최근 테이블 파싱의 대표적인 벤치마크 중 하나인 WikiTQ의 상위권을 기록하고 있는 모델들 중에서 CABINET을 제외하고 대부분이 CODEX와 같은 대규모 언어모형을 이용하는 모델이다.
오늘은 이러한 LLM을 이용한 테이블 파싱 논문들을 소개하고 정리하고자 한다.
본 글에서 다루고 있는 논문들 목록은 다음과 같다.
- BINDING LANGUAGE MODELS IN SYMBOLIC LANGUAGES
- LEVER: Learning to Verify Language-to-Code Generation with Execution
- Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning
- Rethinking Tabular Data Understanding with Large Language Models
- CHAIN-OF-TABLE: EVOLVING TABLES IN THE REASONING CHAIN FOR TABLE UNDERSTANDING
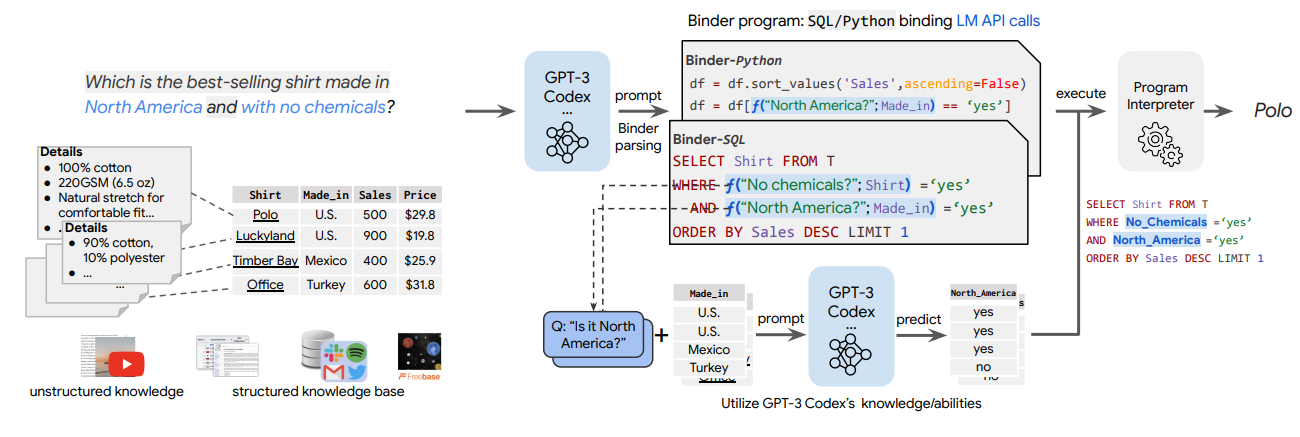
그림 1. BINDER 모델 구조
우선, 가장 첫번째로 소개할 모델은 BINDER 모델이다. 해당 모델은 CODEX를 이용한 In-Context Learning을 활용해서 테이블 파싱에 필요한 프로그래밍 언어(Python, SQL)를 생성하고, 외부 인터프리터에서 이를 통해 생성된 프로그램을 실행시켜서 질문에 대한 답을 얻는 방법이다.
BINDER의 태스크를 정의하면 질문 Q, 그리고 컨텍스트 데이터(텍스트 단락, 테이블, 이미지 등)를 입력받는다. 그리고 해당 데이터를 바탕으로 질문 Q에 대한 정답 A를 생성하게 된다.
BINDER의 프레임워크는 BINDER Parsing과 BINDER Execution의 두 가지 과정으로 이루어져 있다.
BINDER Parsing에서는 질문 Q를 입력하고 BINDER Program Z를 생성하게 된다. BINDER Program은 Symbolic Language로 표현되어 있는데, 해당 Symbolic Language만으로는 정답을 구할 수 없을 때, BINDER Progam에 API를 호출하는 함수도 포함될 수 있다. 예를 들어 위의 그림에서 “North Americal”라는 구절 Q^가 있을 때, 해당 Q^에 연관있는 Contexts D^는 표의 made_in Column이 된다. 그러면 LLM에서는 Q^에 대한 정답을 구하기 위한 API call 함수를 생성하고 f(Q^, D^)와 같이 정보를 입력하면 원하는 출력이 나오도록 하는 프로그램이 생성된다.
BINDER Execution 단계에서는 BINDER Interpreter를 통해서 이전 단계에서 생성했던 프로그램 Z를 실행시켜서 원하는 정답들을 얻게 된다. 실행 단계에서는 Lexical Analysis, Syntax Analysis, Program Evaluation의 과정이 포함되게 된다. Lexical, Syntax Analysis에서는 프로그램이 Abstact Syntax Tree 구조로 파싱되게 된다. API call의 Program Evaluation에서는 CODEX 모델을 통해서 실행된다. API Call의 출력 값들은 일반적인 프로그래밍 언어의 변수로 저장하도록 해서 Parsing 과정에서 생성된 다른 프로그램들과 결합되어 실행될 수 있도록 하였다.
API Call에서는 col 함수와 val 함수의 2가지 함수가 존재한다. col 함수는 위의 그림에서 North Americal에서 만든 제품인가를 판단하기 위해서 LLM에 made_in Column에서 North Americal에 해당하는지 아닌지를 판단한 Column을 만들어서 리턴하게 된다. col 함수에서는 col 변수를 리턴한 것과 같이, val 함수에서는 특정 값을 출력해야하는 경우 사용된다.
요약하자면, 해당 논문에서는 BINDER라는 프레임워크를 제안했다. BINDER는 Parsing 태스크와 Execution 태스크의 2가지 태스크로 이루어져 있다. Parsing 태스크에서는 실행가능한 Symbolic 언어를 생성하게 되며, 프로그램 언어 생성만으로 해결할 수 없는 부분들은 API Call 함수를 생성해서 LLM이 필요한 정보들을 찾아서 프로그래밍 언어의 변수 형태로 저장하도록 하였다. (예를 들어, 그림 1에서 ‘made in U.S.인 제품’은 조건식으로 ‘U.S.’를 만들어주면 손쉽게 찾을 수 있지만, America를 이용해서 U.S.를 찾는 것과 같은 경우 API Call이 필요하다. Execution에서는 이전 단계에서 만들어진 프로그램을 실행하여 최종 정답을 얻게 된다.
다음으로 살펴볼 논문은 “LEVER: Learning to Verify Language-to-Code Generation with Execution “이다.
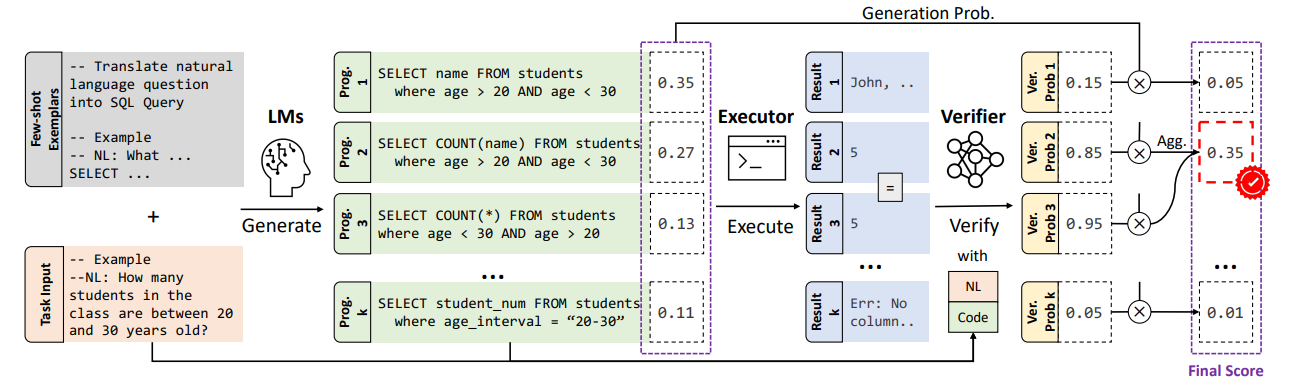
그림 2. LEVER의 구조
그림 2는 LEVER의 전체적인 구조를 나타낸다. LEVER에서는 program-to-code 생성을 이용해서 Semantic Parsing을 하였다.
LEVER가 실행되는 과정은 다음과 같다. 우선, Codex와 같은 LLM을 이용해서 프로그램들을 샘플링하여 여러개를 생성한다. 그리고 Executor를 통해서 생성된 프로그램의 생성 결과를 만든다. 그리고 Verifier 모델을 통해서 자연어 질문, 프로그램, 생성 결과를 입력하고 가장 정답일 확률이 높은 케이스를 선택하여 최종 정답으로 출력한다.
LEVER에서의 핵심적인 차이점은 Verifier를 이용해서 샘플링된 여러 케이스들을 Re-Ranking한다는 것이다. Re-Ranking 모델은 Binary-Classification을 하는 어떠한 구조의 모델이든 사용이 가능하며, 해당 논문에서는 T5와 RoBERTa를 실험에 이용하였다. 그림 2를 살펴보면 마지막 과정에서 Agg. 과정을 거쳐서 확률이 바뀌는 것을 볼 수 있는데, 이는 같은 결과를 출력하는 케이스의 확률을 Aggregate해서 생성되는 프로그램이 특정 형태를 가지는 의존성을 낮추고 결과 자체에 집중할 수 있도록 하기 위함이다. Aggregation은 다음과 같이 계산된다.
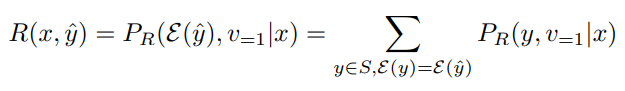
LEVEL에서의 차이점은 샘플링을 통해서 여러개의 프로그램들을 생성하도록 하였고, 해당 프로그램의 생성 결과를 테이블, 질문과 함께 Verifier에 입력하여 Re-Ranking하는 과정을 거쳤다는 점이다.
다음으로 살펴볼 논문은 “Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning”이다.
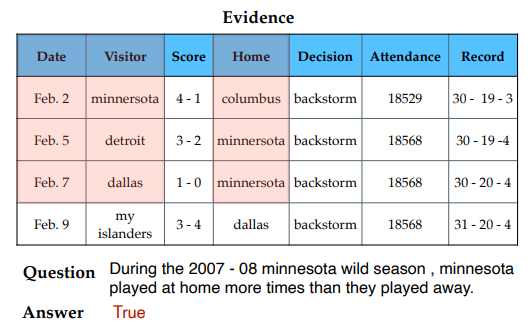
그림 3. 테이블 기반의 추론 예시
위의 그림 3은 질문에 대한 답을 하기 위해서 테이블 데이터에 대한 추론 과정을 나타낸다. 해당 논문의 핵심 아이디어는 Evidence(테이블)와 질문을 분해해서 테이블에 대한 추론 능력을 향상시키는 것이다. 그림 3의 추론 과정을 살펴보면 질문에 대한 답을 하기 위해서는 Header에서 필요한 부분인 Date, Visitor, Home을 선별하고, minesota가 포함된 데이터를 선별해야한다. 해당 논문에서는 이러한 추론 과정을 질문을 분해하고, 분해된 질문에 하나씩 답을 해가면서 추론을 하는 방법을 제안했다.
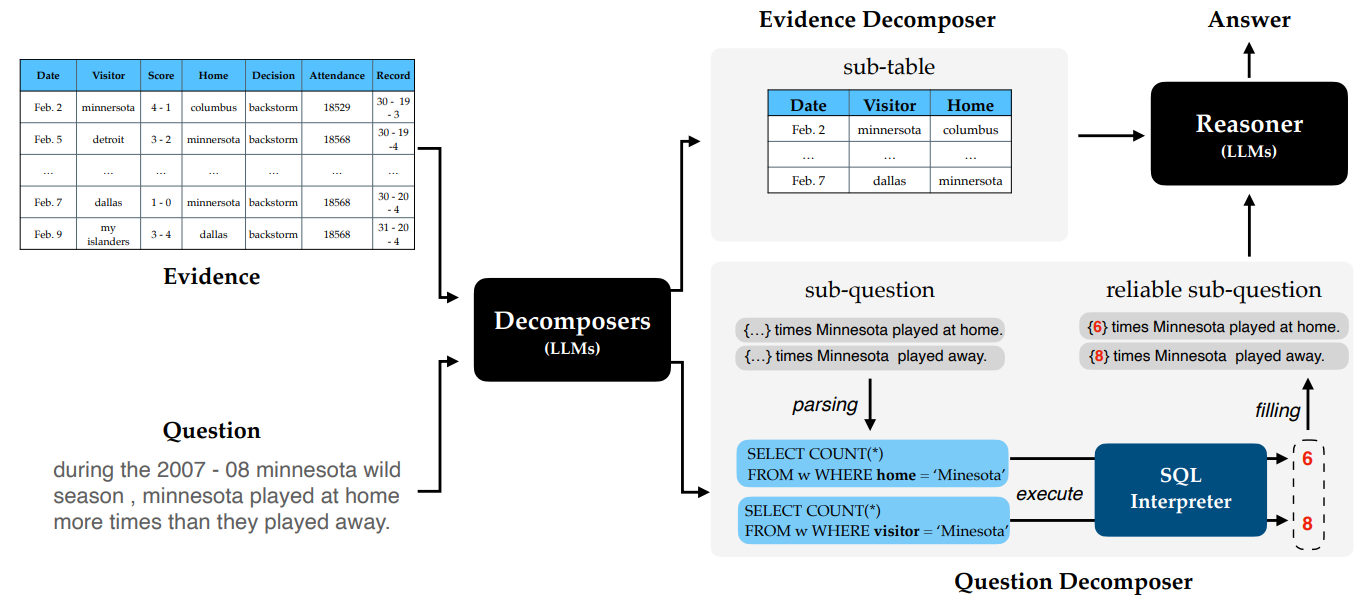
그림 4. DATER 모델 구조
그림 4는 해당 논문의 DATER 모델의 전체적인 구조를 나타낸다. Decomposer에서는 입력된 표와 질문을 분해해서 sub-table과 sub-question을 만들게 된다. sub-table는 질문의 답에 필요한 부분만 추출한 데이터이며, sub-question은 질문에 대한 답을 얻기 위한 추론 과정에 필요한 질문들을 분해해서 나타낸 것이다. 그림 4의 질문을 살펴보면 minesota 팀에서 홈으로 뛴 경기와 원정으로 뛴 경기 중 어떤 경기가 더 많았는지를 알아야한다. 그렇기 때문에 Decomposer는 홈으로 뛴 경기의 수를 구하는 sub-question과 원정으로 뛴 경기의 수를 구하는 sub-question으로 분해하게 된다. Parsing 과정에서는 분해된 각 질문 데이터를 입력해서 SQL Interpreter에서 실행할 수 있는 SQL 언어로 변환하게 된다. 마지막으로 SQL을 실행해서 얻은 단서들, sub-table을 모두 조합해서 Reasoner 모듈에서 최종 정답을 생성하게 된다.
Binding에서와 마찬가지로 DATER도 별도의 fine-tuning 과정을 거치지 않고 모델의 프롬프트 입력에 태스크 예시를 넣고 실행하는 in-context learning을 codex 모델에 적용했다.
해당 논문의 핵심 아이디어는 표 데이터를 필요한 부분만 선별하여 Sub-Question을 만드는 부분, 그리고 Query를 요구하는 조건이나 항목에 따라서 Sub-Question으로 나누어 처리한 것이다. 보통 Semantic Table Parsing에서는 “~한 데이터 중에서 ~한 조건을 가치는 ~ 데이터의 합”과 같이 여러 조건들이 결합되어 하나의 질문을 구성하고 있기 때문에 좋은 성능을 보인것으로 생각된다.
다음으로 살펴볼 논문은 “Rethinking Tabular Data Understanding with Large Language Models”이다. 이 논문에서는 비록 같은 내용을 담고 있더라도, 표의 구조적인 변화가 바뀌면 Semantic Parsing의 성능이 크게 떨어질 수 있다고 하였다. 그림 5는 이에 대한 예시를 나타내는데 Header는 보통 첫번째 Row에 존재하기 때문에 Header가 첫번째 Row에 존재하냐고 했을 때, LLM은 그렇다고 답변하게 된다. 하지만 다음과 같이 Transpose된 형태의 표가 입력되면 실제 입력 표 구조와 LLM이 생각한 내용에 차이가 생기게 되므로 오류가 발생하게 된다.
이에 해당 논문은 다음과 같은 문제들을 해결하기 위한 방법들을 제시하고 있다.
- LLM은 테이블 구조를 얼마나 잘 인지하고 있으며, 표 형태의 변화에 얼마나 강건한가?
- Textual Reasoning과 Symbolic Reasoning을 비교했을 때, 각각 어떤 장점과 한계점이 존재하는가?
- 추론을 위한 여러 단계의 과정은 표 데이터를 해석하는데에 도움이 되는가?
해당 논문에서는 이러한 질문들에 답을 하고 또한 표의 변화에 강건한 표 구조 Normalization 방법을 제안한다.
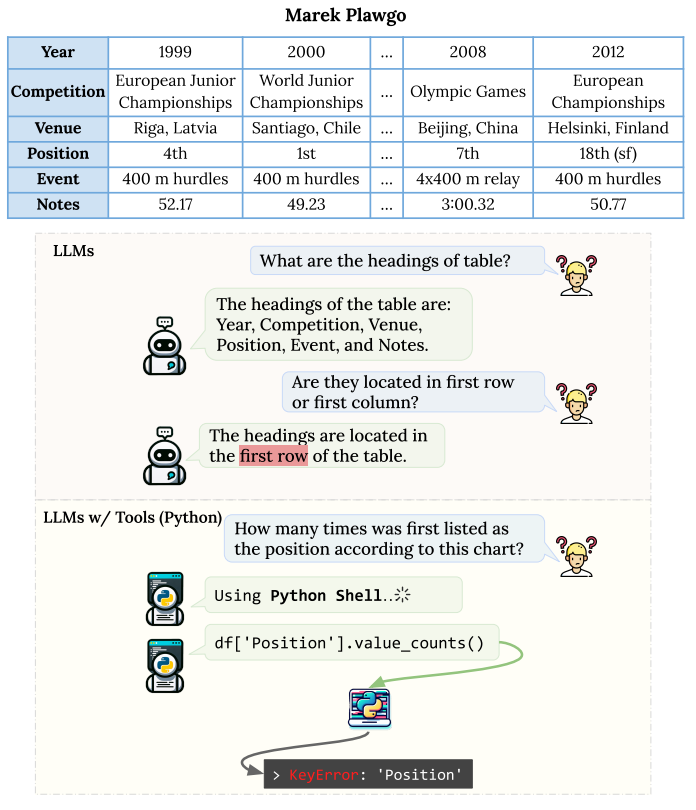
그림 5. LLM을 통해서 테이블 구조를 해석하고자 할 때 발생할 수 있는 어려운 문제들을 나타낸 예시
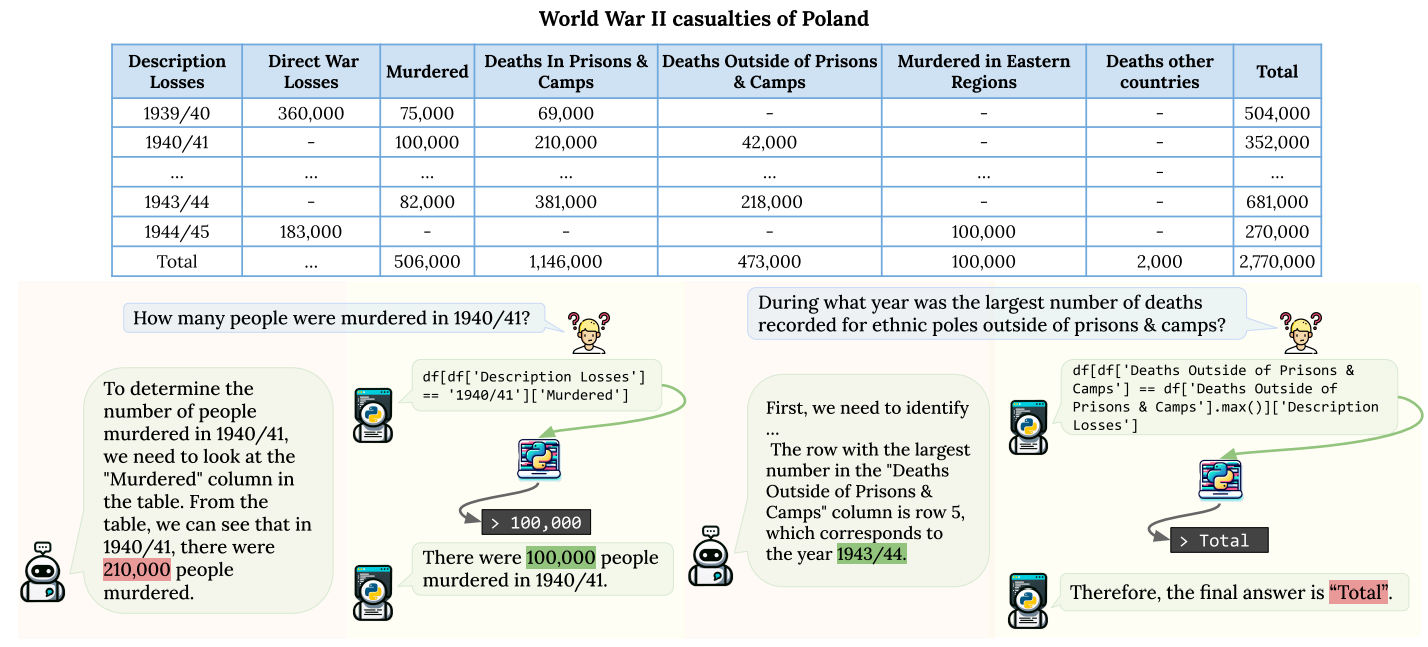
그림 6. WikiTQ의 데이터셋에서 하나의 예시를 가져와서 Direct Prompting과 Symbolic Reasoning 사이의 비교를 나타낸 것
그림 6은 WikiTQ의 한 데이터셋을 가지고 와서 LLM이 표 데이터를 이해하고 추론하는데에 존재하는 어려움들을 나타낸 예시이다. 첫번째 예시에서는 Symbolic Reasoning을 적용했을 때, 210,000으로 잘못 예측한 부분을 Symbolic Reasoning을 통해서 교정한 것으 확인할 수 있다. 두 번째 예시에서는 반대로 가장 높은 값을 가지는 Deaths Outside of Prisons & Camps를 찾는 문제이지만 맨 아래의 Row는 총합을 나타내고 해당 Row는 해당 질문에서는 정답에 포함이 되지 않아야 하지만 Symbolic Reasoning을 하게 되면 총합 값이 제일 클 수 밖에 없기 때문에 Total의 값이 무조건 정답으로 나오게 된다.
해당 논문에서는 실험을 위해 의도적으로 테이블 데이터에 Structural Variation을 주었는데, 이 때 3가지의 방법을 적용하였다.
- Transposed Table: 그림 5에서와 같이 테이블의 케이스로, 90도로 회전된 형태라고 볼 수 있다.
- Row Shuffled Table: Row의 순서가 완전히 뒤섞인 테이블 형태라고 볼 수 있다.
- Row Shuffled and Transposed Table
테이블 데이터에 대해서 추론을 하는 방법으로는 크게 2가지가 있는데 첫 번째는 zero-shot 방법으로 바로 직접적으로 정답을 생성하는 Direct Prompting 방법이고, 두 번째는 LLM이 필요할 때 유동적으로 Python Shell을 외부 툴로 호출해서 명령어를 실행하거나 데이터를 처리할 수 있도록 하는 방법이다. 이 때 Python Shell로는 pandas dataframe 같은 툴이 사용된다.

그림 7. WTQ의 테이블 데이터셋에 대해서 3가지의 태스크를 GPT-3.5로 평가해본 결과
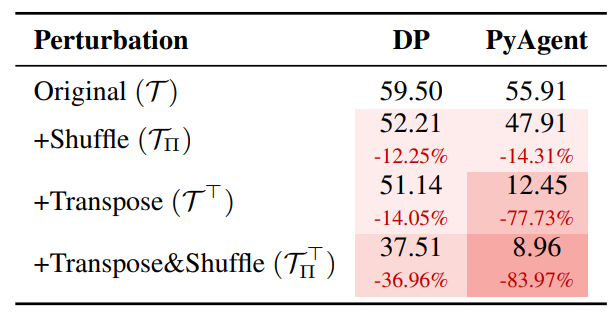
그림 8. GPT-.35의 각기 다른 Perbutation을 적용했을 때 DP, PyAgent 성능
그림 7은 WTQ의 데이터셋에 대해서 Transposer, Detector, Determinator의 3가지 태스크를 수행하고 성능을 평가한 결과이다. Transposer은 표 데이터를 Transpose하는 태스크, Detector는 Transpose가 필요한지 안 필요한지를 나타내는 태스크로 f(T)는 Transpose가 필요없는 경우, f(T^T)는 Transpose가 필요한 경우 잘 맞추는지를 평가한 것이다. Determinator는 표의 헤더 데이터가 첫번째 Column에 있는지 아니면 첫번째 Row에 있는지를 예측하는 태스크이다.
그림 8은 DP와 PyAgent 추론 방법을 적용할 때 각각 다른 Perbutation이 적용되었을 때의 성능 변화를 나타낸다. PyAgent 방법은 복잡한 연산을 필요로 할 때 필수적이지만(WikiTQ에서는 LLM으로 계산이 아예 불가능할 정도의 복잡한 계산이 필요한 유형은 드물다) Perbutation이 적용되어 평소와 다른 형태의 테이블이 입력되게 되면 성능이 드라마틱하게 떨어지는 것을 확인할 수 있다. 특히 Transpose에 굉장히 취약한 모습을 확인할 수 있는데 Dataframe에서는 입력되는 표의 형태에 따라서 명령어의 수행 결과가 완전히 뒤바뀌기 때문이다.
이러한 문제를 극복하기 위해서 해당 논문은 Table Structure Normalization을 적용하였다. 해당 방법은 입력되는 테이블이 Consistent Interpretation이 가능하고, 다양한 표 형태에도 적용이 가능하게끔 하는 방법이다. 테이블 Normalization을 하는 NORM 방법은 2개의 단계로 이루어져 있다. 첫번쨰 단계에서는 Column-tables을 예측하고, 두번째 단계에서는 해당 테이블들을 Transpose하여 첫번째 Row에 Header가 존재하는 Row Table로 변환하는 것이다.
다음으로는 표 데이터를 재순서화(Re-ordering)하여 입력하는 것이다. 다만, 표 데이터를 어떻게 재순서화하는 것이 정답인지는 알려진 규칙이나 이론이 없기 때문에 해당 논문에서는 Downstream 태스크에 다양한 Re-ordering 방법을 적용해보는 방법을 적용했다.
해당 논문에서는 DP와 PyAgent를 이용한 추론 방법을 비교하였다. 에러 분석을 통해서 각 추론 방법의 약점을 파악하기 위해서 50개의 에러가 난 데이터들을 선별하여 각 기법에서 어떤 타입의 에러가 났는지를 분석하였다. DP 메소드에서는 42%의 에러가 수치를 비교를 하는 문제였다. PyAgent에서는 38%의 에러가 코딩 에러로 인한 에러였다. 이러한 코딩 에러는 대부분 표 데이터를 잘못 이해한 것으로 인해서 발생한 것이었다. DP 접근법이 대부분의 유형에서 더 우수했지만, 그럼에도 ㅂ루구하고 PyAgent를 이용한 접근 방법은 더 큰 테이블들을 다룰 수 있는 장점이 있었다. DP는 표의 수치를 정확하게 해석하는데에 한계가 있었고, PyAgent는 생성된 코딩 값들이 안정적이지 못하다는 한계점이 있었다.
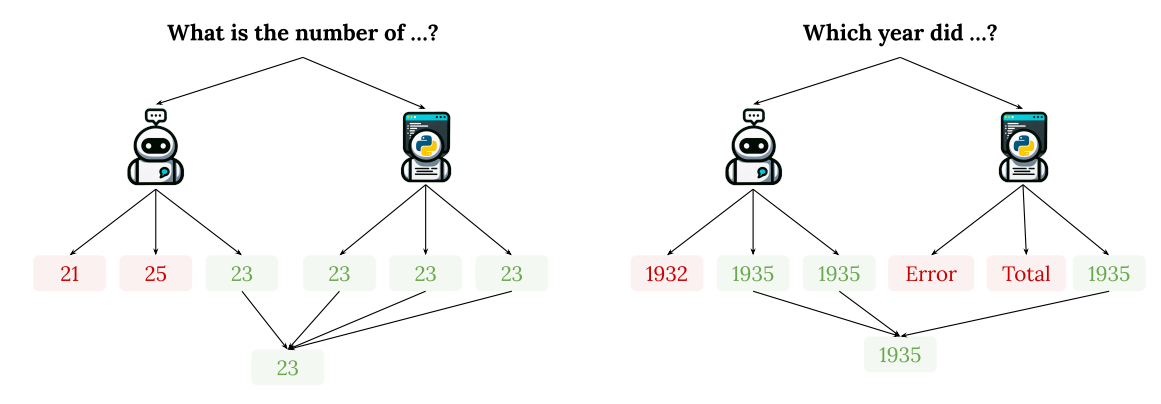
그림 9. Mix Self-Consistency 방법 예시
마지막으로 답을 생성하기 위한 방법으로 Self-Consistency[여러 개의 출력값들을 생성하도록 하고 가장 빈도수가 높은 출력값을 채택]를 응용한 Mix-Consistency 방법을 제안했다. 해당 방법은 입력된 질문에 따라서 LLM이 미리 정의된 개수의 출력값들을 생성하도록 하는 것이다. 생성된 출력값들의 갯수는 LLM의 정답에 대한 Confidence Level을 나타낸다. LLM의 정답이 Proficient하지 못한 경우에는 다양한 정답을 생성하려고 할 것이고, 반대로, 정답을 잘 생성할 수 있는 태스크에서는 딱 정해진 하나의 답이 생성될 가능성이 높다. 이러한 방법을 통해서 모델의 출력 값들을 통합하고 결합하여 더 강한 추론 능력을 가질 수 있다. 처음에는 Self-Consistency랑 어떤게 다른가 하고 헷갈렸었는데, Mix Self-Consistency에서는 DP와 PyAgent의 각기 다른 방법들에서 샘플링한 값들을 이용해서 Self-Consistency를 적용하는게 차이점인 것 같았다.
마지막으로 살펴볼 논문은 “Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding”이다.
Chain-of-Thought는 많은 Reasoning이 필요한 태스크에서 우수한 성능을 보여줬다. COT를 이용해서 표와 테이블 컨텍스트에 대한 Reasoning Chain을 구성하여 정답을 추출하는 것은 표 중심의 Reasoning 태스크에서 필요한 데이터를 추출하고 추출된 데이터를 기반으로 최종 정답을 추출해나가는 과정에 적합하다고 볼 수 있다. 하지만 그럼에도 불구하고 COT는 여전히 표의 데이터를 효율적으로 이용하고 있지 못하다고 하였다. 이에 저자는 COT를 표에 맞게 개선한 Chain-Of-Table 모델을 제안하였다. 아래는 모델의 전체적인 구조를 나타낸다.
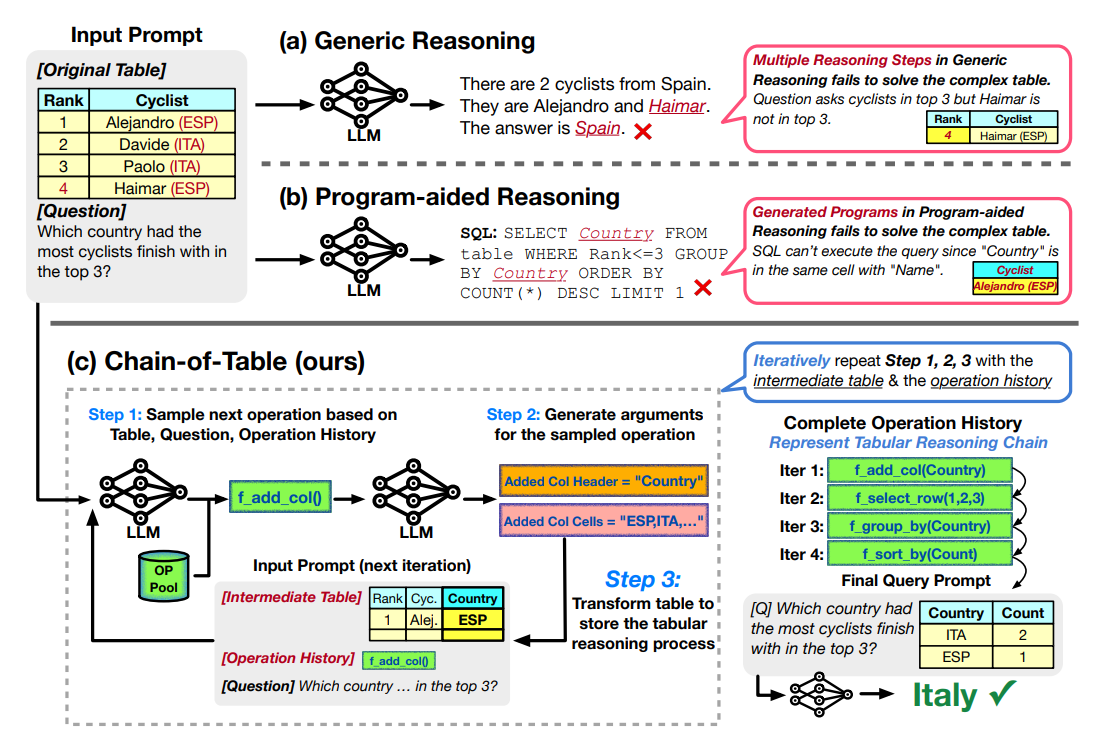
그림 10. 기존 모델과의 비교 및 Chain-of-Table 모델의 전체적인 구조
기존의 방법에서 Generic한 Reasoning을 이용할 때는 표의 복잡한 구조와 복잡한 값들을 비교 및 연산해야하는 경우, 성능이 저조하게 나타날 수 있다. 답을 생성하기 위한 SQL을 생성하는 등 프로그램 언어를 이용한 방법은 SQL 언어를 이용해서 유연하게 데이터를 탐색하거나 선별하는 것이 불가능하다. 예를 들면 질의응답에 사용해야 하는 표의 형태는 다양하며, 한 Column 내에 2가지 섹션으로 나누어져서 헤더가 2개가 존재하는 경우, SQL에서는 표를 분리하는 등의 처리를 해주지 않으면 이러한 형식의 표를 유연하게 처리하는 것이 불가능하다.
Chain-Of-Table은 Generic Reasoning의 유연함을 가지고 가면서 Program-aid Reasoning에서 가능한 복잡한 값과 연산을 처리할 수 있도록 결합한 형태라고 볼 수 있다. 그림을 통해서 COT의 과정을 살펴보면, 표와 텍스트 그리고 이전 기록 등을 이용해서 다음 정답 도출 과정에 필요한 Operation을 생성한다. Step 2에서는 생성된 Operation에 적합한 매개변수들을 추가하여 명령어를 수행하도록 한다. Step 3에서는 Step 2에서 생성한 매개변수를 추가하여 완성한 명령어의 수행 결과를 Intermediate Table에 저장하여 정답의 도출 과정을 기록한다.
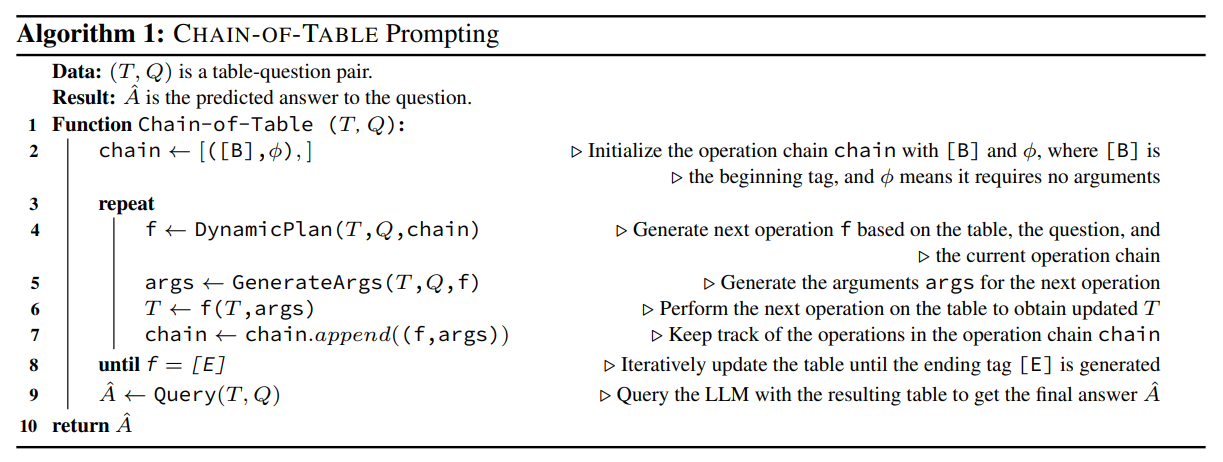
위의 그림은 COT의 정답 생성 과정을 나타낸 것이다. 매 iteration 마다 chain을 생성해서 저장하고, 저장된 chain과 입력을 참고해서 새로운 chain을 생성해나간다. 그리고 최종 End 토큰이 나타나면 해당 Chian에서 생성을 종료하고 생성된 최종 정답을 출력한다.
여기까지 LLM을 이용한 Table Parsing 모델을 살펴보았다. 기존의 Table Parsing에서는 보통 Encoder-Decoder 모델 혹은 Encoder 모델을 이용해서 모델의 정답을 직접적으로 생성하는 방식의 방법들이 대부분 채택되었다. 하지만 LLM을 이용한 Table Parsing에서는 정답에 필요한 단서들을 추출하는 중간 단계를 거치고, 추출된 중간 단계의 단서들을 기반으로 정답 생성에 필요한 명령어를 생성하거나 혹은 코드를 생성하는 방식이 채택된 것을 확인할 수 있었다. 중간 단계를 거쳐서 코드를 통해서 정답을 생성하는 방식은 값이 아무리 복잡하고 연산의 단계가 복잡하더라도 외부 Executer를 이용해서 실행할 수 있기 때문에 정확한 수행이 가능하다. 하지만 이전에는 생성 모델 자체에서 이렇게 복잡한 코드를 바로 생성할 수 있는 능력이 없었지만 LLM에서는 그러한 태스크의 수행이 가능해져서 이러한 변화가 생긴 것 같다.