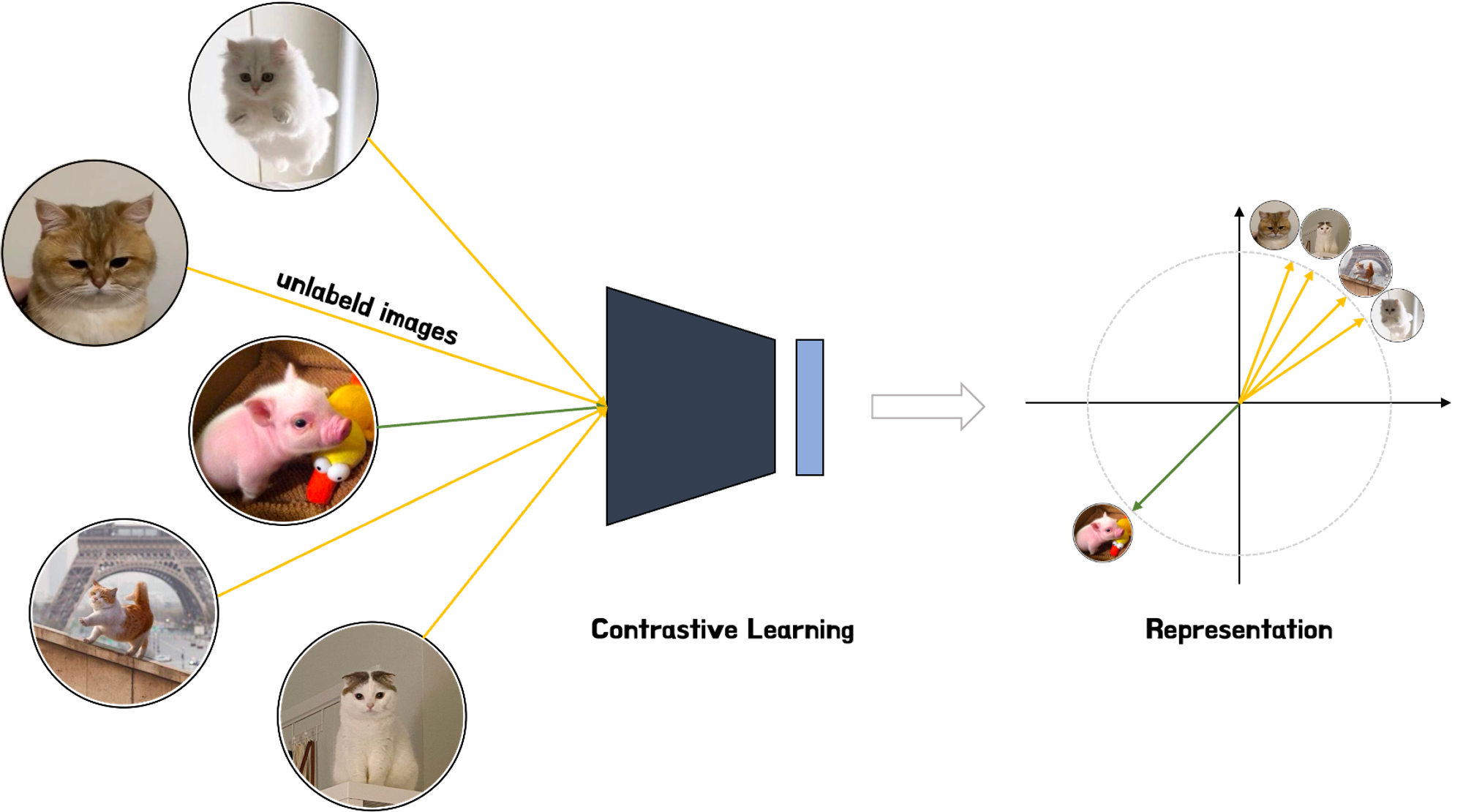
그림. 이미지 데이터에서의 Contrastive Learning 예시: 같은 고양이 이미지끼리는 가깝게, 다른 이미지인 고양이과 돼지 이미지끼리는 멀게 나타나는 Representation을 학습시키는 것
다음으로 살펴볼 논문은 “Bridge the Gap between Language models and Tabular Understanding”이다. 이 논문을 설명하기에 앞서서 배경으로 “Contrastive Learning”을 간단하게 설명하고자 한다. Word2Vec과 같은 기법들은 어떤 단어를 표현할 때 컴퓨터가 우리와 유사한 방식으로 해석할 수 있도록 해당 단어의 특징이 포함된 표현 벡터를 생성하는 작업이라고 볼 수 있다. 이러한 연구를 “Representation Learning”이라고 하는데 Contrastive Learning은 이러한 Representation을 잘 생성할 수 있도록 하기 위한 Self-Supervised 태스크 중 하나라고 볼 수 있다. 이 Contrastive Learning은 지금부터 설명할 논문의 사전학습 태스크에서 활용되었다.
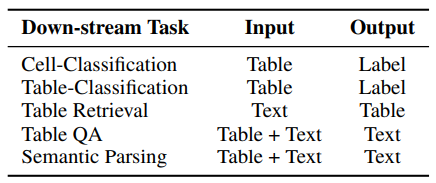
그림. 테이블 관련 Down-stream Task
테이블 데이터를 사용하는 태스크는 여러 가지가 존재하는데 테이블 데이터만 입력되는 것이 아니라 텍스트도 같이 입력되는 경우가 많으며 태스크에 따라서 [“Table, Text”, “Table, Label”, “Text, Table”] 등 다양한 형태의 입력 데이터가 사용된다. 이러한 이유로 사전학습 과정에서의 입력 데이터 형식과 파인튜닝 과정에서의 입력 데이터 형식의 차이가 발생하게 되며 이로 인해서 사전학습 과정과 파인튜닝 과정 사이의 “Gap”이 발생하게 된다. 예를 들어 사전학습 태스크에서는 “Table + Text” 형식의 입력 데이터가 사용되었지만 파인 튜닝 과정에서는 “Text”를 입력하고 Table을 찾는 태스크가 적용된다면 사전학습에서 학습된 지식들은 별로 유용하지 않을 수 있다. 이 논문에서는 이러한 사전학습과 파인튜닝 과정에서의 차이를 극복하고 다양한 타입의 입력에 잘 적용할 수 있는 UTP(Universal Table-text Pre-training) 방법을 제안했다.
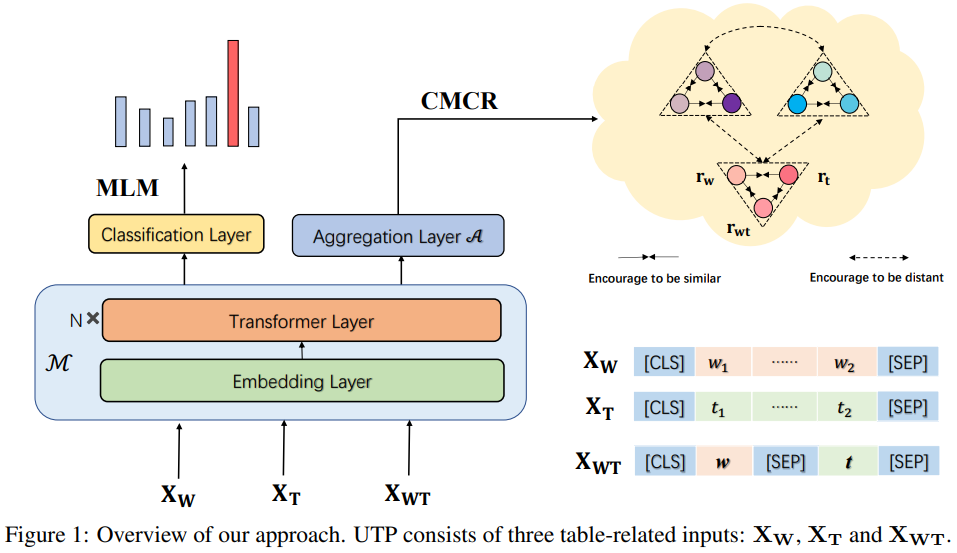
그림. UTP 모델의 아키텍쳐
UTP는 크게 2개의 과정으로 사전학습이 진행된다. 첫번째는 UMLM(Universal Masked Language Modeling), 두 번째는 CMCR(Cross-Modal Contrastive Regularization)이다. 인코더 모델의 아키텍쳐는 TAPAS와 동일한 모델을 이용하였다.
Universal MLM은 TAPAS와 같이 15%의 토큰을 마스킹하고 원본 토큰을 예측하는 태스크를 적용하는 태스크이다. 여기서 기존에는 “[CLS] Sentence [SEP] Table [SEP]”의 Text + Table 형식의 입력 데이터가 사용되었는데, 여기서는 w=”[CLS] Sentence [SEP]”, t=”[CLS] Table [SEP]”, wt=”[CLS] Sentence [SEP] Table [SEP]”의 3가지 형식의 입력 데이터를 사전학습에 이용하였다.
CMCR은 텍스트 시퀀스와 테이블 시퀀스 간의 Alignment를 위해서 적용되는 태스크인데 서로 관련이 있는 Text와 Table 데이터를 같은 Semantic Space에 존재할 수 있도록 하기 위한 사전학습 태스크이다. UMLM에서 사용하였던 3가지 형식의 입력 데이터가 입력되었을 때 Contrastive에서 Positive한 데이터인 “w, t, wt”의 트리플 데이터를 얻을 수 있다. 인코더로 인코딩을 하게 되면 다음과 같은 히든 벡터들을 구할 수 있다.
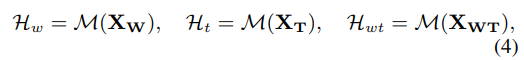
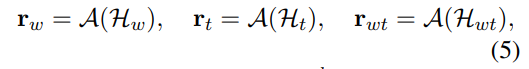
여기에 Mean Pooling과 같은 방법으로 Aggregation Layer를 적용해서 각 입력의 Semantic Representation을 구한다. 구해진 r 벡터의 Positive한 데이터끼리는 Latent Space 상에서 가까워지도록 학습을 하게 되고, Negative한 데이터끼리는 멀어지도록 학습을 하는 Contrastive Learning Loss를 추가해서 MLM Loss와 함께 2가지 Loss를 최소화하도록 사전학습을 하게 된다.
CMCR 사전학습 태스크를 적용했을 때 WikiSQL과 같이 Table Parsing 태스크에서도 향상된 결과를 보였지만, 특히 Contrastive Learning이 효과적으로 적용될 수 있는 Table Dense Retrieval 태스크에서 큰 성능 향상을 보였다.
마지막으로 살펴볼 논문은 “Enhancing Open-Domain Table Question Answering via Syntax- and Structure-aware Dense Retrieval “이다. UTP는 Table Retrieval 태스크에 적합한 사전학습 태스크를 제안했다면 이 논문은 Dense Retrieval을 위해서 Semantic Representation을 뽑아낼 때 표의 구조적인 정보와 질의의 Syntatic 정보를 잘 반영해서 적절하게 뽑아내는 방법을 서술하고 있다.
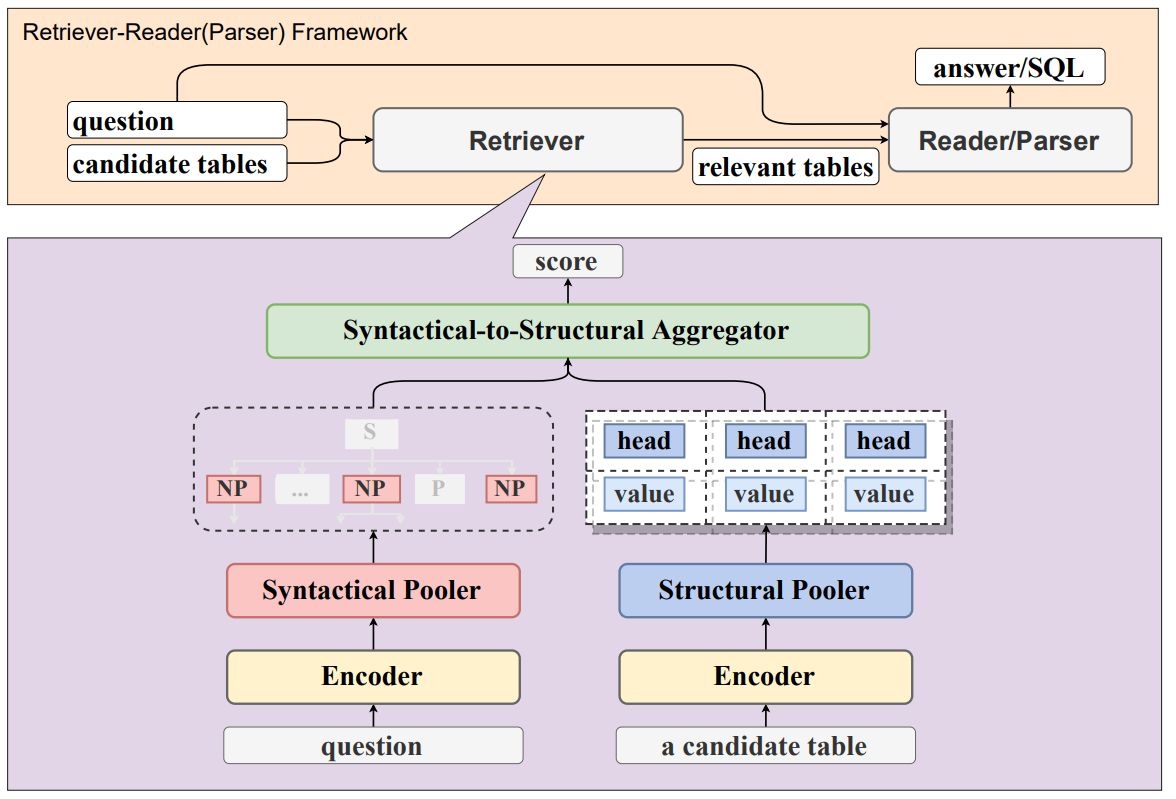
그림. Retrieval Model의 아키텍쳐
논문의 메소드는 크게 3가지 부분으로 나누어서 설명을 할 수 있다.
- Syntactical Question Representation
- Structural Table Representation
- Syntactical-to-Structural Aggregator
질의 표현 벡터를 뽑아내는 방법, 표의 표현 벡터를 뽑아내는 방법, 그리고 이 두가지 벡터를 적절하게 잘 조합해서 유사도를 구하는 방법에 관해서 설명하고 있다.
우선 Syntactical Question Representation은 질의에 있는 Syntactical한 구조를 잘 반영해서 표현 벡터를 생성하고자 하는 방법이다. 기존의 방법에서는 “[CLS] Query Tokens … [SEP]”의 형태로 입력을 하고 단순하게 [CLS]의 토큰 표현 벡터를 해당 쿼리의 Semantic 표현 벡터로 사용을 했었다. 이 논문에서는 Syntax Parser를 이용해서 문장의 구조를 반영한 표현 벡터를 생성하고자 하였다. NLTK 툴에서 제공하는 Syntax Parser를 이용하였으며, 우선 인코더 모델에 쿼리 토큰을 입력하여 각 토큰에 대한 히든 벡터를 구한다. 쿼리에 Syntax Parser를 적용하면 질문의 Phrase들을 얻을 수 있는데 Phrase 별로 Mean Pooling 연산을 수행해서 각 Phrase의 표현 벡터를 구했다.
다만 Syntax Parser를 이용했을 때, Parser의 실행 시간이 추가로 소요가 된다는 단점이 있다. 이 논문에서는 Syntax Parser를 이용하는 Explicit 방법 외에도 외부 툴을 사용하지 않는 Implicit 방법도 같이 제안하고 있다. Implicit Query Representation 방법은 Attentive Learning Mechanism을 이용하는 것인데, 랜덤하게 초기화된 Learning Embedding을 생성하고 각 임베딩과 히든 벡터를 곱해서 어떤 임베딩 벡터별로 Attention Scalar를 구한다. 그리고 이를 기반으로 합산하여 인공적으로 나누어진 Phrase를 기반으로 Pooling을 적용한 대신 각 임베딩 벡터별로 어텐션을 구하고 합산한 Phrase Representation을 사용하는 것이다.
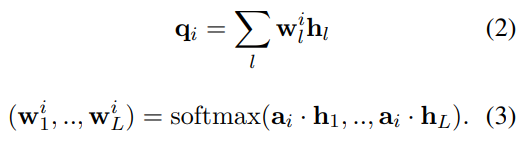
식에서 a는 랜덤하게 초기화된 임베딩 벡터를 나타내며 수식에서는  와 같이 표현된다. Syntax Parser의 경우로 비유하면 Phrase의 개수로 나타낼 수 있다. 3번 수식을 살펴보면 히든 벡터를 각 임베딩 벡터와 곱해서 토큰 중에 어떤 토큰들이 임베딩 벡터와 유사한지를 계산하게 된다. 그리고 각 임베딩 벡터별로 유사한 부분들을 가중치를 높게 줘서 Pooling을 하게 되는데 만약에 이 임베딩 벡터의 유사한 부분이 Phrase별로 나타난다면 Phrase 별로 Pooling 하는 것과 비슷한 효과를 낼 수 있다.
와 같이 표현된다. Syntax Parser의 경우로 비유하면 Phrase의 개수로 나타낼 수 있다. 3번 수식을 살펴보면 히든 벡터를 각 임베딩 벡터와 곱해서 토큰 중에 어떤 토큰들이 임베딩 벡터와 유사한지를 계산하게 된다. 그리고 각 임베딩 벡터별로 유사한 부분들을 가중치를 높게 줘서 Pooling을 하게 되는데 만약에 이 임베딩 벡터의 유사한 부분이 Phrase별로 나타난다면 Phrase 별로 Pooling 하는 것과 비슷한 효과를 낼 수 있다.
다음으로 Structural Table Representation에 대해서 설명하겠다. 그림을 보면 Structural Pooler를 거치면 Head Representation, 그리고 해당 Head의 Value Representation이 생성되어 있는 것을 확인할 수 있다.
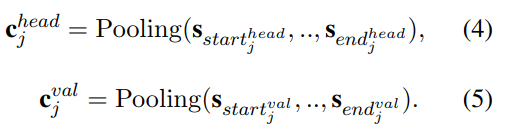
수식과 같이 Column의 Head, 그리고 각 Column의 Value 별로 Pooling을 하는것을 확인할 수 있다.
여기까지의 과정을 정리하면, 각 Phrase들의 Query Representaion ![]() 그리고 각 Column의 Head
그리고 각 Column의 Head ![]() , Value Representation
, Value Representation ![]() 를 포함하는 Column Representation
를 포함하는 Column Representation ![]() 이 준비되었다. Syntactical-to-Structural Aggregator는 준비된 벡터들을 이용해서 Similiarity를 구하는 방법을 나타낸다. Query 벡터들과 Column 벡터들간의 유사도 계산은 ColBERT(“ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT”에서 적용되었던 MaxSim 연산을 이용하였다.
이 준비되었다. Syntactical-to-Structural Aggregator는 준비된 벡터들을 이용해서 Similiarity를 구하는 방법을 나타낸다. Query 벡터들과 Column 벡터들간의 유사도 계산은 ColBERT(“ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT”에서 적용되었던 MaxSim 연산을 이용하였다.
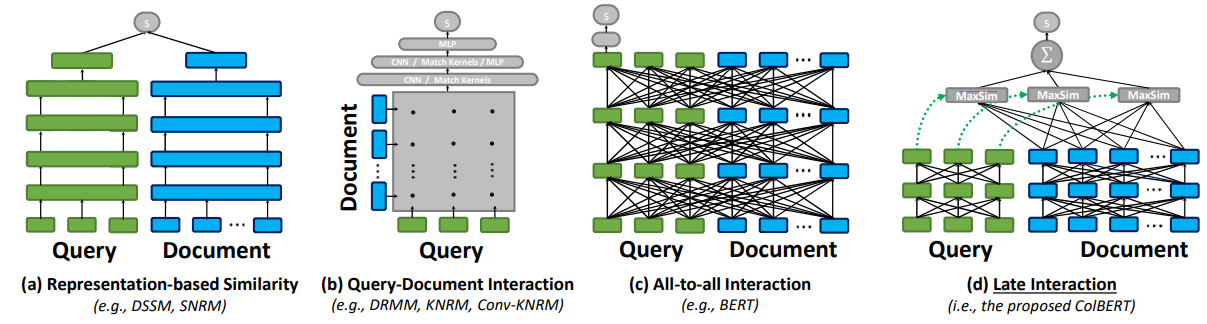
그림. Interaction 방법 비교(가장 오른쪽이 MaxSim을 이용한 방법)
각 쿼리의 벡터들과 가장 유사한 벡터를 가지는 벡터와 유사도를 구하고 각 쿼리 벡터에서 구해진 유사도를 전부 더해서 유사도 벡터를 구하는 방식이다. 원래 기존의 Dense Retrieval에서는 단일 쿼리 벡터와 단일 문서 벡터를 이용하지만 여기서는 쿼리 벡터와 문서 벡터가 토큰 갯수만큼 적용된다. 여기서는 비교해야할 토큰이 Phrase의 갯수, 그리고 Column 갯수 * 2개의 벡터를 이용하기 때문에 MaxSim 연산을 이용해서 유사도를 계산한다.
여기까지 Table Dense Retrieval 관련 논문 3가지를 연달아서 정리를 해보았다. 첫 번째 논문은 기존의 Dense Retrieval Task를 어떻게 테이블 데이터에 적용할 지를 서술하는 논문이었으며, 두 번째는 해당 태스크를 위한 사전학습 방법, 마지막 논문은 표나 질문의 정보를 잘 표현하기 위한 벡터 표현 방법을 나타낸 논문이다.